What will be scraped
Why use Google Lens API from SerpApi?
Using API generally solves all or most problems that might get encountered while creating own parser or crawler. From webscraping perspective, our API can help to solve the most painful problems:
- Bypass blocks from supported search engines by solving CAPTCHA or IP blocks.
- No need to create a parser from scratch and maintain it.
- Pay for proxies, and CAPTCHA solvers.
- Don't need to use browser automation if there's a need to extract data in large amounts faster.
Head to the Playground for a live and interactive demo.
Preparation
First, we need to create a Node.js* project and add npm packages serpapi and dotenv.
To do this, in the directory with our project, open the command line and enter:
$ npm init -y
And then:
$ npm i serpapi dotenv
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
SerpApi package is used to scrape and parse search engine results using SerpApi. Get search results from Google, Bing, Baidu, Yandex, Yahoo, Home Depot, eBay, and more.
dotenv package is a zero-dependency module that loads environment variables from a
.envfile intoprocess.env.
Next, we need to add a top-level "type" field with a value of "module" in our package.json file to allow using ES6 modules in Node.JS:

For now, we complete the setup Node.JS environment for our project and move to the step-by-step code explanation.
Code explanation
First, we need to import dotenv from dotenv library, and config and getJson from serpapi library:
import dotenv from "dotenv";
import { config, getJson } from "serpapi";
Then, we apply some config. Call dotenv config() method and set your SerpApi Private API key to global config object.
dotenv.config();
config.api_key = process.env.API_KEY; //your API key from serpapi.com
-
dotenv.config()will read your.envfile, parse the contents, assign it toprocess.env, and return an object with aparsedkey containing the loaded content or anerrorkey if it failed. -
config.api_keyallows you declare a globalapi_keyvalue by modifying the config object.
Next, we write search engine and write the necessary search parameters for making a request:
const engine = "google_lens"; // search engine
const params = {
url: "https://user-images.githubusercontent.com/64033139/209465038-010d1e56-16db-41d6-9769-6707d6f57111.png", //Parameter defines the URL of an image to perform the Google Lens search
hl: "en", // Parameter defines the language to use for the Google search
};
You can use the next search params:
-
urlParameter defines the URL of an image to perform the Google Lens search. -
hlParameter defines the language to use for the Google Lens search. It's a two-letter language code. (e.g.,enfor English,esfor Spanish, orfrfor French). Head to the Google languages page for a full list of supported Google languages. -
no_cacheparameter will force SerpApi to fetch the App Store Search results even if a cached version is already present. A cache is served only if the query and all parameters are exactly the same. Cache expires after 1h. Cached searches are free, and are not counted towards your searches per month. It can be set tofalse(default) to allow results from the cache, ortrueto disallow results from the cache.no_cacheandasyncparameters should not be used together. -
asyncparameter defines the way you want to submit your search to SerpApi. It can be set tofalse(default) to open an HTTP connection and keep it open until you got your search results, ortrueto just submit your search to SerpApi and retrieve them later. In this case, you'll need to use our Searches Archive API to retrieve your results.asyncandno_cacheparameters should not be used together.asyncshould not be used on accounts with Ludicrous Speed enabled.
Next, we declare the function getResult that gets data from the page and return it:
const getResults = async () => {
...
};
In this function, we need to get json with results,delete unnecessary keys from JSON, and return it.
