Web Scraping the Phillips India website — Scraping the Headphone Category.
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--fHNKLAV0--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/8304/0%2A7ZI0nhI0bICoK6li)
Here I will scrape all the content on the Phillips website. And that content will be the Headphones category. The website is Phillips's India website.
Usually, web scraping is part of the Data Science/ Data Analyst job, which is the Data Generation or Data Aggregator.
Here we are going step by step approach, to how we do scraping the website, and the technology we are going to use is, Python, Selenium and Beautiful Soup.
First thing is that we are going to install some packages, which we type the certain command on cmd or anaconda prompt.
pip install lxml
pip install selenium
pip install beautifulsoup4
pip install pandas
pip install webdriver-manager
pip install regex


First, we are going to import the packages we required.
What I will do, I visit directly to that website which contains all the headphones and which contain all the types of headphones. So that is easy for us to try not to do much to automate the website.
I have mentioned below that how our website looks and you can visit to have look at how this website looks for you. https://www.philips.co.in/c-m-so/headphones/latest#

First, what we do will scrape all the data present inside the small container or we can say a small box. I am going to extract the Model number, Category name, and Overall Ratings.
Line number 19 on the above code is to collect the links of the product. By collecting the links of the product to visit the product website and to collect the data like technical specifications in detailed format.
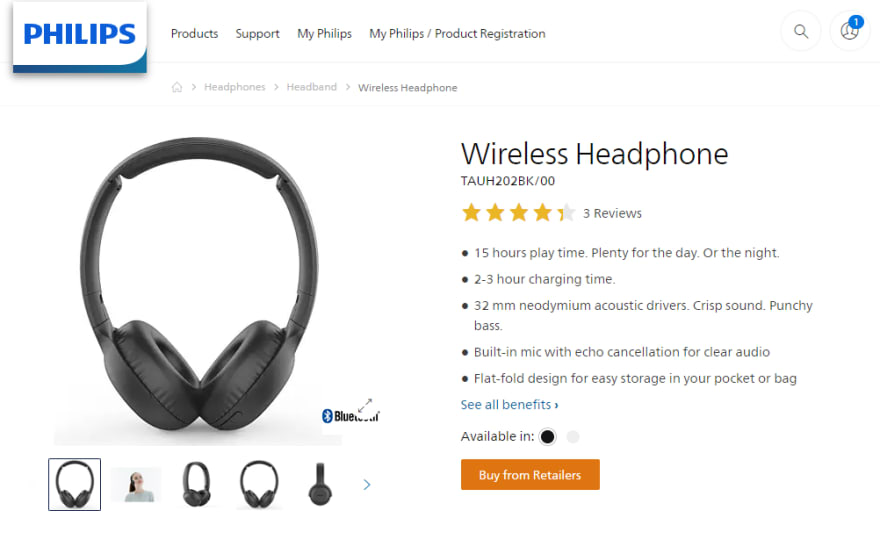



Now finally we scrape all the data, and end result is that we are going to save the data in CSV format.


Inside data look like the above image.
That file will be saved as “Final_Headphones.csv”
The entire code is shown below:
That’s all about scraping the data.
Thank you.




Top comments (1)
Hello, we want a article made by you, do you have any e-mail for contact you?