
Intro
In this blog post, I want to show how you can extract images from Google Images. I'll show you two different DIY solutions and a ready-made solution from SerpApi and explain the difference between these solutions.
What will be scraped
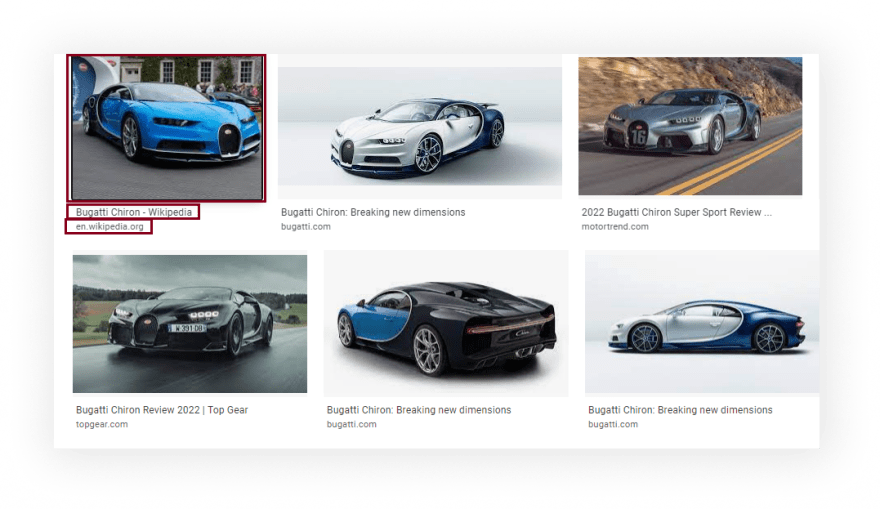
Process
First of all, we need to extract data from HTML elements. The process of getting the right CSS selectors is fairly easy via SelectorGadget Chrome extension which able us to grab CSS selectors by clicking on the desired element in the browser. However, it is not always working perfectly, especially when the website is heavily used by JavaScript.
We have a dedicated web Scraping with CSS Selectors blog post at SerpApi if you want to know a little bit more about them.
The Gif below illustrates the approach of selecting different parts of the results.

Solution one (using the raw HTML from request)
📌Note: this solution is fast but it allows to receive images only from the first results page.
If you don't need an explanation, have a look at the full code example in the online IDE
const cheerio = require("cheerio");
const axios = require("axios");
const searchString = "bugatti chiron"; // what we want to search
const AXIOS_OPTIONS = {
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
}, // adding the User-Agent header as one way to prevent the request from being blocked
params: {
q: searchString, // our encoded search string
hl: "en", // parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
tbm: "isch", // parameter defines the type of search you want to do (isch - Google Images)
},
};
function getGoogleImagesResults() {
return axios.get("http://google.com/search", AXIOS_OPTIONS).then(function ({ data }) {
let $ = cheerio.load(data);
const imagesRawPattern = /AF_initDataCallback\((?<images>[^<]+)\);/gm; //https://regex101.com/r/74JN5w/1
let imagesRaw = [...data.matchAll(imagesRawPattern)].map(({ groups }) => groups.images);
imagesRaw = imagesRaw.length > 1 ? imagesRaw[1] : imagesRaw[0];
eval(`imagesRaw = ${imagesRaw}`);
imagesRaw = JSON.stringify(imagesRaw);
const imagesPattern = /\[\"GRID_STATE0\",null,\[\[1,\[0,\".*?\",(?<images>.*),\"All\",/gm; //https://regex101.com/r/qXqmKz/1
let images = [...imagesRaw.matchAll(imagesPattern)].map(({ groups }) => groups.images)[0];
const thumbnailsPattern = /\[\"(?<thumbnail>https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]/gm; // https://regex101.com/r/Ms61BF/1
const thumbnails = [...images.matchAll(thumbnailsPattern)].map(({ groups }) => groups.thumbnail);
images = images.replace(thumbnailsPattern, "");
const originalsPattern = /('|,)\[\"(?<original>https|http.*?)\",\d+,\d+\]/gm; // https://regex101.com/r/sA9I4E/1
const originals = [...images.matchAll(originalsPattern)].map(({ groups }) => groups.original);
return Array.from($(".PNCib.MSM1fd")).map((el, i) => ({
title: $(el).find(".VFACy").attr("title"),
link: $(el).find(".VFACy").attr("href"),
source: $(el).find(".fxgdke").text(),
original: originals[i],
thumbnail: thumbnails[i],
}));
});
}
getGoogleImagesResults().then((result) => console.dir(result, { depth: null }));
Preparation
First, we need to create a Node.js* project and add npm packages cheerio to parse parts of the HTML markup, and axios to make a request to a website.
To do this, in the directory with our project, open the command line and enter npm init -y, and then npm i cheerio axios.
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
Code explanation
Declare constants from cheerio and axios libraries:
const cheerio = require("cheerio");
const axios = require("axios");
Next, we write what we want to search for, HTTP headers with User-Agent (is used to act as a "real" user visit. Default axios requests user-agent is axios/0.27.2 so websites understand that it's a script that sends a request and might block it. Check what's your user-agent), and the necessary parameters for making a request:
const searchString = "bugatti chiron"; // what we want to search
const AXIOS_OPTIONS = {
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
}, // adding the User-Agent header as one way to prevent the request from being blocked
params: {
q: searchString, // our encoded search string
hl: "en", // parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
tbm: "isch", // parameter defines the type of search you want to do (isch - Google Images)
},
};
Next, we write a function that makes the request and returns the received data. We received the response from axios request that has data key that we destructured and parse it with cheerio:
function getGoogleImagesResults() {
return axios.get("http://google.com/search", AXIOS_OPTIONS).then(function ({ data }) {
let $ = cheerio.load(data);
...
