
At some point, every one of us has worked on a project where tests were an afterthought — a grueling experience that shows the value in testing discipline (consider yourself one of the lucky few if not).
In this article, I’d like to talk about one of the most complex forms of testing, one that will tell us when we have met our software design goals: Acceptance Testing.
What is acceptance testing?
Acceptance testing is the practice of running high-level, end-to-end tests to ensure a system follows the spec. Acceptance tests are derived from acceptance criteria, which defines how the application responds to user actions or events.
Acceptance tests shift attention towards the end goal: shipping software that fulfills a business need. They cross the gap between developers and end-users, ensuring that the application works in the real world.
What do acceptance tests test?
Acceptance tests are different from other types of tests. Why? Because they are primarily about business goals. While technology-facing unit tests ask “is this function returning the correct value?” and integration tests ask “are the application components interacting well?”, acceptance tests focus on what matters most when all is said and done: "is my application providing valuable functionality to end users?"
The importance of these questions cannot be overstated. If your customers don’t get what they came for, either because you didn't meet the goals or because you overengineered the solution, you won’t be in business for long.
Acceptance tests come in two variants:
- Functional acceptance tests deal with application behavior. They ask "does the application work as users expect?”
- Non-functional acceptance tests cover things like security, capacity, and performance. These are questions such as “is my system secure and fast enough?"
Testing business goals
An application that passes all acceptance tests is, by definition, complete and working according to the specs. Acceptance testing is an iterative process where:
- We define the criteria in cooperation with product managers, who collaborate with end-users.
- We write tests to meet the acceptance criteria. The tests should initially fail.
- We code until we pass the tests.
- Once acceptance tests pass, progress is evaluated. A new cycle may begin.

At the end of every cycle the specification is reviewed and refined. The process continues until all acceptance criteria have been met.
How to write acceptance tests
Writing and maintaining acceptance tests is not a trivial thing, but it’s an investment that will be repaid many times over throughout the project. Unlike unit tests, which can run piecemeal, acceptance tests must test the system as a whole. We must start the application in a production-like environment and interact with it in the same way a user would.
Organizing acceptance tests
Once you have your acceptance criteria defined, we can start writing the tests. The most high-value targets for acceptance tests are the happy paths: the default scenario where there are no exceptions or error conditions.
We organize acceptance tests in two layers:
- Acceptance Criteria Layer: this is a conceptual description of the case being tested.
- Test Implementation Layer: encodes the acceptance criteria layer cases using a testing framework. This layer interacts with the application, simulates user actions, and deals with the UI.

Acceptance criteria layer
The top layer describes in plain English the case under test. It states what the application does without saying anything about how it's done. Here we ask questions such as: “if I buy this product, will the order be accepted?,” or “if I don’t have funds, will the order be rejected and the user notified?”.
We use the Behavior-Driven Development (BDD) pattern of Given-When-Then to formalize the case under test:
-
Given: gives context and pre-conditions. This is the initial state of the application. -
When: describes the events or actions the user takes. -
Then: lists the expected outcomes.
For instance, an criteria for testing the login feature might go like this:
Feature: Sign into the system
Scenario: User logs in and sees the welcome page
Given I have an account
When I sign in with my valid credentials
Then I see the welcome page
BDD libraries like Cucumber, Ginkgo, Behat, Behave, or Lettuce allow you to use plain text to describe acceptance criteria and keep them synchronized with the test execution. If these tools are not an option, we can use the Given-When-Then pattern in the test’s description text.
Test implementation layer
If the acceptance criteria layer focuses on building the right things, then the implementation layer is about building them right. Here is where we find Test-Driven Development (TDD) frameworks like JUnit, Mocha, or RSpec, of which many employ a Domain Specific Language (DSL) to map the conditions and actions in the acceptance layer into executable code. The test layer function is to evaluate the pre-conditions, execute the actions, and compare the outputs.
For instance, the acceptance test above requires a log in routine. Here's where the expressive power of a DSL like Capybara manifests:
When /I sign in/ do
within("#session") do
fill_in 'Email', with: 'user@example.com'
fill_in 'Password', with: 'password'
end
click_button 'Sign in'
end
Dealing with the UI
If the application has an UI, acceptance tests should cover it; otherwise, we're not really testing the path end users experience. The test layer must then include a window driver that knows how to operate the UI, like clicking buttons, filling fields, and parsing the results. In this category we have libraries such as Puppeteer, Cypress, and Selenium.