const results = await getJson(engine, params);
delete results.search_metadata;
delete results.search_parameters;
return results;
And finally, we run the getResults function and print all the received information in the console with the console.dir method, which allows you to use an object with the necessary parameters to change default output options:
getResults().then((result) => console.dir(result, { depth: null }));
Output
{
"reverse_image_search":{
"link":"https://www.google.com/search?tbs=sbi:AMhZZitWp1e8SyEO5dl4qkTCxU70zIpDW4BZqoAlVXqVRYoNA58nc3GQXbry3Wfl6SnzaHZ-xCdVfXXvQmYBmRz2VytmMNasi8-oL3MaHsJM80etUlB7YESZvKTW3gD6f49AdV9TV5A-Sm-Nl9p6tDjuCTPPO6XuZA"
},
"text_results":[
{
"text":"18",
"link":"https://www.google.com/search?q=18&hl=en",
"serpapi_link":"https://serpapi.com/search.json?device=desktop&engine=google&google_domain=google.com&hl=en&q=18"
},
{
"text":"M",
"link":"https://www.google.com/search?q=M&hl=en",
"serpapi_link":"https://serpapi.com/search.json?device=desktop&engine=google&google_domain=google.com&hl=en&q=M"
}
],
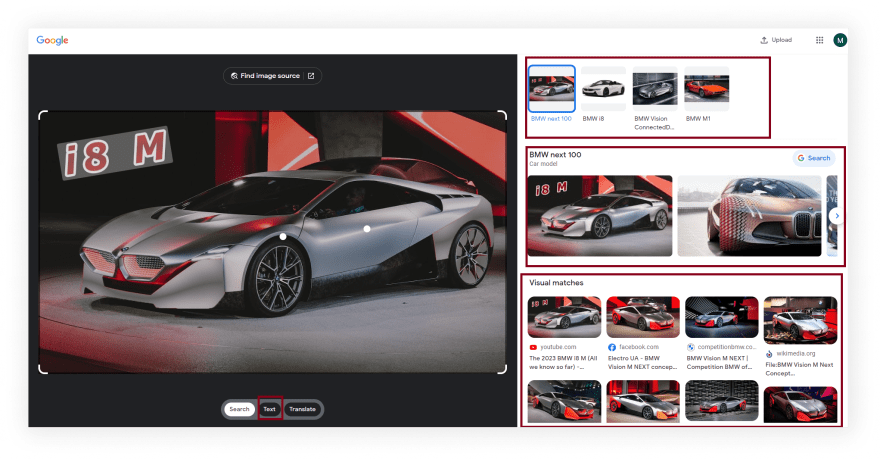
"knowledge_graph":[
{
"title":"BMW i8",
"subtitle":"Sports car",
"link":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&hl=en&gl=US",
"more_images":{
"link":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&ved=0EOTpBwgAKAAwAA&source=.lens.button&tbm=isch&hl=en&gl=US",
"serpapi_link":"https://serpapi.com/search.json?device=desktop&engine=google&gl=US&google_domain=google.com&hl=en&q=BMW+i8&tbm=isch"
},
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH",
"images":[
{
"title":"Image #1 for BMW i8",
"source":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"link":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH",
"size":{
"width":300,
"height":168
}
},
{
"title":"Image #2 for BMW i8",
"source":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSLMCx-TtUdq5kmOhdczYL-PWIgaWtUntnHVAJWbbo7vin_obsM",
"link":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS8sXyFSX0NjlLBQcQbJAC85f-Aw9WIEX2D-Y3by-C7pd23R3C2",
"size":{
"width":276,
"height":182
}
}
]
},
... and other knowledge graph results
],
"visual_matches":[
{
"position":1,
"title":"The 2023 BMW i8 M (All we know so far) - YouTube",
"link":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"source":"youtube.com",
"source_icon":"https://encrypted-tbn0.gstatic.com/favicon-tbn?q=tbn:ANd9GcQHQslzHLLyLc_qne5jxn7JocidlmUPyegZ8ojX3WVlorFk8BxW9a3vJWjDzN99UHVTqSaNBj_-6XykhxuVQfF3Ye7xScSWSuc2QHXi0a12CkVwBmo",
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH"
},
... and other visual matches results
]
}
DIY solution
This section is to show the comparison between our solution and the DIY solution.