})
}
Then, we need to get and clear the part of HTML that contain images data. First, we define imagesRawPattern, then using spread syntax we make an array from an iterable iterator of matches, received from matchAll method.
Next, we take the first or second match result (depending on page context), execute it (using eval() method) to get an object from the string and make a valid JSON string (we need to do this because the starter imagesRaw string has encoded symbols(e.g. '\u0026'), and when we execute it the string is decoded):
const imagesRawPattern = /AF_initDataCallback\((?<images>[^<]+)\);/gm; //https://regex101.com/r/74JN5w/1
let imagesRaw = [...data.matchAll(imagesRawPattern)].map(({ groups }) => groups.images);
imagesRaw = imagesRaw.length > 1 ? imagesRaw[1] : imagesRaw[0];
eval(`imagesRaw = ${imagesRaw}`);
imagesRaw = JSON.stringify(imagesRaw);
Then, using the different Regex patterns we get images string, and thumbnails and originals arrays (to find originals, we need to remove thumbnails links from images string with replace() method):
const imagesPattern = /\[\"GRID_STATE0\",null,\[\[1,\[0,\".*?\",(?<images>.*),\"All\",/gm; //https://regex101.com/r/qXqmKz/1
let images = [...imagesRaw.matchAll(imagesPattern)].map(({ groups }) => groups.images)[0];
const thumbnailsPattern = /\[\"(?<thumbnail>https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]/gm; // https://regex101.com/r/Ms61BF/1
const thumbnails = [...images.matchAll(thumbnailsPattern)].map(({ groups }) => groups.thumbnail);
images = images.replace(thumbnailsPattern, "");
const originalsPattern = /('|,)\[\"(?<original>https|http.*?)\",\d+,\d+\]/gm; // https://regex101.com/r/sA9I4E/1
const originals = [...images.matchAll(originalsPattern)].map(({ groups }) => groups.original);
And finally, we need to get title, link and source of each images from the HTML selectors (using $(), find(), attr() and text() methods) and combine it with original and thumbnail:
return Array.from($(".PNCib.MSM1fd")).map((el, i) => ({
title: $(el).find(".VFACy").attr("title"),
link: $(el).find(".VFACy").attr("href"),
source: $(el).find(".fxgdke").text(),
original: originals[i],
thumbnail: thumbnails[i],
}));
Now we can launch our parser:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
Output
[
{
"title":"Bugatti Chiron - Wikipedia",
"link":"https://en.wikipedia.org/wiki/Bugatti_Chiron",
"source":"en.wikipedia.org",
"original":"https://upload.wikimedia.org/wikipedia/commons/thumb/6/62/Bugatti_Chiron_%2836559710091%29.jpg/1200px-Bugatti_Chiron_%2836559710091%29.jpg",
"thumbnail":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtn09W1RkuFRfj8Gbfj16Jt_ZnQ8vsvZRGBOfO3gOnUPrprSUH3nuFcOz-VdKk1bHGgdI&usqp=CAU"
},
{
"title":"Bugatti Chiron: Breaking new dimensions",
"link":"https://www.bugatti.com/chiron/",
"source":"bugatti.com",
"original":"https://www.bugatti.com/fileadmin/_processed_/sei/p54/se-image-4799f9106491ebb58ca3351f6df5c44a.jpg",
"thumbnail":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ-usS_C6OB_O4_0QgQsrQlTZXl4n_ouoyrpKBHObK0OgvEgNB0W3lS9EIJdLnm_1WrJy0&usqp=CAU"
},
... and other results
]
Solution two (using browser automation with Puppeteer)
📌Note: this solution is much slower but it allows to receive all images from all results pages (using the infinite scroll).
If you don't need an explanation, have a look at the full code example in the online IDE
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const searchQuery = "bugatti chiron";
async function getImagesData(page) {
const imagesResults = [];
let iterationsLength = 0;
while (true) {
const images = await page.$$(".OcgH4b .PNCib.MSM1fd");
for (; iterationsLength < images.length; iterationsLength++) {
images[iterationsLength].click();
await page.waitForTimeout(2000);
imagesResults.push(
await page.evaluate(
(iterationsLength) => ({
thumbnail: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector(".Q4LuWd")?.getAttribute("src"),
source: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector(".VFACy div")?.textContent.trim(),
title: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector("h3")?.textContent.trim(),
link: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector(".VFACy")?.getAttribute("href"),
original: Array.from(document.querySelectorAll(".eHAdSb .n3VNCb"))
.find((el) => !el.getAttribute("src").includes("data:image") && !el.getAttribute("src").includes("gstatic.com"))
?.getAttribute("src"),
}),
iterationsLength
)
);
}
await page.waitForTimeout(5000);
const newImages = await page.$$(".OcgH4b .PNCib.MSM1fd");
if (newImages.length === images.length) break;
}
return imagesResults;
}
async function getGoogleImagesResults() {
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const URL = `https://www.google.com/search?q=${encodeURI(searchQuery)}&tbm=isch&hl=en&gl=es`;
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".PNCib");
const imagesResults = await getImagesData(page);
await browser.close();
return imagesResults;
}
getGoogleImagesResults().then((result) => console.dir(result, { depth: null }));
Preparation
First, we need to create a Node.js* project and add npm packages puppeteer, puppeteer-extra and puppeteer-extra-plugin-stealth to control Chromium (or Chrome, or Firefox, but now we work only with Chromium which is used by default) over the DevTools Protocol in headless or non-headless mode.
