
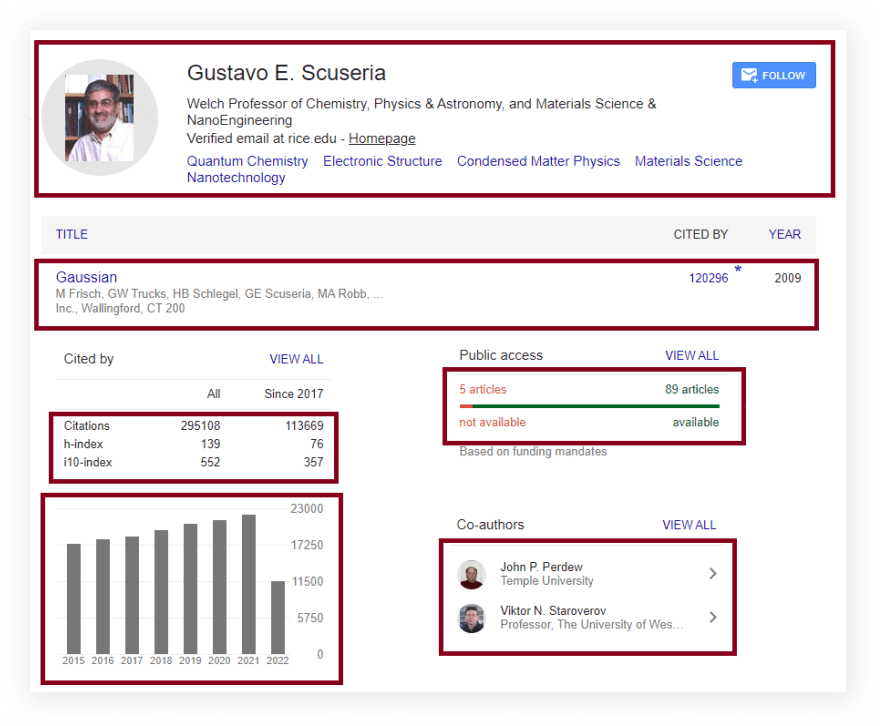
What will be scraped
Preparation
First, we need to create a Node.js* project and add npm packages puppeteer, puppeteer-extra and puppeteer-extra-plugin-stealth to control Chromium (or Chrome, or Firefox, but now we work only with Chromium which is used by default) over the DevTools Protocol in headless or non-headless mode.
To do this, in the directory with our project, open the command line and enter npm init -y, and then npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth.
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
📌Note: also, you can use puppeteer without any extensions, but I strongly recommended use it with puppeteer-extra with puppeteer-extra-plugin-stealth to prevent website detection that you are using headless Chromium or that you are using web driver. You can check it on Chrome headless tests website. The screenshot below shows you a difference.

Process
SelectorGadget Chrome extension was used to grab CSS selectors by clicking on the desired element in the browser. If you have any struggles understanding this, we have a dedicated Web Scraping with CSS Selectors blog post at SerpApi.
The Gif below illustrates the approach of selecting different parts of the results.

📌Note: you can get user ID from Google Scholar using my guide How to scrape Google Scholar profiles results with Node.js.
