
Many companies use Jira to organise their backlog and to plan sprints. Due to constraints in the software and what happens in everyday Scrum live, this creates some issues for which I present a workaround that solved them during my time as Product Owner.
Currently I’m spending a large part of my working time as a consultant in a Scrum team at a large telecommunications company.
I’m mostly focused on helping them building modules and components for their Neos CMS installation. But as part of their team, I’m also following closely how they work with Scrum and related tools.
In the last 6 years I worked as Product Owner and in other Scrum roles at an agency. I learnt a lot and I also found good solutions for the issues one has, when trying to have a synchronous digital representation your processes. The concept I will explain should also work perfectly fine with any other tool that supports putting stories into sprints.
Why the default sprint list wasn’t enough
At the agency we also worked with Jira and I had to make sure that our customers and my team were able to look at the shared Jira boards and understand what currently happens and what each of them has to do. I also wanted to minimise the chance for errors as that would have led to mistakes, loosing track of important tasks and finally also an increasing amount of work for me to keep track of everything.
Each customer would have their own board where they can see their backlog, stories that are being prepared and stories that are being worked on. They would prioritise in their board and synchronise this with me, so we could would work on the most important and valuable tasks for their project.
Internally we would have one board which combined the stories of all the customers (5+) my team worked for. They needed a way to immediately understand what to do next and what they needed to take care of during refinements and plannings. I could always have told them what to do next, but that would have meant, that I needed to remember everything. They would also have a problem, when I’m not there. So over 2 years I worked with our customers and the team on several iterations of „meta“-sprints that would organise the stories in our board in a way that made sense to everyone involved. At the end I had a structure that worked for everybody and I rarely needed to tell anyone where to put new stories or what to work on in the sprint meetings.
I just had to make sure that I prioritised the shared board to make sure that each customers stories where in the right place in relation to each other, and keeping a good overview which stories were coming up that had a high priority.
Different place - same problems
At the mentioned company we currently only work on one project, but it has a very high complexity with many components, dependencies to other teams and stakeholders. During the first few planning sessions and refinements I realised they basically had the same issues as we had with our agency work. People are not always sure where to put stories, what to work on in a meeting and a high dependency on the Product Owner. And there is one ongoing issue with Jira which can cause trouble when you finish a sprint and your unfinished stories get mixed up with the ones already put into the next sprint. I understand from a technical perspective that it’s hard for Jira to find the right spot for each story, especially if you organise them with several boards, but it’s still annoying and can cost a lot of time to sort things the right way again. That’s worse when you have the whole team sitting there and waiting.
To explain my sprints in a more visual way I set up a simple Jira cloud trial and created some sprints and stories that will help my future rocket startup to fly to the moon and make me rich.
First I will start almost at the bottom, just above the „Backlog“.
The „Upcoming“-sprint
When you work on projects for many years, your backlog can fill up with all kinds of stories. Some people say you should just remove everything that has a certain age, but when working with several customers that can cause diplomatic issues that are sometimes not worth to fight for. So I accepted that we have a certain amount of „zombie“-stories that might at some point happen or they won’t. This lead me to create the first „meta“-sprint. The one called „Upcoming“ (thanks to a certain other PO for coming up with a better name than I did!). This separates the usual backlog from stories that are actually relevant in the foreseeable future or stories that just temporarily fell out of the priority due to some stakeholders decision. I tried keeping the amount of stories in this sprint under 20 to not lose track and create yet another „zombie“ backlog.

