
This is a part of the series of blog posts related to Artificial Intelligence Implementation. If you are interested in the background of the story or how it goes:
On the previous weeks we have explored how to create custom control over training process for automatic training. This week we'll talk about empowering your training with SERP data, and automatic testing of trained models.
How to scrape Google Images with a specific image size and object type?
Google has a great option to fetch only images with specified size, and another option for fethcing images with specified subject.
For example if we query blackberry, we'll end up with blackberry the phone, and the fruit with all sizes:

This could create problems in training process. If you want the distinction between blackberry the fruit and the orange the fruit, and if your training data has blackberry the phone as well, the classification accuracy will be lower compared to a training data full of images with blackberry the phone.
Also the size of the images matter. We do all kinds of fuzzy image operations on the training dataset before we subject it to training. Wouldn't it be awesome if we just had the blackberry fruit images with the specified size? That's where SerpApi comes in:
If you google the search term blackberry imagesize:500x500, and then click on the fruit tab, google will return images of blackberry fruits with specified dimensions:
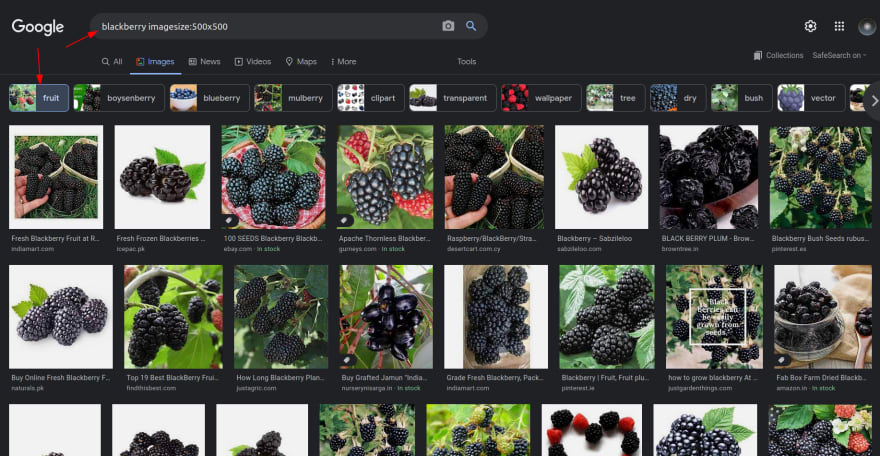
Now if you copy the link of the search, which in my case, it is:
https://www.google.com/search?q=blackberry+imagesize%3A500x500&oq=blackberry+imagesize%3A500x500&hl=en&tbm=isch&chips=q:blackberry,g_1:fruit:w5Q4DTH5fCg=&sourceid=chrome&ie=UTF-8
and replace the part https://www.google.com to https://serpapi.com:
https://serpapi.com/search?q=blackberry+imagesize%3A500x500&oq=blackberry+imagesize%3A500x500&hl=en&tbm=isch&chips=q:blackberry,g_1:fruit:w5Q4DTH5fCg=&sourceid=chrome&ie=UTF-8
You will be greeted with such a page:
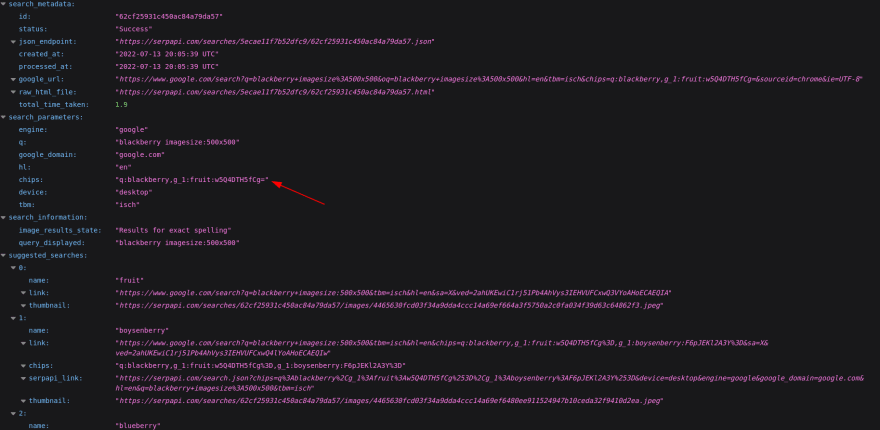
You'll need an account to use SerpApi Google Images Scraper API. You may register to claim free credits. SerpAoi is able to make sense of the url and its parameters and will break down parameters for you. We will be needing the chips parameter that is extracted.
Same structure applies for the oranges:

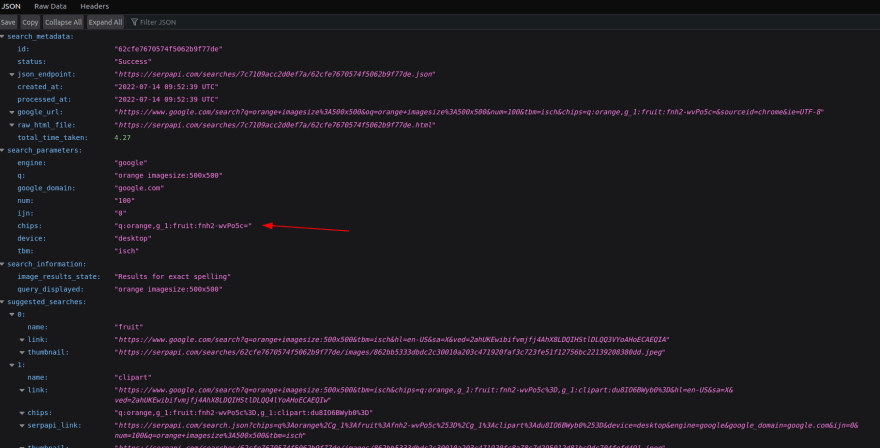
Changes in the Code
class Query(BaseModel):
google_domain: str = "google.com"
num: str = "100"
ijn: str = "0"
q: str
chips: str = None
api_key: str ## You may replace this with `api_key: str = "Your API Key"`
I have updated the class definition of a query to support chips parameter. This way we can query SerpApi with the following dictionary:
{
"google_domain": "google.com",
"num": "100",
"ijn": "0",
"q": "blackberry imagesize:500x500",
"chips": "q:blackberry,g_1:fruit:w5Q4DTH5fCg=",
"api_key": "<YOUR API KEY>"
}