Full code
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const requestParams = {
user: "6ZiRSwQAAAAJ", // the ID of the author we want to scrape
hl: "en", // parameter defines the language to use for the Google search
};
const domain = `http://scholar.google.com`;
async function getArticles(page) {
while (true) {
await page.waitForSelector("#gsc_bpf_more");
const isNextPage = await page.$("#gsc_bpf_more:not([disabled])");
if (!isNextPage) break;
await page.click("#gsc_bpf_more");
await page.waitForTimeout(5000);
}
return await page.evaluate(async () => {
const articles = document.querySelectorAll(".gsc_a_tr");
const articleInfo = [];
for (const el of articles) {
articleInfo.push({
title: el.querySelector(".gsc_a_at").textContent.trim(),
link: await window.buildValidLink(el.querySelector(".gsc_a_at").getAttribute("href")),
authors: el.querySelector(".gs_gray:first-of-type").textContent.trim(),
publication: el.querySelector(".gs_gray:last-of-type").textContent.trim(),
citedBy: {
link: el.querySelector(".gsc_a_ac").getAttribute("href"),
cited: el.querySelector(".gsc_a_ac").textContent.trim(),
},
year: el.querySelector(".gsc_a_h").textContent.trim(),
});
}
return articleInfo;
});
}
async function getScholarAuthorInfo() {
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
const URL = `${domain}/citations?hl=${requestParams.hl}&user=${requestParams.user}`;
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".gsc_a_tr");
await page.waitForTimeout(1000);
await page.exposeFunction("buildValidLink", (rawLink) => {
if (!rawLink || rawLink.includes("javascript:void(0)")) return "link not available";
if (rawLink.includes("scholar.googleusercontent")) return rawLink;
return domain + rawLink;
});
const articles = await getArticles(page);
const scholarAuthorInfo = await page.evaluate(async (articles) => {
const interests = [];
const interstsSelectors = document.querySelectorAll("#gsc_prf_int a");
for (const interest of interstsSelectors) {
interests.push({
title: interest.textContent.trim(),
link: await window.buildValidLink(interest.getAttribute("href")),
});
}
const coAuthors = [];
const coAuthorsSelectors = document.querySelectorAll("#gsc_rsb_co .gsc_rsb_aa");
for (const coAuthor of coAuthorsSelectors) {
const link = await window.buildValidLink(coAuthor.querySelector(".gsc_rsb_a_desc a").getAttribute("href"));
const authorIdPattern = /user=(?<id>[^&]+)/gm; //https://regex101.com/r/oxoQEj/1
const authorId = link.match(authorIdPattern)[0].replace("user=", "");
coAuthors.push({
name: coAuthor.querySelector(".gsc_rsb_a_desc a").textContent.trim(),
link,
authorId,
photo: await window.buildValidLink(coAuthor.querySelector(".gs_pp_df").getAttribute("data-src")),
affiliations: coAuthor.querySelector(".gsc_rsb_a_ext").textContent.trim(),
email: coAuthor.querySelector(".gsc_rsb_a_ext2")?.textContent.trim() || "email not available",
});
}
return {
name: document.querySelector("#gsc_prf_in").textContent.trim(),
photo: await window.buildValidLink(document.querySelector("#gsc_prf_pup-img").getAttribute("src")),
affiliations: document.querySelector(".gsc_prf_il:nth-child(2)").textContent.trim(),
website: document.querySelector(".gsc_prf_ila").getAttribute("href") || "website not available",
interests,
articles,
table: {
citations: {
all: document.querySelector("#gsc_rsb_st tr:nth-child(1) td:nth-child(2)").textContent.trim(),
since2017: document.querySelector("#gsc_rsb_st tr:nth-child(1) td:nth-child(3)").textContent.trim(),
},
hIndex: {
all: document.querySelector("#gsc_rsb_st tr:nth-child(2) td:nth-child(2)").textContent.trim(),
since2017: document.querySelector("#gsc_rsb_st tr:nth-child(2) td:nth-child(3)").textContent.trim(),
},
i10Index: {
all: document.querySelector("#gsc_rsb_st tr:nth-child(3) td:nth-child(2)").textContent.trim(),
since2017: document.querySelector("#gsc_rsb_st tr:nth-child(3) td:nth-child(3)").textContent.trim(),
},
},
graph: Array.from(document.querySelectorAll(".gsc_md_hist_b .gsc_g_t")).map((el, i) => {
return {
year: el.textContent.trim(),
citations: document.querySelectorAll(".gsc_md_hist_b .gsc_g_al")[i].textContent.trim(),
};
}),
publicAccess: {