If you don't need an explanation, have a look at the full code example in the online IDE
import puppeteer from "puppeteer-extra";
import StealthPlugin from "puppeteer-extra-plugin-stealth";
puppeteer.use(StealthPlugin());
const searchParams = {
imageUrl: "https://user-images.githubusercontent.com/64033139/209465038-010d1e56-16db-41d6-9769-6707d6f57111.png", //Parameter defines the URL of an image to perform the Google Lens search
hl: "en", //Parameter defines the language to use for the Google search
};
const URL = `https://lens.google.com/uploadbyurl?url=${searchParams.imageUrl}&hl=${searchParams.hl}&gl=${searchParams.gl}`;
async function getResultsFromPage(page) {
const reverseImageSearch = await page.evaluate(() => ({ link: document.querySelector(".z3qvzf .WpHeLc").getAttribute("href") }));
const knowledgeGraphItems = await page.$$(".sHc5hf > div");
const knowledgeGraph = [];
for (const item of knowledgeGraphItems) {
await item.click();
await page.waitForTimeout(2000);
const thumbnail = await item.$eval(".FH8DCc", (node) => node.getAttribute("src"));
knowledgeGraph.push(
await page.evaluate(
(thumbnail) => ({
title: document.querySelector(".DeMn2d").textContent,
subtitle: document.querySelector(".XNTym").textContent,
link: document.querySelector(".wNPKTe a").getAttribute("href"),
moreImagesLink: document.querySelector(".XkkoHf + div .Tc2PU > a").getAttribute("href"),
thumbnail,
images: Array.from(document.querySelectorAll(".XkkoHf + div .Tc2PU .Y02Gld a")).map((el) => ({
title: el.getAttribute("aria-label"),
source: el.getAttribute("href"),
link: el.querySelector("img").getAttribute("src"),
})),
}),
thumbnail
)
);
}
const height = await page.evaluate(() => document.querySelector(".jXKZBd").scrollHeight);
const scrollIterationCount = 5;
for (let i = 0; i < scrollIterationCount; i++) {
await page.mouse.wheel({ deltaY: height / scrollIterationCount });
await page.waitForTimeout(2000);
}
const visualMatches = await page.evaluate(() => {
return Array.from(document.querySelectorAll(".Vd9M6 a")).map((el) => ({
title: el.getAttribute("aria-label"),
link: el.getAttribute("href"),
source: el.querySelector(".PlAMyb span").textContent,
sourceIcon: el.querySelector(".PlAMyb img").getAttribute("src"),
thumbnail: el.querySelector(".Me0cf img").getAttribute("src"),
}));
});
await page.click("#text");
await page.waitForTimeout(2000);
const textResultsItems = await page.$$(".WfGljd[aria-label]");
const textResults = [];
for (const item of textResultsItems) {
await page.click("#text");
await page.waitForTimeout(2000);
await item.click();
await page.waitForTimeout(2000);
textResults.push(
await page.evaluate(() => ({
text: document.querySelector(".C3t4Ke").textContent,
link: document.querySelector("a[aria-label=Search]").getAttribute("href"),
}))
);
}
return { reverseImageSearch, textResults, knowledgeGraph, visualMatches };
}
async function getLensResults() {
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
const results = await getResultsFromPage(page);
await browser.close();
return results;
}
getLensResults().then((result) => console.dir(result, { depth: null }));
Preparation
First, we need to add npm packages puppeteer, puppeteer-extra and puppeteer-extra-plugin-stealth to control Chromium (or Chrome, or Firefox, but now we work only with Chromium which is used by default) over the DevTools Protocol in headless or non-headless mode.
To do this, in the directory with our project, open the command line and enter:
$ npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth
📌Note: also, you can use puppeteer without any extensions, but I strongly recommended use it with puppeteer-extra with puppeteer-extra-plugin-stealth to prevent website detection that you are using headless Chromium or that you are using web driver. You can check it on Chrome headless tests website. The screenshot below shows you a difference.

Process
We need to extract data from HTML elements. The process of getting the right CSS selectors is fairly easy via SelectorGadget Chrome extension which able us to grab CSS selectors by clicking on the desired element in the browser. However, it is not always working perfectly, especially when the website is heavily used by JavaScript.
We have a dedicated Web Scraping with CSS Selectors blog post at SerpApi if you want to know a little bit more about them.
The Gif below illustrates the approach of selecting different parts of the results using SelectorGadget.
