AWS S3 with python by Shoeb Ahmed
Amazon Web Services is an online platform that provides scalable and cost-effective cloud computing solutions.
Here we are going to explore all the methods (functions) present in boto3 packages, and we are going to S3 bucket resources.
And I am going to skip lots of theoretical concepts and jump step by step.
Make sure we have an AWS account and a root user.
Once you logged in, we just need an Access key to get a connection from AWS and python.
What we need to do, is go to the home console and see on the top right corner, click on your username as shown below:
After clicking the drop-down click on security credentials.

After clicking on security credentials, we will redirect to the security page, and click on the Access Keys.

After clicking the Access keys, click on “Create New Access Key”, and a pop-up window comes up, and click on “Download key files”.

Excel sheet file will be downloaded, what we have to do is that we are going to copy the AWS Access Key ID and AWS Secret Key ID.
My goal is to explore all the functions (methods) in S3 Bucket.
Let’s start coding.
And though I am going to do any task with Pandas DataFrame only. If you want any other file format, please go to my profile and find my email id and message me or write a comment.
After running the code you will observe that your new bucket is created in S3.
![]()
Now what we are going to do, we are going to upload the csv file in S3 bucket.
First we will create a simple DataFrame

![]()
Now we are going to upload a CSV file which is stored in the local system, without creating a folder inside the bucket.
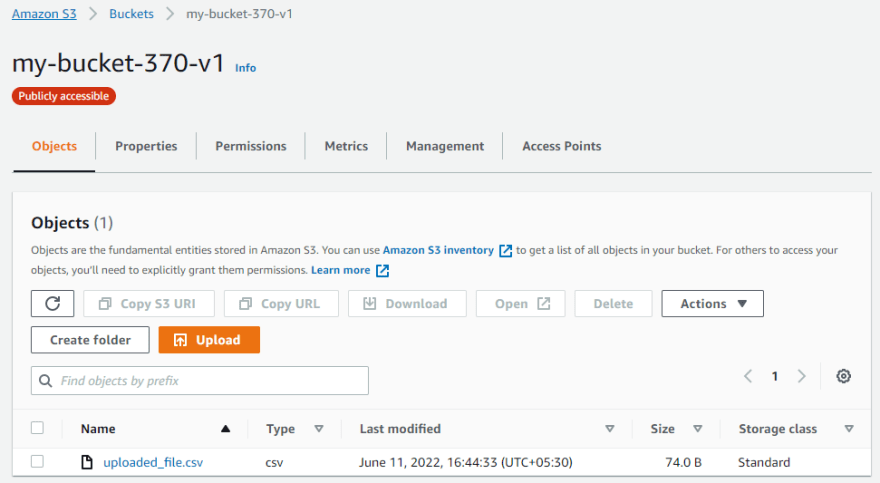
Now we are going to create a folder inside the bucket, inside that folder we are going to upload the code.

If you have a bytes-like file (i.e. binary file) or stream file so we can use uploadfileobj functions.

We can also upload by using the PutObject request, you must have the s3:PutObject in your IAM permissions.






Top comments (0)