link: await window.buildValidLink(document.querySelector("#gsc_lwp_mndt_lnk").getAttribute("href")),
available: document.querySelectorAll(".gsc_rsb_m_a")[0].textContent.trim(),
notAvailable: document.querySelectorAll(".gsc_rsb_m_na")[0].textContent.trim(),
},
coAuthors,
};
}, articles);
await browser.close();
return scholarAuthorInfo;
}
getScholarAuthorInfo().then((result) => console.dir(result, { depth: null }));
Code explanation
Declare constants from required libraries:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
| Code | Explanation |
|---|---|
puppeteer |
Chromium control library |
StealthPlugin |
library for prevent website detection that you are using web driver |
Next, we "saying" to puppeteer use StealthPlugin:
puppeteer.use(StealthPlugin());
Next, we write user ID and the necessary parameters for making a request:
const requestParams = {
user: "6ZiRSwQAAAAJ", // the ID of the author we want to scrape
hl: "en", // parameter defines the language to use for the Google search
};
const domain = `http://scholar.google.com`;
| Code | Explanation |
|---|---|
user |
user ID from Google Scholar |
hl |
parameter defines the language to use for the Google search |
Next, we write down a function for getting articles from the page:
async function getArticles(page) {
while (true) {
await page.waitForSelector("#gsc_bpf_more");
const isNextPage = await page.$("#gsc_bpf_more:not([disabled])");
if (!isNextPage) break;
await page.click("#gsc_bpf_more");
await page.waitForTimeout(5000);
}
return await page.evaluate(async () => {
const articles = document.querySelectorAll(".gsc_a_tr");
const articleInfo = [];
for (const el of articles) {
articleInfo.push({
title: el.querySelector(".gsc_a_at").textContent.trim(),
link: await window.buildValidLink(el.querySelector(".gsc_a_at").getAttribute("href")),
authors: el.querySelector(".gs_gray:first-of-type").textContent.trim(),
publication: el.querySelector(".gs_gray:last-of-type").textContent.trim(),
citedBy: {
link: el.querySelector(".gsc_a_ac").getAttribute("href"),
cited: el.querySelector(".gsc_a_ac").textContent.trim(),
},
year: el.querySelector(".gsc_a_h").textContent.trim(),
});
}
return articleInfo;
});
}
| Code | Explanation |
|---|---|
page.waitForSelector("#gsc_bpf_more") |
stops the script and waits for the html element with the #gsc_bpf_more selector to load |
page.click("#gsc_bpf_more") |
this methods emulates mouse click on the html element with the #gsc_bpf_more selector |
page.waitForTimeout(5000) |
waiting 5000 ms before continue |
articleInfo |
an array with information about all articles from the page |
page.evaluate(async () => { |
is the Puppeteer method for injecting function in the page context and allows to return data directly from the browser |
document.querySelectorAll(".gsc_a_tr") |
returns a static NodeList representing a list of the document's elements that match the css selectors with class name gsc_a_tr
|
el.querySelector(".gsc_a_at") |
returns the first html element with class name gsc_a_at which is any child of the el html element |
.trim() |
removes whitespace from both ends of a string |
window.buildValidLink |
is the function injected in the browser's window context in getScholarAuthorInfo function. More info in getScholarAuthorInfo explanation section |
.getAttribute("href") |
gets the href attribute value of the html element |
And finally, a function to control the browser, and get main information about the author:
async function getScholarAuthorInfo() {
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
const URL = `${domain}/citations?hl=${requestParams.hl}&user=${requestParams.user}`;
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".gsc_a_tr");
await page.waitForTimeout(1000);
await page.exposeFunction("buildValidLink", (rawLink) => {
if (!rawLink || rawLink.includes("javascript:void(0)")) return "link not available";
if (rawLink.includes("scholar.googleusercontent")) return rawLink;
return domain + rawLink;
});
const articles = await getArticles(page);
const scholarAuthorInfo = await page.evaluate(async (articles) => {
const interests = [];