As you see in the screenshot, the stories in the „Upcoming“-sprint might already have story points as they can even have come from a previously ongoing sprint. If they at some point lose their relevance, then it’s fine to put them into the backlog or simply close them.
You can see that I used the sprint goal field to clarify what the „meta“-sprint is about. This is an important part as I iterated several times about those texts and verified with each customer, if it made sense to them. I wanted to be sure that their new and old stories always went to the right place.
The „Refinement“-sprint
The next „meta“-sprint is the „Refinement“-sprint. It contains all the stories that should be done in the near future and are prepared by the PO to be filled up with details during the Scrum teams refinement meetings. In our Jira workflow these stories were in the „Requirements engineering“ step.
During those meetings the team would simply go through each story from top to bottom and make sure that each story fulfils their „Definition of ready“. Many teams estimate stories during the planning meetings, which I never liked. Getting an estimate just right before I wanted to put a story into a sprint caused a lot of stress for me. I had almost no time to react when a story got a bigger estimate than I or the stakeholder expected. And I wasn’t able to make sure that all questions which might arise during an estimation could be answered before a new sprint would start. Therefore we had two 1-hour refinement meetings during our 2-week sprints and I had enough time to discuss details or priorities with the stakeholders and split stories if necessary.
And also the team had more time to solve technical questions which might need some outside help.
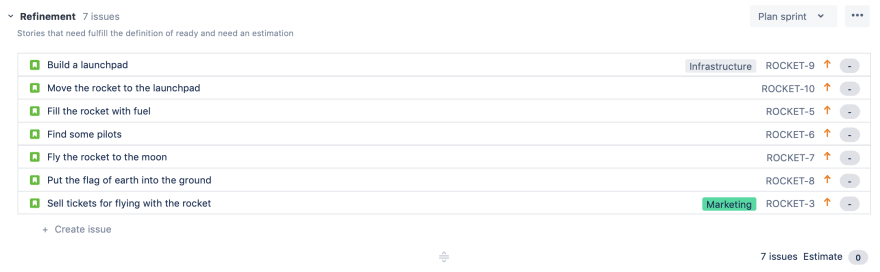
When the team was done preparing a story in the refinement meeting, it would have story points and it would be marked as „Open“ in the workflow. That means it could be worked on at any time if prioritised into a sprint. This should represent the "definition of ready" in Scrum with any other requirement your process might have for stories.
The „Prioritisation“-sprint
I now had an amount of stories at the top of the „Refinement“-sprint that I could work with as PO. So I put the stories where I was sure they can be prioritised into the next „meta“-sprint called „Prioritisation“-sprint.

For some stories the stakeholder just wanted to have an estimation or understand the complexity before making a decision. Those I put into the „Upcoming“-sprint again and assigned them to the person responsible. They could then also decide to put them again into the „Prioritisation“-sprint. Which meant, we as a team could work on them according to the stakeholders / customers priority.
Having this sprint far away from the backlog keeps you usually from suddenly having a story in there which was just created or someone accidentally put there.
As we started sprints on Mondays, I always made sure that each customer showed some activity in their priority in the week before, so I knew I could rely on the list for the next sprint.
The actual sprints
At the top of the screen are the „normal“ sprints. There is the currently active sprint which shows the stories that are in progress and there is the empty sprint that will come next. This one should stay empty until one finishes the current sprint during the next planning meeting.

When finishing the current sprint any unfinished stories will move to the next sprint and stay in order. This way you can easily see which stories are unfinished and you can check whether they should go into the next sprint. Sometimes stories are actually done, but someone forgot to close them. This should rather be checked before closing the old sprint, so your metrics show those hard earned story points.
When this is done, the team can now use the little drag icon at the bottom of the sprint to move stories from the „Prioritisation“-sprint into the next sprint. The story point count will go up and the team can stop when they think they reached the amount they choose to commit to.
Here you can see the whole board with all sprints:

Other tipps & tricks
When your amount of stories grows bigger, define some filters in the board which allow you to easily spot stories which are in the wrong sprint. Having a filter that just shows stories that are not „ready“ will help you to remove them from the sprints where they don’t fit. Same for other statuses and steps on your workflow.
I spent a bit of time every month to improve my filters and my Jira dashboard to allow me to spot stories which are not in the right place as fast as possible. For example customers might create „bugs“ which should be monitored and taken care of. But when they are stressed they might put it into the wrong sprint or at the end of the backlog where nobody spots them. Or a developer injects a story into the sprint without telling anyone about it. Your dashboard should just show these kind of mishaps. It’s not about telling people they did something wrong, it’s about making sure, everyone is synchronised.
If you have a step in your workflow that can mean two things, just insert another step and remove the source of confusion.
Summary
Until recently this system felt so natural to me, that I didn’t think of writing it down. Now I feel that this might help other teams to reduce errors, confusion and to be more effective. Try it out in your Jira or set up a trial.
Every time you feel like things are mixed that should be separate, take a step away from your issue and see if you can divide it into smaller parts. Then conquer them!
If you did, I would love to know about your experience. And if you have a similar or different system that works great for you, I would also love to know more about that.

Top comments (0)