UI testing has some downsides though. The tests are slower, harder to scale up, and because they break more easily they need more maintenance. Acceptance tests must include the UI, but that doesn't mean that every test should go through it. It's perfectly acceptable to channel some of the tests via alternative paths like API endpoints.
Automating acceptance tests
Being in business means fulfilling business objectives. When an acceptance test breaks, we must drop everything else we're doing and triage the problem right away.
While manual tests are possible, the results are unreliable. It’s slow and painstaking work that makes testers miserable. Automated acceptance tests, on the other hand, give immediate feedback about business objectives.
Acceptance tests should be automated because they:
- Alleviate workload on testers.
- Reduce the time test runtime.
- Allow for regression testing.
- Allowing testers to focus on exploratory testing, increasing test coverage and improving the performance of the test suite.
- Find the exact point at which an error was introduced.
Continuous acceptance testing with CI/CD
Once we have written our automated acceptance tests, we must run them continuously. Acceptance tests take more resources to run than any other type of test, so careful consideration must be taken when setting up the continuous integration process.
If the CI/CD pipeline is going to fail, it’d better do it sooner than later. The shorter the feedback cycle, the earlier we know there is a problem. Thus, place the fastest tests first during the build stage.
Next, we add integration, security, and any other medium-level tests. Acceptance tests, which take longer, should go at the very end of the pipeline using parallelism to reduce the total time.

When should acceptance tests run
At this point, we have a choice: do we want to run the acceptance tests on every commit? Ideally, yes, but in practice, if the tests take too long, or if it is costly due to infrastructure concerns, we can run them only on specific branches or before doing a deployment with promotions.
To manage more complex situations, we have the change_in function, which allows us to run blocks on specific conditions such as when some files change and a key component of monorepo workflows.
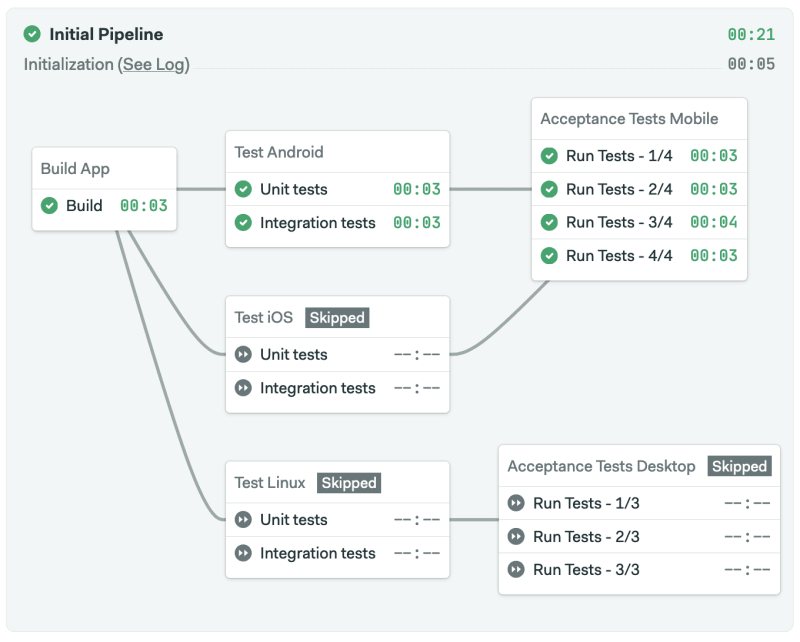
Better insight with test reports
Last not least, configure your test framework to generate reports in a format compatible with Semaphore test reports. This way, Semaphore can collect the output from several runs into one convenient, easy-to-read report that brings a wider perspective of the state of your acceptance tests over time.

Streamlining acceptance tests
Optimizing the application for testability dramatically reduces the effort of maintaining tests. Stick to these points in order to keep them streamlined:
- Avoid production environments: acceptance tests should not run in a real-life production system. At the same time, the test environment must closely resemble production. When integration with external systems is needed, we should mock services and use test doubles.
- Avoid production data: avoid the temptation of using a production database dump in the testing environment. Instead, each test should populate the database with the needed values and clean up afterward. Keep the test dataset as minimal as possible.
- Respect encapsulation: don’t break code encapsulation. Test using the same public functions or APIs offered by your code. Avoid the temptation of adding a privileged backdoor to run a test.
- Keep them loose: coupling tests to code too tightly leads to false positives and extra maintenance work.
- Expose programmatic access: this only happens in UI-only applications. When the UI is the only way of interacting with the code, testing it is a lot more complicated.
Conclusion
Acceptance tests are an integral part of behavior-driven development and the primary tool we have to ensure we fulfill our business goals.
Read next:
- Continuous Integration & Delivery Explained
- 20 Types of Tests Every Developer Should Know
- Revving up Continuous Integration with Parallel Testing
- Continuous Integration for Monorepos
- Design an Effective Build Stage for Continuous Integration
Thank you for reading!

Top comments (0)