const interstsSelectors = document.querySelectorAll("#gsc_prf_int a");
for (const interest of interstsSelectors) {
interests.push({
title: interest.textContent.trim(),
link: await window.buildValidLink(interest.getAttribute("href")),
});
}
const coAuthors = [];
const coAuthorsSelectors = document.querySelectorAll("#gsc_rsb_co .gsc_rsb_aa");
for (const coAuthor of coAuthorsSelectors) {
const link = await window.buildValidLink(coAuthor.querySelector(".gsc_rsb_a_desc a").getAttribute("href"));
const authorIdPattern = /user=(?<id>[^&]+)/gm; //https://regex101.com/r/oxoQEj/1
const authorId = link.match(authorIdPattern)[0].replace("user=", "");
coAuthors.push({
name: coAuthor.querySelector(".gsc_rsb_a_desc a").textContent.trim(),
link,
authorId,
photo: await window.buildValidLink(coAuthor.querySelector(".gs_pp_df").getAttribute("data-src")),
affiliations: coAuthor.querySelector(".gsc_rsb_a_ext").textContent.trim(),
email: coAuthor.querySelector(".gsc_rsb_a_ext2")?.textContent.trim() || "email not available",
});
}
return {
name: document.querySelector("#gsc_prf_in").textContent.trim(),
photo: await window.buildValidLink(document.querySelector("#gsc_prf_pup-img").getAttribute("src")),
affiliations: document.querySelector(".gsc_prf_il:nth-child(2)").textContent.trim(),
website: document.querySelector(".gsc_prf_ila").getAttribute("href") || "website not available",
interests,
articles,
table: {
citations: {
all: document.querySelector("#gsc_rsb_st tr:nth-child(1) td:nth-child(2)").textContent.trim(),
since2017: document.querySelector("#gsc_rsb_st tr:nth-child(1) td:nth-child(3)").textContent.trim(),
},
hIndex: {
all: document.querySelector("#gsc_rsb_st tr:nth-child(2) td:nth-child(2)").textContent.trim(),
since2017: document.querySelector("#gsc_rsb_st tr:nth-child(2) td:nth-child(3)").textContent.trim(),
},
i10Index: {
all: document.querySelector("#gsc_rsb_st tr:nth-child(3) td:nth-child(2)").textContent.trim(),
since2017: document.querySelector("#gsc_rsb_st tr:nth-child(3) td:nth-child(3)").textContent.trim(),
},
},
graph: Array.from(document.querySelectorAll(".gsc_md_hist_b .gsc_g_t")).map((el, i) => {
return {
year: el.textContent.trim(),
citations: document.querySelectorAll(".gsc_md_hist_b .gsc_g_al")[i].textContent.trim(),
};
}),
publicAccess: {
link: await window.buildValidLink(document.querySelector("#gsc_lwp_mndt_lnk").getAttribute("href")),
available: document.querySelectorAll(".gsc_rsb_m_a")[0].textContent.trim(),
notAvailable: document.querySelectorAll(".gsc_rsb_m_na")[0].textContent.trim(),
},
coAuthors,
};
}, articles);
await browser.close();
return scholarAuthorInfo;
}
| Code | Explanation |
|---|---|
puppeteer.launch({options}) |
this method launches a new instance of the Chromium browser with current options
|
headless |
defines which mode to use: headless (by default) or non-headless |
args |
an array with arguments which is used with Chromium |
["--no-sandbox", "--disable-setuid-sandbox"] |
these arguments we use to allow the launch of the browser process in the online IDE |
browser.newPage() |
this method launches a new page |
page.setDefaultNavigationTimeout(60000) |
changing default (30 sec) time for waiting for selectors to 60000 ms (1 min) for slow internet connection |
page.goto(URL) |
navigation to URL which is defined above |
page.exposeFunction("buildValidLink", injectedFunction) |
inject injectedFunction with "buildValidLink" name in the browser's window context. This function helps us change the raw links to the correct links. We need to do this with links because they are of different types. For example, some links start with "/citations", some already have a complete and correct link, and some no links |
authorIdPattern |
a RegEx pattern for search and define author id. See what it allows you to find |
link.match(authorIdPattern)[0].replace('user=', '') |
here we find a substring that matches authorIdPattern, take 0 element from the matches array and remove "user=" part |
browser.close() |
after all we close the browser instance |
Now we can launch our parser. To do this enter node YOUR_FILE_NAME in your command line. Where YOUR_FILE_NAME is the name of your .js file.