To do this, in the directory with our project, open the command line and enter npm init -y, and then npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth.
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
📌Note: also, you can use puppeteer without any extensions, but I strongly recommended use it with puppeteer-extra with puppeteer-extra-plugin-stealth to prevent website detection that you are using headless Chromium or that you are using web driver. You can check it on Chrome headless tests website. The screenshot below shows you a difference.

Code explanation
Declare puppeteer to control Chromium browser from puppeteer-extra library and StealthPlugin to prevent website detection that you are using web driver from puppeteer-extra-plugin-stealth library:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
Next, we "say" to puppeteer use StealthPlugin and write what we want to search:
puppeteer.use(StealthPlugin());
const searchQuery = "bugatti chiron";
Next, we write a function to get images data from the Google Search page:
async function getImagesData(page) {
...
}
In this function, first, we create the empty imagesResults array and set iterationsLength equal to "0":
const imagesResults = [];
let iterationsLength = 0;
Next, we use the while loop in which we need to get all images (using $$ method), click (using click() method) on the each image, wait 2 seconds (using waitForTimeout method) and add image data to the end of the imagesResults array (using push() method):
while (true) {
const images = await page.$$(".OcgH4b .PNCib.MSM1fd");
for (; iterationsLength < images.length; iterationsLength++) {
images[iterationsLength].click();
await page.waitForTimeout(2000);
imagesResults.push(
...
);
}
...
}
return imagesResults;
Then, we get all image data from the page using evaluate() method and pass iterationsLength variable to the page context:
await page.evaluate((iterationsLength) => ({
...
}), iterationsLength)
Next, we get need information from HTML selectors. We can do this with querySelectorAll() methods to get access to right HTML selectors, textContent and trim() methods, which get the raw text and removes white space from both sides of the string. If we need to get links, we use getAttribute() method to get "href" or "src" HTML element attribute, and finally find() method to get the right selector from an array of the same selectors:
thumbnail: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector(".Q4LuWd")?.getAttribute("src"),
source: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector(".VFACy div")?.textContent.trim(),
title: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector("h3")?.textContent.trim(),
link: document.querySelectorAll(".OcgH4b .PNCib.MSM1fd")[iterationsLength].querySelector(".VFACy")?.getAttribute("href"),
original: Array.from(document.querySelectorAll(".eHAdSb .n3VNCb"))
.find((el) => !el.getAttribute("src").includes("data:image") && !el.getAttribute("src").includes("gstatic.com"))
?.getAttribute("src"),
Next, we wait 5 seconds until new images are loaded, get all images again and check if the length of the newImages array is the same as the length of the images array we stop the loop, otherwise repeat the loop again:
await page.waitForTimeout(5000);
const newImages = await page.$$(".OcgH4b .PNCib.MSM1fd");
if (newImages.length === images.length) break;
Next, write a function to control the browser, and get information:
async function getGoogleImagesResults() {
...
}
In this function first we need to define browser using puppeteer.launch({options}) method with current options, such as headless: false and args: ["--no-sandbox", "--disable-setuid-sandbox"].
These options mean that we use headless mode and array with arguments which we use to allow the launch of the browser process in the online IDE. And then we open a new page:
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
Next, we change default (30 sec) time for waiting for selectors to 60000 ms (1 min) for slow internet connection with .setDefaultNavigationTimeout() method, go to URL with .goto() method and use .waitForSelector() method to wait until the selector is load:
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".PNCib");
Then, we wait until the getImagesData functions was finished and save the results of this function to the imagesResults constant:
const imagesResults = await getImagesData(page);
And finally, we close the browser, and return the received data:
await browser.close();
return imagesResults;
Now we can launch our parser:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
Output
📌Note: some of the picture's thumbnails are present in the base64 format and some is a links to the thumbnail.