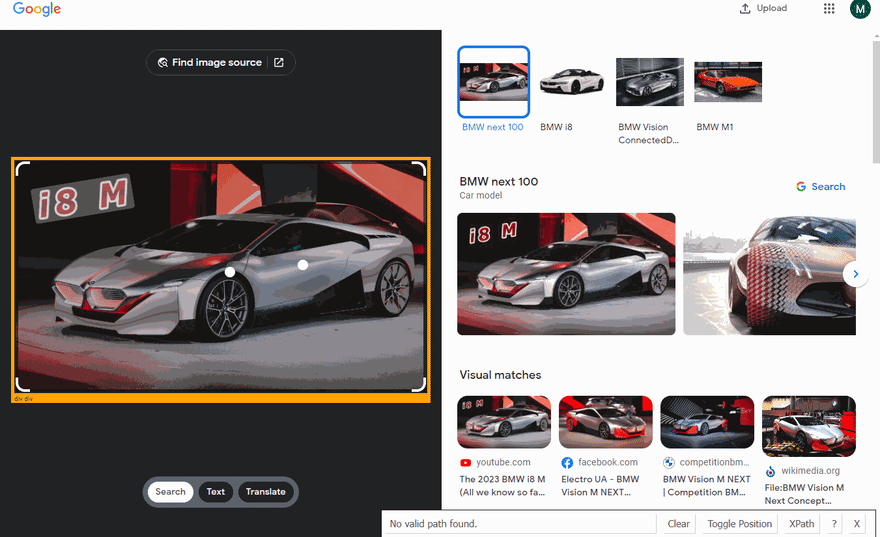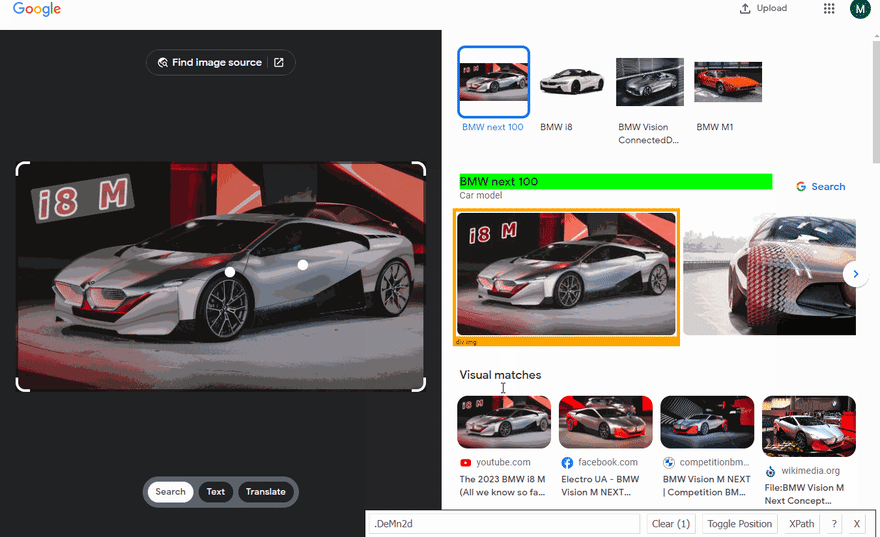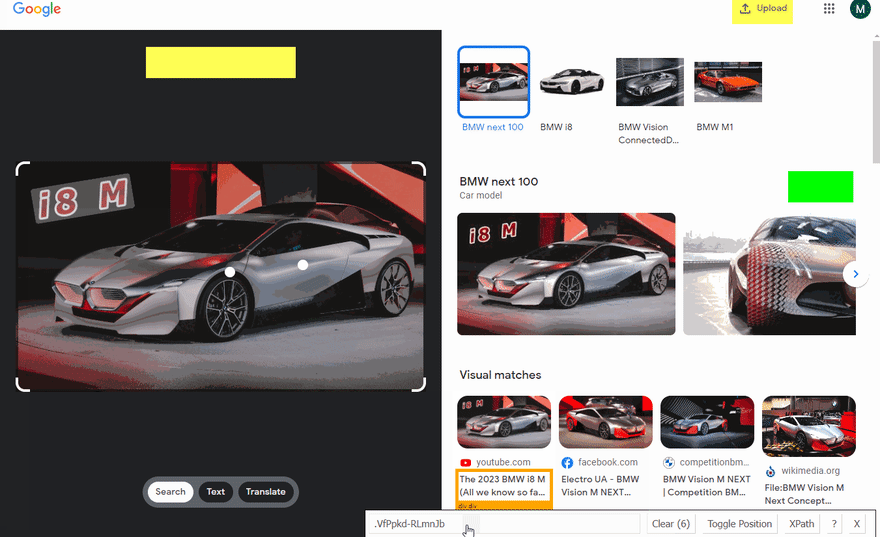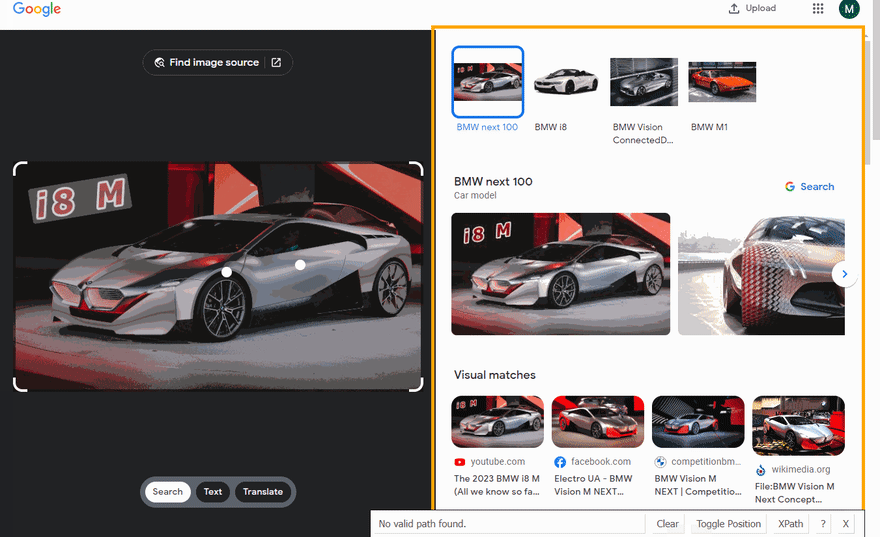
Code explanation
Declare puppeteer to control Chromium browser from puppeteer-extra library and StealthPlugin to prevent website detection that you are using web driver from puppeteer-extra-plugin-stealth library:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
Next, we "say" to puppeteer use StealthPlugin, write the search parameters and the search URL:
puppeteer.use(StealthPlugin());
const searchParams = {
imageUrl: "https://user-images.githubusercontent.com/64033139/209465038-010d1e56-16db-41d6-9769-6707d6f57111.png", //Parameter defines the URL of an image to perform the Google Lens search
hl: "en", //Parameter defines the language to use for the Google search
};
const URL = `https://lens.google.com/uploadbyurl?url=${searchParams.imageUrl}&hl=${searchParams.hl}&gl=${searchParams.gl}`;
Next, we write a function to get results from the page:
async function getResultsFromPage(page) {
...
}
In this function we'll use the next methods to get the necessary information:
Then, we get link to the Google Reverse Image from the page context (using evaluate() method) and save it in the reverseImageSearch constant:
const reverseImageSearch = await page.evaluate(() => ({ link: document.querySelector(".z3qvzf .WpHeLc").getAttribute("href") }));
Next, we get knowledge graph info. To do this, we need to get all knowledgeGraphItems from the page (with .$$() method).
