Foreign Data Wrappers (FDWs) enable PostgreSQL to access data from external databases, offering various benefits such as integrating data from different sources or offloading processing to a separate database. FDWs are implemented as shared libraries that PostgreSQL loads, providing a standardized interface for accessing data from diverse databases. This allows PostgreSQL to treat data from different sources uniformly.
One widely used FDW is postgres_fdw, developed and maintained by the PostgreSQL Global Development Group. It empowers PostgreSQL to access data from remote PostgreSQL servers. When creating a postgres_fdw foreign table, PostgreSQL generates a local copy of the remote table's schema, enabling seamless interaction as if the foreign table were local. Queries involving foreign tables are processed similarly to local tables, but PostgreSQL sends the query to the remote server for execution and subsequently processes the returned results.
PostgreSQL leverages the capabilities of postgres_fdw to optimize the efficiency of queries referencing foreign tables. For instance, it can reduce the data transfer between servers by utilizing postgres_fdw to push down predicates to the remote server. By doing so, the quantity of data exchanged can be minimized. Queries referencing foreign tables undergo processing by PostgreSQL, which dispatches them to the remote server for execution, receives the results, and performs further processing.
postgres_fdw provides several features to enhance query performance when accessing data from remote PostgreSQL servers. It supports predicate pushdown, allowing PostgreSQL to delegate filtering operations to the remote server, reducing data transfer requirements. With its comprehensive maintenance and documentation, postgres_fdw serves as a robust tool for applications seeking to access data from remote PostgreSQL servers. It offers a reliable solution for seamlessly integrating external data sources into PostgreSQL-based systems.
Architecture:
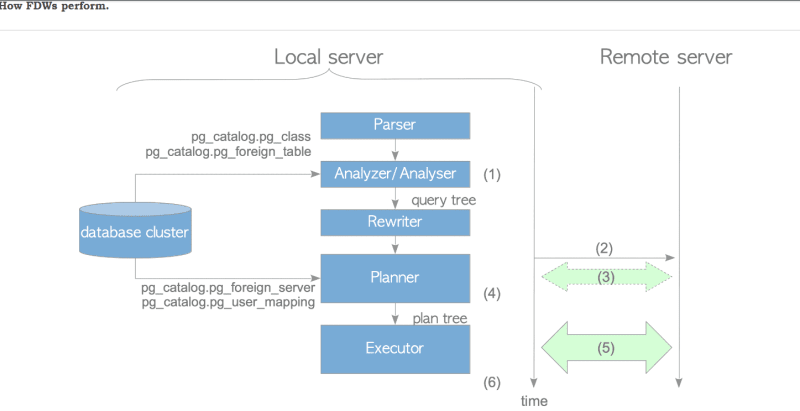
The architecture of FDWs in PostgreSQL can be described as follows:
-
Query Tree Construction:
- During query processing, the PostgreSQL analyzer constructs the query tree for the input SQL statement.
- The definitions of foreign tables, stored in the pg_catalog.pg_class and pg_catalog.pg_foreign_table catalogs, are incorporated into the query tree.
- These definitions can be created using commands such as CREATE FOREIGN TABLE or IMPORT FOREIGN SCHEMA.
-
Connection Establishment:
- The planner (executor) establishes a connection to the remote server using a specific library designed for connecting to the corresponding remote database server.
- For example, the postgres_fdw extension utilizes the libpq library when connecting to a remote PostgreSQL server, while the mysql_fdw extension relies on the libmysqlclient library when connecting to a MySQL server.
-
Cost Estimation:
- When the use_remote_estimate option is enabled (disabled by default), the planner executes EXPLAIN commands to estimate the cost associated with each potential plan path.
- This estimation helps evaluate and select the most optimal plan for query execution.
-
Deparsing:
- The PostgreSQL planner converts the plan tree into a plain text SQL statement through deparsing.
- Deparsing transforms the internal representation of the query plan into a human-readable SQL statement that reflects the intended operations and structure of the query.
-
Execution and Result Handling:
- After the planning phase, the executor sends the plain text SQL statement to the remote server for execution and awaits the result.
- Upon receiving the data from the remote server, the executor may perform additional processing based on the query type.
- For example, in a multi-table query, join processing is carried out to combine the received data with other relevant tables.
- The specific processing steps are determined by the query requirements and data relationships.
By following this architecture, PostgreSQL's FDWs facilitate the seamless integration and processing of data from remote sources, enhancing the capabilities of the database system.
Now we look at the some of benefits in using FDWs in PostgreSQL:
- Data integration: FDWs can be used to integrate data from different databases into a single PostgreSQL database. This can be useful for applications that need to access data from multiple sources.
- Offloading processing: FDWs can be used to offload processing to a different database. This can be useful for applications that need to perform computationally expensive operations on large datasets.
- Performance: FDWs can help to improve the performance of queries that reference data from remote databases. This is because FDWs can push down predicates to the remote database, which can help to reduce the amount of data that needs to be transferred between the two databases.
There are a few things to consider if you're thinking about using FDWs in PostgreSQL:
Performance: Depending on the specific FDW you are using and the remote database's settings, FDW performance can vary. Prior to implementing FDWs in a live environment, it is crucial to assess their performance in that setting.
Security: If FDWs are not configured appropriately, security vulnerabilities may be introduced. Before implementing FDWs in production, it's crucial to properly analyse the security consequences.
Conclusion:
In general, FDWs can be an effective tool for PostgreSQL users to retrieve data from distant databases. However, before implementing FDWs in production, it's crucial to thoroughly weigh their advantages and disadvantages.
In this article, we have explored the fundamental concepts of FDW and its role within PostgreSQL. We have discussed how FDW enables the execution of join operations across multiple servers, enabling seamless data integration. By incorporating the FDW extension, PostgreSQL expands its capabilities, allowing users to effectively manage and analyze remote data alongside local data.





Top comments (0)