[
{
"thumbnail":"data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAoHCBUWFRgVFhYZGRgYGBgYGBwcGh0cGhgYGBgZGRkYGhocIS4lHB4rIRgYJjgmKy8xNTU1GiQ7QDs0Py40NTEBDAwMEA8QGhISHzckISQ2NDc0NDE0NjQ0NDQ0NDUxNDE0NDQ0NDQ0NDQxMTQ0NDQ0NDQ0NDQ0NDE0NDQ0NDQ0NP/AABEIAKgBLAMBIgACEQEDEQH/xAAcAAABBQEBAQAAAAAAAAAAAAACAAEDBAYFBwj/xABKEAACAQIDBAUIBwQIBQUBAAABAgADEQQSITFBUWEFBnGBkRMiMqGxwdHwFEJScoKS4UOywvEHFRZUYpOi0iMzU4PiNERkc9Mk/8QAGQEBAQEBAQEAAAAAAAAAAAAAAAECAwQF/8QAJREAAgIBBAICAwEBAAAAAAAAAAECERIDIUFREzEiYQRxgZEy/9oADAMBAAIRAxEAPwDypGF9f0h7tkFFGa3u/WTKOHum2QcLpfd4SXDkG9lGzi3xkajl65JSTW/8oNFNnOo4QFTUe+W61PU2+ECmzKp59kWShiNdhPPdDC5hbKo56+8waRv+sstI2WiNaNt9+Q2SYjXZ6olNpIhJkbKgXpm3oiDrw98sO26QsDykTKPTU2grStcyzh6emoPsgVaW7WLFFGvU1hUbyyMEdtj4QzhiOXzyltEplB6ZMiVbTpJhxxkq4UcfAaxki4nLe/LwgKp0nWOFTbZj2m0A0gNir4xkhic8gfJjoh25TLLI+7KOwSRFO9ie6HIYlNVJ3GEKRl+1uJ+eUjdGO71mTIYldaPMCGuFU+k1hyt75KuGtttD8kN0jkMSIYekN7H8QH8MH6Oh3HvMkdJFlixQ60FO6J6IENRHMWNiq7W2QVYmWGXt9cA1LbBLZGCgPC8epXYaE92kheuTvMjUS0ZsnzE7TJ6a2ldCJaplZhnSJKjfNoV/nSIMvA+MWYcPXMmyJsIAL6XkZoA7ZcAvsgOluc62cqKyIqkXPd+ssrVG4SIUxtvrDEz7AOW8kSgjW07/AJ0kZa0kQ89IYQnw6LsFzKtZyNol2sdJzKz3kQkSpWvpLKkCc1b3ltCbbZpoIJxeFT03wQpkqOBy7oKSir4QxUvxkDPePTaZZUyfx8Ya4UtvMOjSudoEsviMo0ynuE5uT4N0uSen0fRVbkm/bKWJQX0OndKlXEEnbAWpz9UkYtbtkcl6QZyjb7INQg7NB88oi43k+yRvY/zvOhLIH2ySnByyalT5+2CIcIeMMBt0nSnylhKSAecQPXI3RtIprT42icWlivXUDzbHuM571SdohWw9hP8AOsjZZJEF5+2UwVzyiykbRLBsN/t+MrO3CWzLAqud/tPwlZ2J3yVlgkTSJRFaEIeWLLLYoYGErxssa0UUmFQwsxkI7YVxM0WzpUmFoFRydsZWHEeNoNVxu9sAJbn5/SS5O+RUQTst4yx5Pi0llS2IBt2QmaGKfaYVNYbFCpEHbK1fDi8sOg7JCx5yBoqmkJKigSVaIO+WMLg2dwiKzu2xVFyeJ5DmdBLkZRCjA7I/kddvvnVq4PC0P/VYlQ++lR/4jg8GfVEPKx7YNDrP0YmzBPU51XuT+HNlHcBNKLZXJHLfDm2kCm4B85rd83nQvWfo+pYfQlpA7GNEFe91vbtNhOj05gMCyFjQXXW9Nip1ta2U2N7jlrLg2c3Ojz09IIBYOD6/ZILq1yzhBzRz4BEPrtNc/VfDFbmnk5CpVc/vBRKSdWcLmCCizsxAUF21J2CwYSrSRHrGdK4f+8i/OnUA8SLSrUxKA2Dg8wGt421m8wvVekzOi4OkGpkZ1ZmzC+w6ubjmJBX6Kp6ocMEttslhpzZTpLhEz5DDNVXaSSBtIFxJaOKo/a8QfcJe6W6OVSGCOqcQQQbc1At4TmYbAeUqFaRGoLAOc1gBc3IAue6VaV7IvmSTv0i19Kp7nXv09ssUSG2FT2Gcl6JzNTK0wVIvYML34G/ulf6I6kG1uanUc+JmJaaTq9za1Nk+DRN5o2iRO7nYPVOfhseyErUBJIGVja23abqSe4jvnRLO2oAtxAGkw4tHRTTIHpnfACDj4AmWfoZOpMFqWX5EWGgEQ7r+ETXELOIOXlIQhc9kGSMnKRkcoKJgOIkTDskh7IJUyoURWjFZJaMRNEoiKwDJGEEpNIjQIaFmjpT5+ySilz9YkdBI9MHTIPo9Ip+Knb+MSVMazbMdhm+8n/nOE6Yn/p02+9RX9Yz06lvOw2HPZdP3VmPLHtGMX0aNPLnZVwTfgb9YXksT9jCN3W9qTJPRQelhF/BUv+80izUV/YV1+6VI9SmaU0/VMY/s2TUMRvw2EbvQe1JEaFXfgMKexqP/AOcyC4qgNlXEUzzVtP3ZZpYxdi49wd17j1ZzL/BX2aF8O21ujqZ+6KZ9gEhwmDqVlL0OjcO6gkXNVFJI3ZQPfOx0DQp08zYvECqQ+RUY3RW0HnjebnYdBod4sulOuwQkIvo3GumzkNkqV8Ebr2zmYToGu7FX6Pw+HUDV3qu4HNUQgv2XA5iYvrH1iSnnwuCJVL2q1fr12G0ZhsQG9gNOHFt3126wMmBLqbPVARSCdC+0g8lDG/G0wnVDqvXxbpmCNSJN8xs2VfssNRuG2Pit2VW/RS6qdV3xVREtbPmy5r5bJq7G2pAuB2sBxt670H1NwGAGesKbv9utY68UQ6L3C/MyXBdCYjD1KtdKa5fJpQoJSIZqdNfOY5XKAktc6EnWcHpDog1Xu4x2Y7c2FLA9hV7AQ5R5YxlwenYLEU3RXpsrow80rYqd2lvCZTrhRU5sqW8xc5FrBnL5D966nxF90m6lUVw6HCZmzBnqKrJkbI5BuFzEEZs2oO+dDEYFno11KnM7Mw0P1bCnbuRDpxMzGSvZklF1uYrA1