
Your app’s networking directly affects the user experience of your app. Imagine having to wait a few seconds for the page to load. Or even worse, imagine waiting for a few seconds every time you perform an action. It would be infuriating! Before you go on a fixing adventure, it’s a good idea to understand what causes that waiting time. So let’s do that!
The difference between Latency vs Response Time
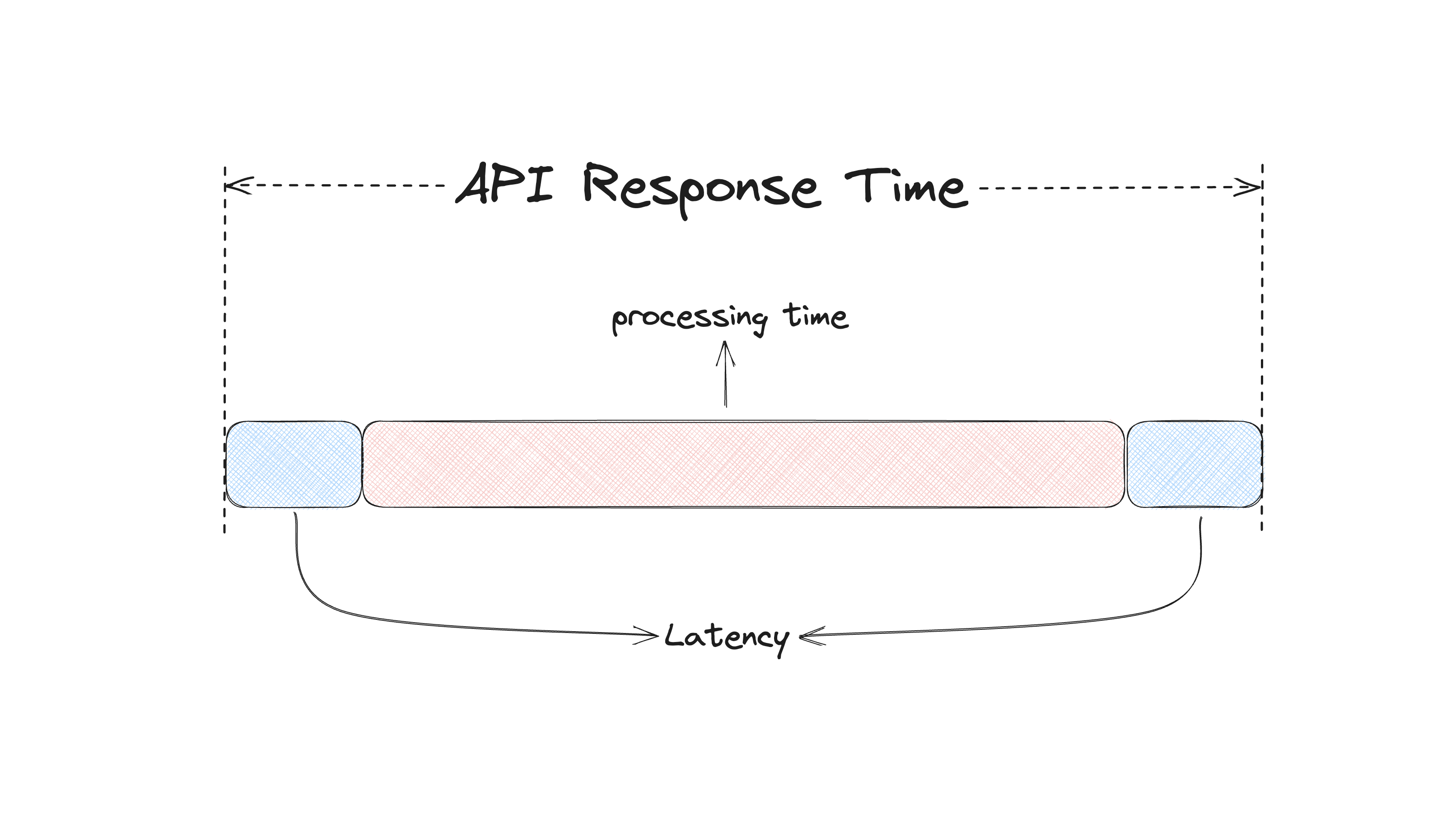
The total client-server communication time is called API Response Time. That’s from the moment the client makes a request, until it receives a response back. A slow request means a very long response time. Anything that contributes to the slowness affects the response time.