Output
{
"name":"Gustavo E. Scuseria",
"photo":"https://scholar.googleusercontent.com/citations?view_op=medium_photo&user=6ZiRSwQAAAAJ&citpid=2",
"affiliations":"Welch Professor of Chemistry, Physics & Astronomy, and Materials Science & NanoEngineering",
"website":"http://scuseria.rice.edu/",
"interests":[
{
"title":"Quantum Chemistry",
"link":"http://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:quantum_chemistry"
},
{
"title":"Electronic Structure",
"link":"http://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:electronic_structure"
},
... and other interests
],
"articles":[
{
"title":"Gaussian",
"link":"http://scholar.google.com/citations?view_op=view_citation&hl=en&user=6ZiRSwQAAAAJ&citation_for_view=6ZiRSwQAAAAJ:zYLM7Y9cAGgC",
"authors":"M Frisch, GW Trucks, HB Schlegel, GE Scuseria, MA Robb, ...",
"publication":"Inc., Wallingford, CT 200, 2009",
"citedBy":{
"link":"https://scholar.google.com/scholar?oi=bibs&hl=en&cites=12649774174384111814,14968720898351466124,2542640079890340298,8878124810051097364,2098631159866273549,2628790197996155063,9956613247733821950,12319774160759231510,10858305733441610093,6078020929247912320,732977129500792336,14993646544388831080,15565517274675135746,15250043469802589020,1808091898519134639,4924449844119900931,7042231487572549326,15997103006766735356,1383260141329079090,9449439637290636341,15798026778807799939,8499548159092922473,17327920478782103127,17012586779140016045,15565399274538950872,3036342632434523386,551261585751727105,149700165324054213,2578529946445560518",
"cited":"120296"
},
"year":"2009"
},
{
"title":"Gaussian 03, revision C. 02",
"link":"http://scholar.google.com/citations?view_op=view_citation&hl=en&user=6ZiRSwQAAAAJ&citation_for_view=6ZiRSwQAAAAJ:oC1yQlCKEqoC",
"authors":"MJ Frisch, GW Trucks, HB Schlegel, GE Scuseria, MA Robb, ...",
"publication":"Gaussian, Inc., Wallingford, CT, 2004",
"citedBy":{
"link":"https://scholar.google.com/scholar?oi=bibs&hl=en&cites=5576070979585392002,14227769557982606857",
"cited":"25832"
},
"year":"2004"
},
... and other articles
],
"table":{
"citations":{
"all":"295108",
"since2017":"113669"
},
"hIndex":{
"all":"139",
"since2017":"76"
},
"i10Index":{
"all":"552",
"since2017":"357"
}
},
"graph":[
{
"year":"1993",
"citations":"771"
},
{
"year":"1994",
"citations":"782"
},
... and other years
],
"publicAccess":{
"link":"http://scholar.google.com/citations?view_op=list_mandates&hl=en&user=6ZiRSwQAAAAJ",
"available":"89 articles",
"notAvailable":"5 articles"
},
"coAuthors":[
{
"name":"John P. Perdew",
"link":"http://scholar.google.com/citations?user=09nv75wAAAAJ&hl=en",
"author_id":"09nv75wAAAAJ",
"photo":"https://scholar.googleusercontent.com/citations?view_op=small_photo&user=09nv75wAAAAJ&citpid=2",
"affiliations":"Temple UniversityVerified email at temple.edu",
"email":"Verified email at temple.edu"
},
{
"name":"Viktor N. Staroverov",
"link":"http://scholar.google.com/citations?user=eZqrRYEAAAAJ&hl=en",
"author_id":"eZqrRYEAAAAJ",
"photo":"https://scholar.googleusercontent.com/citations?view_op=small_photo&user=eZqrRYEAAAAJ&citpid=2",
"affiliations":"Professor, The University of Western OntarioVerified email at uwo.ca",
"email":"Verified email at uwo.ca"
},
... and other co-authors
]
}
Google Scholar Author API
Alternatively, you can use the Google Scholar Author API from SerpApi. SerpApi is a free API with 100 search per month. If you need more searches, there are paid plans.
The difference is that you won't have to write code from scratch and maintain it. You may also experience blocking from Google and changing selectors which will break the parser. Instead, you just need to iterate the structured JSON and get the data you want. Check out the playground.