You may change the ijn parameter from 0 to 1 to paginate to next 100 results from google, automatically upload the results to your storage database.
{
"google_domain": "google.com",
"num": "100",
"ijn": "1",
"q": "blackberry imagesize:500x500",
"chips": "q:blackberry,g_1:fruit:w5Q4DTH5fCg=",
"api_key": "<YOUR API KEY>"
}
Same structure also applies for the orange:
{
"google_domain": "google.com",
"num": "100",
"ijn": "0",
"q": "orange imagesize:500x500",
"chips": "q:orange,g_1:fruit:fnh2-wvPo5c=",
"api_key": "<YOUR API KEY>"
}
I have updated the initialization function of the class with the support for a class named TestCommands:
class CustomImageDataset(Dataset):
def __init__(self, tc: TrainCommands | None , db: ImagesDataBase, tsc: TestCommands | None=None):
if tc != None:
transform = tc.transform
target_transform = tc.target_transform
self.image_ops = tc.image_ops
self.label_names = tc.label_names
tc.n_labels = len(self.label_names)
if tsc != None:
transform = tsc.transform
target_transform = tsc.target_transform
self.image_ops = tsc.image_ops
self.label_names = tsc.label_names
tsc.n_labels = len(self.label_names)
self.db = db
I've also added an additional function to call an image with the specified id, and make transformations on it if needed:
def get_item_by_id(self, key):
while True:
try:
image_dict = self.db.get_image_by_key(key)
buf = base64.b64decode(image_dict['base64'])
buf = io.BytesIO(buf)
img = Image.open(buf)
label = image_dict['classification']
label_arr = np.full((len(self.label_names), 1), 0, dtype=float)
label_arr[self.label_names.index(label)]= 1.0
break
except:
print("Couldn't fetch the image, Retrying with another specified image")
if self.image_ops != None:
for op in self.image_ops:
for param in op:
if type(op[param]) == bool:
string_operation = "img.{}()".format(param)
elif type(op[param]) == dict:
string_operation = "img.{}(".format(param)
for inner_param in op[param]:
string_operation = string_operation + "{}={},".format(inner_param, op[param][inner_param])
string_operation = string_operation[0:-1] + ")"
with warnings.catch_warnings():
warnings.simplefilter("ignore")
img = eval(string_operation)
if not self.transform == False:
img = self.transform(img)
if not self.target_transform == False:
label = self.target_transform(label_arr)
return img, label
I have also added a newer function to ImagesDatabase object to call all the unique ids of a specific classification:
def get_image_keys_by_classification(self, cs):
try:
sql_query = 'SELECT id FROM `images`.image.labelled_image WHERE classification = $1'
row_iter = self.cluster.query(
sql_query,
QueryOptions(positional_parameters=[cs]))
rows_arr = []
for row in row_iter:
rows_arr.append(row)
return rows_arr
except Exception as e:
print(e)
One thing to notice here is that unless specified explicitly, all the classifications will be equal to the query made. So blackberry and blackberry imagesize:500x500 will be two distinct classifications. This way we can call only the blackberry images that are fruit and have specified dimensions.
Here's the TestCommands object to start tests:
class TestCommands(BaseModel):
ids: list = None
label_names: list = ["Orange", "Blackberry"]
n_labels: int = None
criterion: dict = {"name": "CrossEntropyLoss"}
model: str = "oranges_and_blackberries.pt"
image_ops: list = [{"resize":{"size": (500, 500), "resample": "Image.ANTIALIAS"}}, {"convert": {"mode": "'RGB'"}}]
transform: dict = {"ToTensor": True, "Normalize": {"mean": (0.5, 0.5, 0.5), "std": (0.5, 0.5, 0.5)}}
target_transform: dict = {"ToTensor": True}
Since I haven't created a customizable model object yet, we will be using CNN only. As you can see, it has all the elements necessary to call the model file and make a prediction. The inputs will be subjected to same transformations as the training process. However, for example, resizing to same size won't create any distortions.
Here is the Test class we will utilize to make our tests:
class Test:
def __init__(self, tsc: TestCommands, cid: CustomImageDataset, db: ImagesDataBase, cnn: CNN):
db = db()
self.cid = cid(tc = None, db = db, tsc = tsc)
if tsc.ids != None:
self.ids = tsc.ids
elif tsc.label_names != None:
self.label_names = tsc.label_names
self.label_ids = []
for label in self.label_names:
returned_ids = db.get_image_keys_by_classification(label)
for dict in returned_ids:
self.label_ids.append(dict['id'])
self.accuracy = 0.0
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.model = cnn(tsc)
self.model.load_state_dict(torch.load("models/{}".format(tsc.model)))
self.model.eval()
def test_accuracy(self):
for id in self.label_ids:
img, label = self.cid.get_item_by_id(id)
img = [img.numpy()]
img = np.asarray(img, dtype='float64')
img = torch.from_numpy(img).float()
img = img.to(self.device)
label = [label.numpy()]
label = np.asarray(label, dtype='float64')
label = torch.from_numpy(label).float()
label = label.to(self.device)
if torch.cuda.is_available():
self.model.cuda()
prediction = self.model(img).to(self.device)[0]
else:
prediction = self.cnn(img)[0]
if (label.argmax() == prediction.argmax()).item():
self.accuracy = self.accuracy + (1.0/float(len(self.label_ids)))
return self.accuracy
It will call the image database for specified classifications, and test the model with all of the images (haven't specified a limit per classification yet), and return accuracy of the model.
Finally, let's specify an endpoint for testing:
@app.post("/test")
def test(tsc: TestCommands):
tester = Test(tsc, CustomImageDataset, ImagesDataBase, CNN)
accuracy = tester.test_accuracy()
return {"status": "Success","accuracy": "{}".format(accuracy)}
Training and Testing Automatically
I have uploaded 2 pages of images of blackberry imagesize:500x500 and 2 pages of orange imagesize:500x500to my storage using SerpApi's Google Images Scraper API
I used the following dictionary file to train the model:
{
"model_name": "blackberries_and_oranges.pt",
"criterion": {
"name": "CrossEntropyLoss"
},
"optimizer": {
"name": "SGD",
"lr": 0.001,
"momentum": 0.9
},
"batch_size": 4,
"n_epoch": 5,
"n_labels": 0,
"transform": {
"ToTensor": true,
"Normalize": {
"mean": [
0.5,
0.5,
0.5
],
"std": [
0.5,
0.5,
0.5
]
}
},
"target_transform": {
"ToTensor": true
},
"label_names": [
"orange imagesize:500x500",
"blackberry imagesize:500x500"
]
}

Then I used the following dictionary to test the model:
{
"label_names": [
"orange imagesize:500x500",
"Blackberry"
],
"n_labels": 0,
"criterion": {
"name": "CrossEntropyLoss"
},
"model": "blackberries_and_oranges.pt",
"transform": {
"ToTensor": true,
"Normalize": {
"mean": [
0.5,
0.5,
0.5
],
"std": [
0.5,
0.5,
0.5
]
}
},
"target_transform": {
"ToTensor": true
}
}

Here's the response I got from testing endpoint:
{
"status": "Success",
"accuracy": "0.6792452830188679"
}
This is of course not a representative of the actual usecase since this is a small scale training, and the test has been done on images that the model is already trained on. But you may pass ids key instead of label_names to avoid using the same set. But it is a representative of the use of SERP data to get rid of some data cleaning procedures.
Conclusion
I am grateful to the reader for their time and attention, and I am grateful to the Brilliant People of SerpApi to make this blog post possible. In the coming weeks, we will explore how to further have custom control over the training, handle some actions with asynchronous processes, and hopefully open op the entire code to be an Open Source Repository once it feels concrete enough.

Top comments (0)