i1FHFwbWO8G2koV67o6uNGVgw00uDcacJ0cJgcRQzh8PWKFrjKhbbt0HzpK1cgnWjiQP/pf22Ok7WjhjLorY3rBUestcqqsq5GKAjOnBrk/NuAg9K9YQ6FFD3NtSVGl/OuNfdIatOmWyhayn/FQe35soEq1nK2Aci2mqHx2G8WuC12H0W+b0mTIbgqxN/ACcfpToRCxam+VsxC2BFzytx986mKrUR5qOz31LGiqG/K3xk2D6TwyUyr0ndzms2QEC98ul90XyEnZ5/j+jXpkBiCzfVFyQAN9wPkS90Yq5VUsNpzHK7Kp4Eqp9U9EwnXDyNPJQwik2JdnR8ztfXQIbjcBfvmWZKzO7pg3u7FlVKb5UJOtlym/KZ9+zp8uCHF9DhVDriKLi481WYkm4AIV1HYf0lpOjMtYjDgMjIrlGcJlDEq6qz6NqDoL3BFwDcC6eqmOysxoK9wDl8sM1+xgFHZpK69E4/IUOGqL9lg6krrybUfz7cqcGtmv9K4z6I0o6qM4KOxUO91KMNClUAHKwOhPfs1kHTeBek60rIWdQ6MhL02uSMjmwynTQjiL8QWF6D6TVmb6NfP6QZ0sx+0QX9LnO/1ewHSNB1L06JVWJXO3noDowRlBsOU5ylCO6af9OsVN7O6M/wBF9DYiupIphGU2ZajCme1Q9riXD1UxX2EPZWpH+Oeg0MPSZmarTJZ9pJY68Rc3G0mwIvLNToHDMLqra2tZiLdt768raTlHWg1vsdJack9tzzNuqmM3Ur9lSmf45EequN/u7dzIfY03uP6smxNB1zbkqggH/uINO9e+Y3H4nFUXKVMLlYa6OSCNxVgtmHMGdo4S/wCWcpOcfaKJ6rY3+7VO4X9kBurGM34at+Rj7BLH9fuNtBh2VB8IQ6zMP2dUdlQfGbwXZnyPo579XsWP/bV/8t/hIW6FxI24et/lP8J2R1sYfVxA/EP90NeuDjfiB4+5pcPsnkfRn26IxA20ao/7bj3Qf6vqj6jjtVh7pp167MP2lcdzQ16+MP29Qdqv8Iw+y+R9GXGGcfVb1x/JtwPrmtXr8394bvVvesL+3n/yR4D/AGyeN9l8v0aip1fTc9RfBh6zKdTq431a/iGHsW01QIiIWeXCPR0yZiKnVmuPRZW7GQnwveU8R0HiB6VMkfdt6yJvzTWMKdvRJHZp7IwQs80OEqD6rDxPsj4bR1LW0ZTqDsU3O3snpLhjtbN94B/3gZwuta2weIORARRexAykXUi4ykDfwjx7+zLo8nwtZ6zPUZz5xbKhawYbwATqbcp1MJig9MsxOYXB5nieJtaZzFUiqpl0KqD2EWYnxJnTwWMCOXPoNlca2GYi5X1jwnuWxykrO714b/8Ajwy3vZ/O5HISB6zNf/RlVVKS8fJqANLm5ubX7J5ti67VsNVYsWy1hVG/T0GtyGdfCaPqDjlKojBWFipDAMDbVbg6HUCefXtRTXDOuj7aPZUxqbD5rWBIJswvrqJYXEc/GYgU0HojILk2XQC+ug2AQkZx6Ln1j2GeRaz5R6Hpmox+AWqc4sHAAVtdADmtpzkfRWOcO9J0c5LHMcpGttmtz+onITpF0U53AFj532d5bZuAMwGJ69Yt61sO2SihORMilmta5qM6k3vfZbUntPWHzdxOctlTPbQ4OoN/nhK+IoZtR5p4j3zM9VOs4xA89ctQEJUXZZtxt8+qbFVESttozdbnIak42EXHL3jdANequ4kcmv6mE6r1UDBCwDEXC31te17cL6XgK9NmKh1LL6S3Fx2jaJzenJeja1FyiiuNB2mx56fp65KKvM+7xlg0Va4BB4i4Mj+ggarcdky1NFyiQsoMjbDiWfIHeO8aH4QhQO49xmWmzWSRzzQIjZAfSFuYHtG/2y+yEbRaC1OZxo1kmc5qFjY/oRxEjehpOg9PS272HiJXdZlxNJnNFKx2SxhR57ru0PiAffGci8q4HFDO7nS5vruFgBe+w5Qt+d5EitnWYAbdZzceMylbkEXKkbVPI8DvEiPS6OVWmS+d/J5kBdVbS+Zl0AAIuZRr41Uy+WqJT1qh0Vs7lQtqbIU0BvrZuV51jCV7bHNuPJx8R035NslViG+5mBHHYZH/AF/QO1076fxSc3pWn5TU5ygRAazU1Qu4dtQim3oOo26+T5TmnouluxP5qTD2Ez3wk2uzyzjFPo0h6Uwx2+QPaij3CL6RhD9TDH8o9hmZ/qf7OJontzr7Ugnoar9WpRbsqgfvWm7l0YqPZqhSwjfsqJ7GI9jRHozCn9gO6o3xmW/qfE/YV+ypTb+KGnR2IXbhn7kDeyRya4KoJ8mjfoLCH9k47HPvEi/s7hPsVPzD/bOMisvpUqq/gdfZaS+WX7bjlnqf7pl61e0zXi6Z6SS0WcwysE37ZzNA+UjirGNoBQSgl8oJxuti5sFiFBP/ACn7TYXt6p0jT5yvjKLMjKNbjZx5d8qIeMvQLtkG+5B/F8JTcjLlOoBHqLAeoS7jiaTkC9xcC+hBtbUcbhvCc7KSco2lQf4t3bPScjQdAuhzKw8zIwZRvQiz94Us3aokvQuAqUK709pQq6sNjqdVdeRA9o3Sn1eq5FqMBmYoUUAXyh7B3PYtx3zS9WesKU2FPEAFQbI5+qt7lGI1y6mx3XnLUTcWkdINJps1dDM6Z11sSrr9ZSNL23qdt+cZK00i4HD4hQ1BgjAXsD69Dr2gzkY7o6onppmH2l0Pew/iE8EtNo9UZpnC63Y0pg3ttcAbbXDOFtfdsaeY4nMECrc7L8ydl+7XtJnoXX03wwIFlD0lHZffzuT4zEMMqVDa9sunEbP4Z6/x1UTjqbujp9Sel2SsFdrm4pseKn0CfusLX4MJ710Tjcyi+20+ZMCQjnQgsARc7BcMRz2bZ7d0H0q2RKirmzKrEXANyPOAvodb8Jn8j4tSRNP5JxNp0hgVqqQwUm1gTe20MAcpBtcDfMZiaWJU