First we need to install google-search-results-nodejs. To do this you need to enter in your console: npm i google-search-results-nodejs
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY); //your API key from serpapi.com
const user = "6ZiRSwQAAAAJ"; // the ID of the author we want to scrape
const params = {
engine: "google_scholar_author", // search engine
author_id: user, // author ID
hl: "en", // Parameter defines the language to use for the Google search
num: "100", // Parameter defines the number of search results per page
};
const getArticlesFromPage = ({ articles }) => {
return articles?.map((article) => {
const { title, link = "link not available", authors, publication, cited_by, year } = article;
return {
title,
link,
authors,
publication,
citedBy: {
link: cited_by.link,
cited: cited_by.value,
},
year,
};
});
};
const getScholarAuthorData = function ({ author, articles, cited_by, public_access: publicAccess, co_authors }) {
const { name, thumbnail: photo, affiliations, website = "website not available", interests } = author;
const { table, graph } = cited_by;
return {
name,
photo,
affiliations,
website,
interests:
interests?.map((interest) => {
const { title, link = "link not available" } = interest;
return {
title,
link,
};
}) || "no interests",
articles: getArticlesFromPage({articles}),
table: {
citations: {
all: table[0].citations.all,
since2017: table[0].citations.since_2017,
},
hIndex: {
all: table[1].h_index.all,
since2017: table[1].h_index.since_2017,
},
i10Index: {
all: table[2].i10_index.all,
since2017: table[2].i10_index.since_2017,
},
},
graph,
publicAccess,
coAuthors: co_authors?.map((result) => {
const { name, link = "link not available", thumbnail: photo, affiliations, email = "no email info", author_id } = result;
return {
name,
link,
author_id,
photo,
affiliations,
email,
};
}),
};
};
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const json = await getJson(params);
const scholarAuthorData = getScholarAuthorData(json);
let nextPage = json.serpapi_pagination?.next;
if (nextPage) params.start = 0;
while (nextPage) {
params.start += 100;
const json = await getJson(params);
nextPage = json.serpapi_pagination?.next;
scholarAuthorData.articles.push(...getArticlesFromPage(json));
}
return scholarAuthorData;
};
getResults.then((result) => console.dir(result, { depth: null }));
Code explanation
Declare constants from required libraries:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
| Code | Explanation |
|---|---|
SerpApi |
SerpApi Node.js library |
search |
new instance of GoogleSearch class |
API_KEY |
your API key from SerpApi |
Next, we write down what we want to search and the necessary parameters for making a request:
const user = "6ZiRSwQAAAAJ";
const params = {
engine: "google_scholar_author",
author_id: user,
hl: "en",
num: "100",
};
| Code | Explanation |
|---|---|
user |
user ID from Google Scholar |
engine |
search engine |
hl |
parameter defines the language to use for the Google search |
num |
parameter defines the number of search results per page |
Next, we write down a function for getting articles from the page:
const getArticlesFromPage = ({ articles }) => {
return articles?.map((article) => {
const { title, link = "link not available", authors, publication, cited_by, year } = article;
return {
title,
link,
authors,
publication,
citedBy: {
link: cited_by.link,
cited: cited_by.value,
},
year,
};
});
};
| Code | Explanation |
|---|---|
articles |
data that we destructured from response |
title, link, ..., year |
data that we destructured from article object |
link = "link not available" |
we set default value link not available if link is undefined
|
Next, we write a callback function in which we describe what data we need from the result of our request:
const getScholarAuthorData = function ({ author, articles, cited_by, public_access: publicAccess, co_authors }) {
const { name, thumbnail: photo, affiliations, website = "website not available", interests } = author;
const { table, graph } = cited_by;
return {
name,
photo,
affiliations,
website,
interests:
interests?.map((interest) => {
const { title, link = "link not available" } = interest;
return {
title,
link,
};
}) || "no interests",
articles: getArticlesFromPage({articles}),
table: {
citations: {
all: table[0].citations.all,
since2017: table[0].citations.since_2017,
},
hIndex: {
all: table[1].h_index.all,
since2017: table[1].h_index.since_2017,
},
i10Index: {
all: table[2].i10_index.all,
since2017: table[2].i10_index.since_2017,
},
},
graph,
publicAccess,
coAuthors: co_authors?.map((result) => {
const { name, link = "link not available", thumbnail: photo, affiliations, email = "no email info", author_id } = result;
return {
name,
link,
author_id,
photo,
affiliations,
email,
};
}),
};
};
| Code | Explanation |
|---|---|
author, articles, ..., co_authors |
