Finding attackable open source vulnerabilities in JS applications with an intelligent SCA approach

Open Source Software (OSS) is at the core of today’s information technology. About 80% of companies run their operations on OSS and 96% of applications are built using open source components. Most of today’s commercial products are shipped with some OSS libraries. This also means that securing open source dependencies and fixing open source vulnerabilities became an important part of software security.
This post is co-authored by Chetan Conikee and Vickie Li.
Prioritization in open source security
Once a vulnerability has been found in an open-source component, the easiest way to secure the application is to update the component to a more recent, non-vulnerable version of that library. However, this approach is not feasible when a vulnerable OSS library is part of a system that has already been deployed and made available to its users. In the case of large enterprise systems that serve business-critical functions, any changes or updates may cause system downtime and may come with additional risks.
A better way of dealing with vulnerabilities in open source components is to understand the attackability of the vulnerability first, before investing time and energy into updating the component or implementing mitigation. Is the vulnerable library used by the application in any way? Can user input reach the code required to trigger the vulnerability? Is the vulnerability attackable in that context?
The consequences of making the wrong assessment can be expensive: if a developer wrongly assesses that a given vulnerability is not attackable, application users remain exposed to attackers. If they wrongly judge that it is attackable when it is not, the effort of developing, testing, shipping, and deploying the patch to the customers’ systems is spent in vain. Furthermore, this process requires an enormous amount of manual work, as classification frameworks like the CVE and CWE do not lend well to automation.
Semantic baseline templates for vulnerability analysis
To help classify which vulnerabilities are attackable, we need a semantic baseline template that effectively describes the workflow, resource locations, and consequences (impact) of a vulnerability.
An attack typically comprises of two phases
- Injecting malicious data into the application (via parameter tampering, URL tampering, hidden field manipulation, HTTP header manipulation, cookie poisoning), and
- Using the injected data to manipulate the application (SQL injection, cross-site scripting, HTTP response splitting, path traversal, command injection).
We can understand this process formally by using the process of taint propagation. Taint propagation describes a potential vulnerability as a set of source descriptors, sink descriptors, and derivation/transformation descriptors.
- Source descriptors specify ways in which user-provided data can enter the program (via API endpoints, web routes, etc). They consist of a source method, an argument list, and paths where user data can enter the method.
- Derivation descriptors specify how data propagates between objects in the program.
- Sink descriptors specify unsafe ways in which data may be used in the program. They consist of a sink method (file system API, HTTP response, memory access, etc), its arguments, and ways data can enter the arguments.

Using this model, we can start to classify vulnerabilities based on their source, sink, and derivation/transformation descriptors. This way, we will have a standardized way of describing how a vulnerability can be triggered and under what conditions it’s vulnerable. In short, we’ll have a way of standardizing the decision process of determining whether a vulnerability is attackable in an application's context, and a way to automate this assessment process.
This is the approach we take for open source scanning in Javascript applications. We call this contextual approach to open source security “Intelligent software composition analysis”. Intelligent software composition analysis, unlike traditional SCA, distinguishes between attackable and unattackable open source vulnerabilities, so that you can make an informed decision on which package upgrades to prioritize and focus on the vulnerabilities that are proven to be accessible by attackers.
Intelligent SCA for Javascript applications
Let’s take a look at Shiftleft’s intelligent SCA for Javascript applications.
When you open up your ShiftLeft Dashboard, you’ll see a list of your applications and their scan results. Let’s dive deeper into the application called “shiftleft-js-demo”.

Our scan found 16 vulnerabilities in the application’s custom code and 17 vulnerabilities in its third-party dependencies. Let’s take a look at the application’s custom code vulnerabilities to see how ShiftLeft identifies vulnerabilities.

ShiftLeft uses data flow analysis to discover vulnerabilities. If you open up a finding, you’ll see that ShiftLeft will identify the source of a vulnerability, and trace its data flow to discover if the vulnerability can be triggered by an attacker.
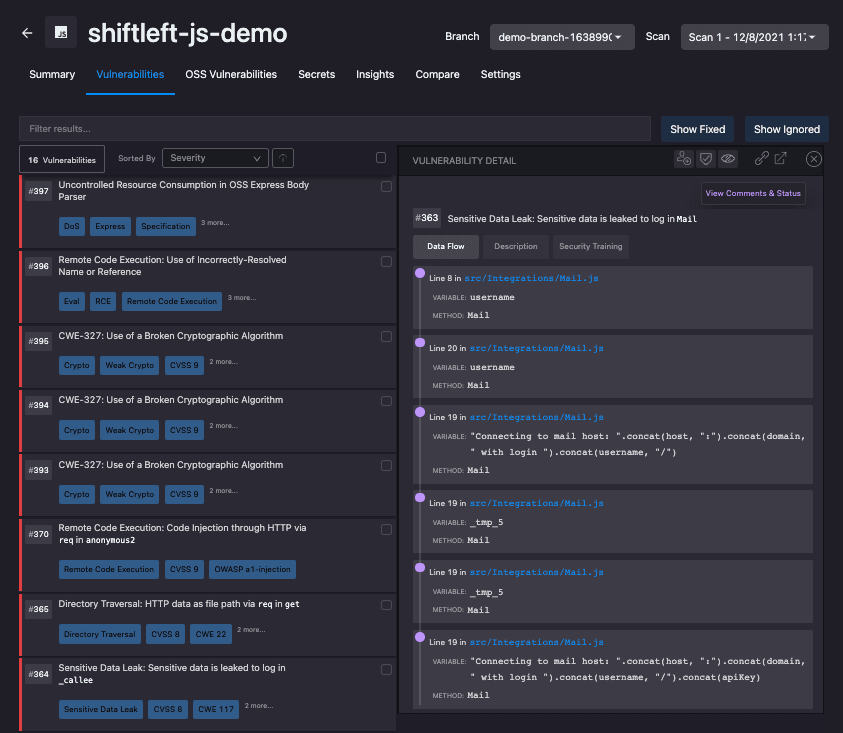
Software composition analysis at ShiftLeft works the same way. ShiftLeft uses data flow analysis to find out if the open-source vulnerability can be triggered by an attacker.
We can see here that although there are 17 open source vulnerabilities in this application, only 2 of them are reachable. This means that there are one or more paths in the code that attackers can use to exploit the open-source vulnerability.

Many open source vulnerabilities that are found in applications are not attackable, sometimes because attacker input cannot affect the vulnerable library, or sometimes because the library is never called by a user-controlled path. Distinguishing between reachable and unreachable open source vulnerabilities has helped SL users reduce their open source security tickets by 92%.
See Intelligent SCA in action with a free account by going to https://shiftleft.io/register and scanning a demo app yourself.





Top comments (0)