1Fq4LOjFCDSq+bZFyrqSDa3GazCdMo41DIRtVhqPDQ9oJEteWU7GHePfM+RP0xi17R54vSD5qmfC4pC1TPem6C9hbKSLkr4yel0wo84DFowqNUKLSID5iCEZtfNFiO/ZNpXIAu2W3HPb2icmp0vg72OJoqeBq0T/ABTL1H0aUUeV4zp3phXPkmrqpa4zDMAu4WcHbt8Oc3PVfH9I1QPKVU55kW/goHtnZGNw59HEYZvxp7mgHGKuoFFuauv+6cpzk62r9HRRivs0OHWsBZzTbjlVk9RZvbJHoDdp6x4fC0zI61quhH+r9JZwnWZKhACtc7wQQO2bzi0csJJmN/pF69thXOGw+XygAzvty3FwACLA2tx223TzKp1xx7Nf6TUvwDEDwvaQ9bcSz4zEs23y1Tu886S9Q6zUloCl9FQkLlJu1mNiMxF7A91+c9cYJRVKzMXbdujo9Df0g1gQmJIdGIBcABgOYGjLsuLXtfbsmj6RwxxJ8lmJRxeymwYHXMSNu4jdPIzPQ+qXS9RcMqoQrAuhfKC2VQGABOzRrdwnLX0kllHY1pTv4s0/RHVBMLTYPiHVGIYg1CguNmwgHwh0sVhEOTDUGrvxsct+JZgfUO+ZPFdKpmz1HFQg/XqEfE25C0jr9eXVclJ0pjcKdMetnzEzhhOXu2dcoxNzV6MrVxnxTqiLqqJoAdxJ3n50nn2J6IrF3alW8zM2UE7BfZqJyU60YlnBqVndCQGDEbCdoA2TT4LEBFIY7WJ7tJ0UZaP9MScZo4rdHYwbGVvyyF6WMG2mD+E+4zVDGpxHeI/lUPD575pfkS5Rz8aMecViF9Kie7MPdEvTFRdqOOxv0E2N13E9zGA1IHee8A+2bX5C5RPEZmn1nqL9esvf/wCUsf2wqf8AWqeBnXfAKdyHtUe6QnotPsJ/q+M2taDM+NnsIxdFvTTKeK/CGMAra03VuR0M4144Pz+s5mqL1fCsvpKRz2jxEqkCWKHSdVfrXHBtfXthVMajenTAPFdPnvvIUpMfn+crVqxEtVMv1Sewyu4G8Sg87634akajVHJTMAdADnYDVRc6HS427W0mBq4g5yw01Jtw5eGk92xvRtKqpVkVwdxAPtnBr9SsIf2QHYWHvtOsZpLcw4mH6B6xUKfm1sMtQfaDMlQdjA29Qmi8lgMSP+FXVGP1K4C9wdSB4kmS4rqNRt5otODjupbrqkuUWSmjpjBdIYRr0VcoNQF/4iHmuXzh6p3ujv6TK6WXE0H00JysfaAw9cwC/TcN5qs+X7J85PynS/PbIMR0iahHlM9M72VmK/5ZN+8HulxT9i2jf9c+sOExOGPkSFfOjMl94cH0SAdxvpMZhnF3Unabe0j98SepgqLUyaOJR7KxyuclUWFz5raN3HunNxRIUOv10Dfl81h4BDCio7IuTfsPpTEq+IBVcqhAoAFvRp2OnaCZ6F1GxWbDJ/hZ1/1kj1MJ5bh2uWc/VB9ensv4TRdVesqYakyOhILswIYDaF3HsnPXg5RpGtKSjK2esCreF5crc3PjMrgut2GKjMzqSLm6MQCdbXUGVes/WimMOxoOGdhkFgwK5tCxuNLC/faeBaE26pnp8kauzhdbeuLPWZEAemhtqTZ3HpNzAOg7L75xB1lqDYieucJVhlZ9KOjBKqPK9STdnZPWWofqJ4fpE3T7/YTwHwnIVJIyaWl8UeiZy7NX1ZxX0mp5NzlaxZRuYDaO3fbhPSujUWmLDaJ4p0VivI1qdT7Dgn7t7N/pJnp/9psIdmITvJHtE8f5Gm1JYrY76U01ueb9bKGTG4gcajP3P549TCcgpNT11qUXqpVSojhkyvlIazIdCQNlww/LOCgB2BjYXNgdgHOezTbcUzzyVSZRYTVdHkpgi4NiXffroik90z7UCxAVW1O/SdLpDpICkKCg+bmDE7MxNmtx0CjulnHJUIunZw211O2MRHLwC00Qdd/zvnoPRdLyiEm4KEK2mgbKCRmGh7uMwVOmWI0LXOwasRyAnpXU7pHEUEYBGpZnzm9iXJ/wEeaAAoE56sbRuLorP0dwIkZ6PYTZjp1m9OnSf7yC/iLQxisM3p4YDmjsvq2ThX0dLMOcKw3HxjZXG9hNwcLg22GtT/Kw+MY9B0G9DEp+NCvrmaQsxS1H4w87cZrX6pufQak/3X19dpVfqlXv/wAlu4raMEWzURCMRGvNGCS0aCH7oWaALLFljXizQAWpwcsItBzQBFeXhI3pqd/jJM0R1gFGv0erbQDOLj+rNF9qWPETSlOBgMSNovNJtEo806Q6knUoQZToYXyIFPEqwS/mutroe/TZcWOh4jSeqMqndKuL6Np1FKuqsDuIvNKb5MuJ5D0zVpL5lEHKdSTa7HjYEgAbALnadZD0XjEQEMoNydWRXAuBYhWIF7jj3GehYnqJh2JKqw7HPsJnPrdQUHo5u8mdFOJMTJHCUDquJUHgyOp8QCPXDo4MA+biKB4gu1iN4IZbEWnZrdRnHohT+Iym/UrE7kX881kuyUcrH4BUN0q02v8AVV75TvAJ0I9co+QbgfEfGd49TMT9hfzCD/YzE/ZX8wjJdlpnDNNwLkG3bBDN9r/UPjO+OpmJ+yv5hJF6l4jeUHefhGS7JRwad76stgQdSDs5HQ98vVscrelTw7cSFKE/kYD1TqDqRV+2g/N8JKvUWpvqL4GMo9lozVWslwUXIRwYsPArf1wfpj/b8B+k1adRuNXwX9ZPT6j099Rj3Ae2TNCjEmqx+s1vnnAZrz0Sl1Mww2lz3j3CXqHVXCj6l/vEmTyIYs8tA5e2T0sLUb0UY9imeu4foaivo00HMCXUwijZp3CR6v0XE8z6MwmOAsiZV5oF9dgZqOjuj8T+0t+G81SUBy9ntk607bj4XnNysqicijhG/nLS4b/CJ0FIkgI4SGiguHHAx/ow4zoC0fKJAc/6LHAcaAm3aZe8mOMXkYBIY149