data that we destructured from response |
name, thumbnail, ..., interests |
data that we destructured from author object |
thumbnail: photo |
we redefine destructured data thumbnail to new photo
|
website = "website not available" |
we set default value website not available if website is undefined
|
Next, we wrap the search method from the SerpApi library in a promise to further work with the search results:
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
})
}
And finally, we declare and run the function getResult that gets main author's info and articles info from all pages and return it:
const getResults = async () => {
const json = await getJson(params);
const scholarAuthorData = getScholarAuthorData(json);
let nextPage = json.serpapi_pagination?.next;
if (nextPage) params.start = 0;
while (nextPage) {
params.start += 100;
const json = await getJson(params);
nextPage = json.serpapi_pagination?.next;
scholarAuthorData.articles.push(...getArticlesFromPage(json));
}
return scholarAuthorData;
};
getResults().then((result) => console.dir(result, { depth: null }))
| Code | Explanation |
|---|---|
scholarAuthorData.articles.push(...getArticlesFromPage(json)) |
in this code, we use spread syntax to split the array from result that was returned from getArticlesFromPage function into elements and add them in the end of scholarAuthorData.articles array |
console.dir(result, { depth: null }) |
console method dir allows you to use an object with necessary parameters to change default output options. Watch Node.js documentation for more info |
Output
{
"name":"Gustavo E. Scuseria",
"photo":"https://scholar.googleusercontent.com/citations?view_op=medium_photo&user=6ZiRSwQAAAAJ&citpid=2",
"affiliations":"Welch Professor of Chemistry, Physics & Astronomy, and Materials Science & NanoEngineering",
"website":"http://scuseria.rice.edu/",
"interests":[
{
"title":"Quantum Chemistry",
"link":"https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:quantum_chemistry"
},
{
"title":"Electronic Structure",
"link":"https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:electronic_structure"
},
... and other interests
],
"articles":[
{
"title":"Gaussian",
"link":"https://scholar.google.com/citations?view_op=view_citation&hl=en&user=6ZiRSwQAAAAJ&citation_for_view=6ZiRSwQAAAAJ:zYLM7Y9cAGgC",
"authors":"M Frisch, GW Trucks, HB Schlegel, GE Scuseria, MA Robb, ...",
"publication":"Inc., Wallingford, CT 200, 2009",
"citedBy":{
"link":"https://scholar.google.com/scholar?oi=bibs&hl=en&cites=12649774174384111814,14968720898351466124,2542640079890340298,8878124810051097364,2098631159866273549,2628790197996155063,9956613247733821950,12319774160759231510,10858305733441610093,6078020929247912320,732977129500792336,14993646544388831080,15565517274675135746,15250043469802589020,1808091898519134639,4924449844119900931,7042231487572549326,15997103006766735356,1383260141329079090,9449439637290636341,15798026778807799939,8499548159092922473,17327920478782103127,17012586779140016045,15565399274538950872,3036342632434523386,551261585751727105,149700165324054213,2578529946445560518",
"cited":120296
},
"year":"2009"
},
{
"title":"Gaussian 03, revision C. 02",
"link":"https://scholar.google.com/citations?view_op=view_citation&hl=en&user=6ZiRSwQAAAAJ&citation_for_view=6ZiRSwQAAAAJ:oC1yQlCKEqoC",
"authors":"MJ Frisch, GW Trucks, HB Schlegel, GE Scuseria, MA Robb, ...",
"publication":"Gaussian, Inc., Wallingford, CT, 2004",
"citedBy":{
"link":"https://scholar.google.com/scholar?oi=bibs&hl=en&cites=5576070979585392002,14227769557982606857",
"cited":25832
},
"year":"2004"
},
... and other articles
],
"table":{
"citations":{
"all":295108,
"since2017":113669
},
"hIndex":{
"all":139,
"since2017":76
},
"i10Index":{
"all":552,
"since2017":357
}
},
"graph":[
{
"year":1993,
"citations":771
},
{
"year":1994,
"citations":782
},
... and other years
],
"publicAccess":{
"link":"https://scholar.google.com/citations?view_op=list_mandates&hl=en&user=6ZiRSwQAAAAJ",
"available":89,
"not_available":5
},
"coAuthors":[
{
"name":"John P. Perdew",
"link":"https://scholar.google.com/citations?user=09nv75wAAAAJ&hl=en",
"author_id":"09nv75wAAAAJ",
"photo":"https://scholar.googleusercontent.com/citations?view_op=small_photo&user=09nv75wAAAAJ&citpid=2",
"affiliations":"Temple University",
"email":"Verified email at temple.edu"
},
{
"name":"Viktor N. Staroverov",
"link":"https://scholar.google.com/citations?user=eZqrRYEAAAAJ&hl=en",
"author_id":"eZqrRYEAAAAJ",
"photo":"https://scholar.googleusercontent.com/citations?view_op=small_photo&user=eZqrRYEAAAAJ&citpid=2",
"affiliations":"Professor, The University of Western Ontario",
"email":"Verified email at uwo.ca"
},
... and other co-authors
]
}
Links
If you want to see some project made with SerpApi, please write me a message.
Add a Feature Request💫 or a Bug🐞

Top comments (0)