Then, using for...of loop we click (click() method) on each item and get and add (push() method) information from this knowledge graph to the knowledgeGraph array:
const knowledgeGraphItems = await page.$$(".sHc5hf > div");
const knowledgeGraph = [];
for (const item of knowledgeGraphItems) {
await item.click();
await page.waitForTimeout(2000);
const thumbnail = await item.$eval(".FH8DCc", (node) => node.getAttribute("src"));
knowledgeGraph.push(
await page.evaluate(
(thumbnail) => ({
title: document.querySelector(".DeMn2d").textContent,
subtitle: document.querySelector(".XNTym").textContent,
link: document.querySelector(".wNPKTe a").getAttribute("href"),
moreImagesLink: document.querySelector(".XkkoHf + div .Tc2PU > a").getAttribute("href"),
thumbnail,
images: Array.from(document.querySelectorAll(".XkkoHf + div .Tc2PU .Y02Gld a")).map((el) => ({
title: el.getAttribute("aria-label"),
source: el.getAttribute("href"),
link: el.querySelector("img").getAttribute("src"),
})),
}),
thumbnail
)
);
}
Next, we need to scroll the page to load all thumbnails (if we don't, we get only a 1x1 pixels size placeholder). To do this we get page height, set scrollIterationCount to define how parts we want to divide the page, and then scroll it (mouse.wheel() method):
const height = await page.evaluate(() => document.querySelector(".jXKZBd").scrollHeight);
const scrollIterationCount = 5;
for (let i = 0; i < scrollIterationCount; i++) {
await page.mouse.wheel({ deltaY: height / scrollIterationCount });
await page.waitForTimeout(2000);
}
Next, we get info for visual match results and save it in the visualMatches constant.