+/2wWEgGMDNblHMAmUEgePeVyOGkWfjALN4JtIQ8LykAPLGymNCDQAbxg3OSixjNTgETfNoJEMoYBHGUDBjCWpGtEVkAeUGA1AfziyxByIABoH51kbUuUsiqN8PMIBRKCNk75eKCRtSgFXyS8LRDDjcZOyGBaCEbUDwkZpDhLQvHzneJQUvIiMaJl6yndG8kNxgFEIRJkdhLBpntglBvEAZK3KTLUHZK5TnEUMAuq44+MKw4Du0lC54QlqQUuWHP2xZeYlcVTC8rAJTm+dYOcwA8LyvOASq0Mtx8ZT1Gz9Ia1v5b+6QFhhAjK/A/POOdeRkABEAx2EbNKAY94141pQPeEKkDNERf590AkDSRX75V1EJXkBbzRivCQq4hB4AmXlaNDDwWAgA3jeuJge2DeUBGDl7o+Yxs3dAHDkR1qwL/ACIJMgLAcRiAZXzd0cOeMUCY0+EYqRIxU4whU5wBXj24R8/ERZRAFmizRisEiAGbcIJQcbdsCK5lIEVbkYBI3iLPCz8/HWABlHGKxjm3DwgleB8YA+blG8p2+EYg9sHN2wCbN48OPZBz/PzsiigoQf8AnvHbJBV4+O79IooAebvgsvCNFICJjaMH7/ndFFKBw8cmKKAK5+dv6wb/AD+kUUAcfP8AKOGtFFACFSEG74ooA/lBv9fxiMaKQAlOB+e2ASRt+e+PFKAC47PnjESe2KKANeCfm3wMUUAbOe2LOOyKKCDhiPm0Ly3H16RRQUIVpItQGKKAESIJpxRSAEoe2RkdoiilAtdxvBNQjaIooIMKg/lCz84ooB//2Q==",
"source":"caranddriver.com",
"title":"El Bugatti Chiron Super Sport se pone a tono: Objetivo, los ¡440 km/h!",
"link":"https://www.caranddriver.com/es/coches/planeta-motor/a36812435/bugatti-chiron-super-sport-pruebas-velocidad/",
"original":"https://hips.hearstapps.com/hmg-prod.s3.amazonaws.com/images/02-hispeed-css-1624449602.jpg"
},
{
"thumbnail":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS3xUD75WQBPu68wKkS9yGm7Yla62hRKuv4kQ&usqp=CAU",
"source":"motor.es",
"title":"El Bugatti Chiron Super Sport, a la caza de nuevos clientes en la Costa Azul",
"link":"https://www.motor.es/noticias/bugatti-chiron-super-sport-costa-azul-202180151.html",
"original":"https://static.motor.es/fotos-noticias/2021/08/bugatti-chiron-super-sport-202180151-1628105578_1.jpg"
}
... and other results
]
Using Google Images API from SerpApi
This section is to show the comparison between the DIY solutions and our solution.
The biggest difference is that you don't need to use browser automation to scrape all results, create the parser from scratch and maintain it.
This solution combines the advantages of the solutions shown above, namely the speed and completeness of obtaining results.
There's also a chance that the request might be blocked at some point from Google, we handle it on our backend so there's no need to figure out how to do it yourself or figure out which CAPTCHA, proxy provider to use.
First, we need to install google-search-results-nodejs:
npm i google-search-results-nodejs
Here's the full code example, if you don't need an explanation:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY); //your API key from serpapi.com
const searchQuery = "bugatti chiron";
const params = {
q: searchQuery, // what we want to search
engine: "google", // search engine
hl: "en", // parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
tbm: "isch", // parameter defines the type of search you want to do (isch - Google Images)
};
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const imagesResults = [];
while (true) {
const json = await getJson();
if (json.images_results) {
imagesResults.push(...json.images_results);
