
Hey there!
I wanted to learn more about Pandas, a Python library for data analysis, so I decided to embark on a mini-project to experiment with it. If you use Reddit, you've probably seen a chain of comments like below:
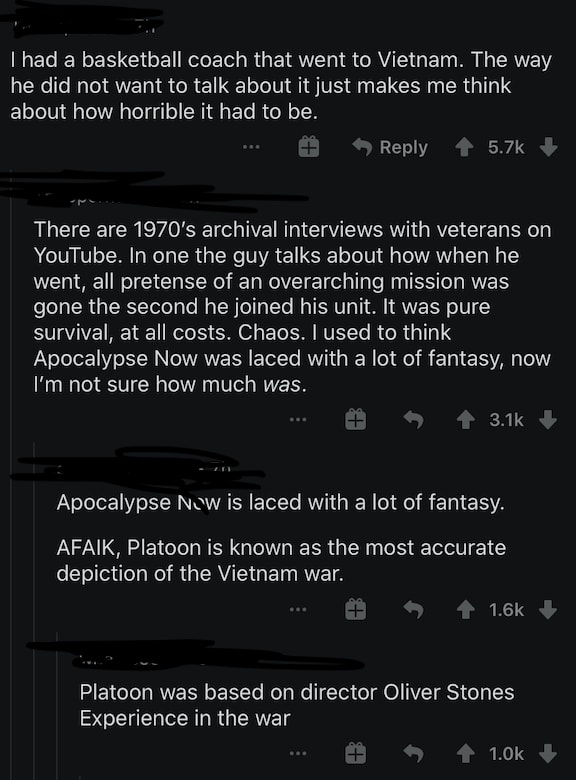
Clearly, you can see that there's a pattern in the number of upvotes. Every reply to the parent comment receives less upvotes compared to the previous reply. It would be interesting to create a bar graph, comparing the number of upvotes the parent comment received, the number of upvotes the first reply received, the number of upvotes the second reply received, ..., the number of upvotes the nth reply received. Using Reddit's API and Pandas, I implemented a program that would do just that. You can find it on GitHub here.
First, we need to import the following:
import praw
import pandas as pd
import matplotlib.pyplot as plt
import sys
import math
from concurrent.futures import ThreadPoolExecutor
PRAW is a Python wrapper for Reddit's API. matplotlib is a library for creating static, animated, and interactive visualizations in Python. These imports will become clearer as we move on.
Next, we need to define authenticate to Reddit's API. PRAW allows us to do this pretty easily with OAuth2:
# Authenticate using our client secret
def authenticate():
with open('client_secret.txt', 'r') as f:
data = f.read().split()
CLIENT_ID = data[0]
CLIENT_SECRET = data[1]
return praw.Reddit(client_id=CLIENT_ID,
client_secret=CLIENT_SECRET,
user_agent=USER_AGENT)
In this case, the client ID and client secret is stored in a file (called client_secret.txt). We read this and return an instance of PRAW's Reddit class, which allows us to interact with Reddit's APIs.
Now, we break down what we have to do in logical chunks. First, we need to get a list of submissions, so that we can look at the comments under each post. PRAW allows us to get a list of the hottest submissions from r/all, which is basically an amalgamation of a bunch of submissions from different subreddits:
def get_submission_upvotes(reddit, m, n):
upvotes_list = []
submissions = list(reddit.subreddit('all').hot(limit=m))
with ThreadPoolExecutor() as executor:
futures = [executor.submit(count_upvotes, submissions[i], n) for i in range(0, m)]
[upvotes_list.append(future.result()) for future in futures]
return upvotes_list
The reason we use concurrent.futures is because, depending on the length of the comment chain we are examining, we might end up taking very long to collect upvotes on one submission but a very short time to collect upvotes on another submission (we will see what the count_upvotes function does next). Here, m represents the number of submissions to look at and n represents the number of comments in a comment chain to examine.
Next, we need to count the number of upvotes of each comment in a comment chain in each submission. This can be done as follows:
def count_upvotes(submission, n):
upvotes = []
submission.comments.replace_more(limit=0)
count = 0
comment = submission.comments[0]
while count < n:
upvotes.append(comment.score)
count += 1
if len(comment.replies) > 0:
comment = comment.replies[0]
else:
break
while len(upvotes) < n:
upvotes.append(float('nan'))
return upvotes
In essence, we get the top comment and keep examining each reply until we have gotten n comments or until the comment chain ends (to get more comment chains of length n, we can increase m). If the comment chain ends prematurely, we add nan (Not a Number) to indicate that no data was collected for the particular reply in the comment chain because that reply did not exist (the comment chain ended, so there were no more upvotes to count).
After counting the upvotes of each comment in the top comment chain, we only have to process the data. First, we compute the average number of upvotes for the top comments, the 1st reply, the 2nd reply, etc:
def compute_data(upvotes_list):
avg_upvotes = []
for col in range(0, len(upvotes_list[0])):
avg = 0.0
n = len(upvotes_list)
for row in range(0, len(upvotes_list)):
if math.isnan(upvotes_list[row][col]) == False:
avg += upvotes_list[row][col]
else:
n -= 1
if n > 0:
avg_upvotes.append(avg / n)
else:
avg_upvotes.append(0)
return avg_upvotes
We return a list called avg_upvotes, which contains the average number of upvotes for the top comment, first reply, second reply, etc. We now convert this list into a bar graph:
def render_data(avg_upvotes, n):
# Solution from https://stackoverflow.com/questions/9647202/ordinal-numbers-replacement
ordinal = lambda n: "%d%s" % (n,"tsnrhtdd"[(n//10%10!=1)*(n%10<4)*n%10::4])
x = [str(ordinal(i)) for i in range(0, n)]
df = pd.DataFrame({'Comment Reply Number': x, 'Average Upvotes': avg_upvotes})
df.plot.bar(x='Comment Reply Number', y='Average Upvotes', rot=0, legend=False)
plt.xlabel('Comment Reply Number')
plt.ylabel('Average Upvotes')
plt.xticks(size=4)
plt.yticks(size=4)
plt.show()
Now all we have to do is put it together:
if __name__ == '__main__':
if len(sys.argv) < 3:
print('./comment_analyzer.py [number of submissions to analyze] [number of comments]')
exit()
m = int(sys.argv[1])
n = int(sys.argv[2])
reddit = authenticate()
upvotes_list = get_submission_upvotes(reddit, m, n)
avg_upvotes = compute_data(upvotes_list)
render_data(avg_upvotes, n)
The program takes two parameters: the number of submissions to look at and the "depth" of the comment chain we have to look at.
Running the program (assuming you have the necessary libraries installed with Python 3.6+), you get a bar graph like so:

(The "0th" comment represents the top comment).
The above graph allows us to visualize the distribution of upvotes on comments on Reddit. Clearly, the distribution is right-skewed: the number of upvotes diminish as we get deeper down the reply chain. This is to be expected, since the top comment tends to be seen first.
Hopefully, you can see how tools like Pandas and PRAW allow us to collect data and visualize it.





Top comments (0)