const visualMatches = await page.evaluate(() => {
return Array.from(document.querySelectorAll(".Vd9M6 a")).map((el) => ({
title: el.getAttribute("aria-label"),
link: el.getAttribute("href"),
source: el.querySelector(".PlAMyb span").textContent,
sourceIcon: el.querySelector(".PlAMyb img").getAttribute("src"),
thumbnail: el.querySelector(".Me0cf img").getAttribute("src"),
}));
});
To get the text results we click on the "Text" button, get all text items and set info from each item to the textResults array:
await page.click("#text");
await page.waitForTimeout(2000);
const textResultsItems = await page.$$(".WfGljd[aria-label]");
const textResults = [];
for (const item of textResultsItems) {
await page.click("#text");
await page.waitForTimeout(2000);
await item.click();
await page.waitForTimeout(2000);
textResults.push(
await page.evaluate(() => ({
text: document.querySelector(".C3t4Ke").textContent,
link: document.querySelector("a[aria-label=Search]").getAttribute("href"),
}))
);
}
Then, we return the object with all the info that we get in this function:
return { reverseImageSearch, textResults, knowledgeGraph, visualMatches };
Next, write a function to control the browser, and get information:
async function getLensResults() {
...
}
In this function first we need to define browser using puppeteer.launch({options}) method with current options, such as headless: true and args: ["--no-sandbox", "--disable-setuid-sandbox"].
These options mean that we use headless mode and array with arguments which we use to allow the launch of the browser process in the online IDE. And then we open a new page:
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
Next, we change the default (30 sec) time for waiting for selectors to 60000 ms (1 min) for slow internet connection with .setDefaultNavigationTimeout() method, go to URL with .goto() method:
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
Then we define the results array and save results from page to it:
const results = await getResultsFromPage(page);
And finally, we close the browser, and return the received data:
await browser.close();
return results;
Now we can launch our parser:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
Output
{
"reverseImageSearch":{
"link":"https://www.google.com/search?tbs=sbi:AMhZZis56hg-YEqgOHS8pa8l_1QxyQa2cxtCmEZoD71xt6dE6WPxXnbPXQV6EuTR9Yhnyb56yuK1pVQveu_1_1lXI49V16nuPJPYy5LFOIu9_16JkSKvotCdgwacqAKAxnmZ8mjkw0qYAZqvGzmkOCPnXM6oko0pADoQ4A"
},
"textResults":[
{
"text":"\"18\"",
"link":"https://www.google.com/search?q=18%20"
},
{
"text":"\"M\"",
"link":"https://www.google.com/search?q=M"
}
],
"knowledgeGraph":[
{
"title":"BMW i8",
"subtitle":"Sports car",
"link":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&hl=en&gl=US",
"moreImagesLink":"https://www.google.com/search?q=BMW+i8&kgmid=/m/080607h&ved=0EOTpBwgAKAAwAA&source=.lens.button&tbm=isch&hl=en&gl=US",
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH",
"images":[
{
"title":"Image #1 for BMW i8",
"source":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"link":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH"
},
{
"title":"Image #2 for BMW i8",
"source":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSLMCx-TtUdq5kmOhdczYL-PWIgaWtUntnHVAJWbbo7vin_obsM",
"link":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS8sXyFSX0NjlLBQcQbJAC85f-Aw9WIEX2D-Y3by-C7pd23R3C2"
}
]
},
... and other knowledge graph results
],
"visualMatches":[
{
"title":"The 2023 BMW i8 M (All we know so far) - YouTube",
"link":"https://www.youtube.com/watch?v=fOXuBey9xo8",
"source":"youtube.com",
"sourceIcon":"https://encrypted-tbn0.gstatic.com/favicon-tbn?q=tbn:ANd9GcQHQslzHLLyLc_qne5jxn7JocidlmUPyegZ8ojX3WVlorFk8BxW9a3vJWjDzN99UHVTqSaNBj_-6XykhxuVQfF3Ye7xScSWSuc2QHXi0a12CkVwBmo",
"thumbnail":"https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcS7p4dD_8PlhsKlZ_5N2szF0jRpzjc-KiboC0GrNmPQhFsd8rAH"
},
... and other visual matches results
]
}
Links
If you want other functionality added to this blog post or if you want to see some projects made with SerpApi, write me a message.
Add a Feature Request💫 or a Bug🐞

Oldest comments (0)