params.ijn ? (params.ijn += 1) : (params.ijn = 1);
} else break;
}
return imagesResults;
};
getResults().then((result) => console.dir(result, { depth: null }));
Code explanation
First, we need to declare SerpApi from google-search-results-nodejs library and define new search instance with your API key from SerpApi:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
Next, we write what we want to search and the necessary parameters for making a request:
const searchQuery = "bugatti chiron";
const params = {
q: searchQuery, // what we want to search
engine: "google", // search engine
hl: "en", // parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
tbm: "isch", // parameter defines the type of search you want to do (isch - Google Images)
};
Next, we wrap the search method from the SerpApi library in a promise to further work with the search results:
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
And finally, we declare the function getResult that gets data from the page and return it:
const getResults = async () => {
...
};
In this function first, we declare an array imagesResults with results data:
const imagesResults = [];
Next, we need to use while loop. In this loop we get json with results, check if results are present on the page, push results to imagesResults array, define the start number on the results page (ijn parameter), and repeat the loop until results aren't present on the page:
while (true) {
const json = await getJson();
if (json.images_results) {
imagesResults.push(...json.images_results);
params.ijn ? (params.ijn += 1) : (params.ijn = 1);
} else break;
}
return imagesResults;
After, we run the getResults function and print all the received information in the console with the console.dir method, which allows you to use an object with the necessary parameters to change default output options:
getResults().then((result) => console.dir(result, { depth: null }));
Output
[
{
"position":1,
"thumbnail":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT-6pU_hnLtboVfXcuihXvzyP8xRsDJ8fs3zw&usqp=CAU",
"source":"topspeed.com",
"title":"2018 Bugatti Chiron | Top Speed",
"link":"https://www.topspeed.com/cars/bugatti/2018-bugatti-chiron-ar163150.html",
"original":"https://pictures.topspeed.com/IMG/crop_webp/201602/2018-bugatti-chiron-10_1920x1080.webp",
"is_product":false
},
{
"position":2,
"thumbnail":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR_1JAV4au_ZTCjcPk41Ul9blo0XHsJwxt50Q&usqp=CAU",
"source":"auto-data.net",
"title":"2021 Bugatti Chiron Super Sport 8.0 W16 (1600 Hp) AWD DSG | Technical specs, data, fuel consumption, Dimensions",
"link":"https://www.auto-data.net/en/bugatti-chiron-super-sport-8.0-w16-1600hp-awd-dsg-43596",
"original":"https://www.auto-data.net/images/f115/Bugatti-Chiron-Super-Sport.jpg",
"is_product":false
},
... and other results
]
Links
If you want to see some projects made with SerpApi, please write me a message.
Add a Feature Request💫 or a Bug🐞

Top comments (0)