The response time consists of the latency and the processing time. The latency is how long it takes to transfer data between the client and the server, or the “processing component”. A few factors contribute to the latency:
- the network speed
- the server load
- the performance of the load balancer
- the size of the data we’re sending
- and the API design
For example, the client sends a data request to the API and gets a response back in 3 seconds. The total response time is 3 seconds. The latency might be 300ms, which leaves 2500ms, or 2.5 seconds, for processing. Just to have a number in mind, high-performing APIs are considered to have between 0.1 and 1 second average response time. At 2 seconds the delay is noticeable. At 5 seconds the delay is so significant that the users are starting to abandon the application/website.
The response time is one of the most important metrics we need to keep our eyes on. If not, it can significantly hurt the user experience, and even the business itself. Back in 2008, Amazon reported that every 100ms latency costs 1% of their profit. Google also reported that in an experiment that increased the number of search results they noticed that half a second delay caused a 20% drop in traffic. These are significant numbers. Amazon makes $19.4 billion per month. 1% of those sales is $194 million. Add up that number for every 100ms latency and you’ll see the damage. As you can see, learning how to monitor and optimize your API response time is a very good investment.
Just like any other web performance metric, the response time should be measured and monitored in production. Your computer and internet speed might be fast, but your users’ computers and internet are probably not as fast. That results in much less favorable results than what you’ll see if you measured your API’s response time locally. But working with production data also means that you’re working with outliers. The Average Response Time is not always a good metric. Let’s learn how to properly measure the API response time.
Measuring response time
First let’s talk about why ART (Average Response Time) is not a good metric. There are always the edge cases where a small number of your users are reporting the worst response times imaginable. That could be because of a really outdated computer, or they’re trying to access your web app with a bad internet connection (subway, remote locations, etc…), or your API experienced a brief downtime because of a bug or your deployment. You don’t care about those cases because there is usually nothing you can do about them. Calculating an average on that data will take those outliers into account as well, and you don’t want that. You want to exclude those data points from your data. Enter: percentiles.
Percentiles provide you with a different view of your performance data. The data is sorted in a descending order and cut at specific % points. The most commonly used percentiles are p50, p75, p95, p99 and p100.
- P50, also called the Median, is the value below which 50% of the data falls. This would be the typical performance of your API.
- P75 is the value where 75% of the data falls. This percentile is good for frontend applications because it includes more variable data, which mirrors the variety of the user conditions.
- P95 is more valuable for backend applications where the data is more uniform.
- P99, also called Peak Response Time, is also more valuable for backend applications, and it marks the upper limit of the performance.
- P100 is the maximum observed value. This is the worst measured performance.
If you want to get into more detail about percentiles, read our “Choosing the Right Metric” article.
Another important metric is the Error/Failure Rate of your API. The Error/Failure Rate is a value that indicates the % of requests that resulted with a non-200 status code. Having this data can also help you figure out if things are wrong with your API or documentation. If you’re seeing more “400s” status codes, it might mean that clients don’t use your API properly, or don’t understand it well. If you’re seeing more “500s” status codes then it means you have issues with your code.
Monitoring API response time in production
To monitor your API’s response time (and other metrics as well) in production, you need to implement a mechanism that will continuously take those measurements, save them in a database, and provide you with tools to query and visualize the data. Sentry is an application performance monitoring tool that you can use to monitor all of your frontend, backend, and mobile application projects—not just your API. And don’t worry, Sentry probably has an SDK for whatever framework you’re using.
Getting started is easy. After installing and configuring Sentry’s SDK for your framework of choice, you’ll get automatic instrumentation, which means a bigger part of your backend is already set up with performance monitoring. Depending on the size of your application, this could be enough to get started. If you need more detailed performance data, you can add custom instrumentations in certain places.
When you start getting performance data in your Sentry account, identifying what makes your API slow is quick. Getting to the root cause of the slow performance is even quicker. Sentry’s tracing data makes the performance bottlenecks obvious. Here’s a short arcade that shows you how you can identify performance bottlenecks in your application and figure out what causes them:

Backend Performance Monitoring | Arcade
A good resource on improving the performance of your API using Sentry is Lincoln Loop’s “19x faster response time” article.
Conclusion
So, a quick recap. API latency is the time it takes for the data to be transmitted between the client and the backend. The API response time is the latency + the time it takes for the backend to process the request and return the result. Factors like network speed, load balancer, data size, server load, API design, and our code affect the response time.
To properly monitor the performance of your backend, you need to use a tool that will monitor your application while in production. Sentry can help you with that, head to https://sentry.io/signup to get started.

Top comments (0)