
Unlike software engineering, there aren't a lot of college courses in data engineering.
Nor a huge list of boot camps teaching the practice.
This leads to best practices often being learned on the job, as well as a cornucopia of technologies being used across teams and companies.
So what defines a data engineer?
Especially as this role evolves away from its roots in database management and BI it really has changed and expects much more than it used to.
Data engineers used to be able to get away with just knowing basic data warehousing, ETLs, and data visualization.
However, in recent years, the demand for understanding distributed computing, DevOps, data ops and implementing machine learning models has challenged that notion.
In fact, in many ways, many high-level DEs are often more specialized in either software or DS work.
Having to create systems and frameworks from the ground up that interact with APIs, streaming data services and more.
Just cobbling together pipelines is no longer the baseline.
But all the skills required can be overwhelming.
Especially to the new graduate or classic data engineers.
You want to get started in the data engineering world, but you don't know where to start.
That is what this series of posts and videos will be about.
To start out, this post will introduce you to the vocab of data engineers as well as some tools we rely on.
All of this is going to lead up to developing a data warehouse and data pipelines.
So let's get started.
Data Engineering Vocabulary


Photo by Brett Jordan on Unsplash
To get started, let's list out some vocabulary that are important to DEs.
We will be outlining the basics here because often times if you are just out of school you will hear a lot of vocabulary and just nod your head without fully understanding what these may be.
Data Warehouse

source: https://www.wisdomjobs.com/e-university/data-warehousing-tutorial-237/star-schemas-2620.html
Data Warehouses are central location data analysts and BI professionals can go to access all their data. There is a lot of debate about data warehouses, data marts, Kimball vs Inmon, and what all of this means.
At the end of the day, a data warehouse is typically a denormalized set of data that is often pulled from a single or multiple application databases that are used internally to answer business questions. It is different from an application database because data warehouses are designed for dealing with analytical queries vs. transactional queries.
In addition, data warehouses will also often house multiple application databases. This is one of the values a data warehouse can offer. By bringing data from multiple systems together
Also, in the modern era, many data systems like BigQuery, Redshift, and Snowflake have all been developed specifically to manage data warehouse-style queries. This means queries that run large amounts of analysis, sums, aggregates and are not often transactionally focused.
But even beyond just that. They are designed for ease of understanding. A good data warehouse should be straight-forward for an analyst to understand so they can connect their data visualization tools to it.
The end goal is usually to create some sort of self-service analytics system. This means that there shouldn't be overly complex data models and there should be a well-defined set of business logic that both the engineering and business teams agree on...in theory.
But let's move on to data pipelines.
Data Pipeline And ETLs
Often times you will hear data engineers use the term data pipelines. This can also often be replaced with the term ETL. There are some nuances between the two. But overall, both reference similar concepts.
An ETL refers to extract transform and load (sometimes it can actually be an ELT) but we will avoid complicating things.
ETLs and data pipelines are automated workflows that take data from point A to point B and transforms them along the way to improve their ability to be analyzed.
When you pull your data from an application database, you often put it into some form of CSV or JSON extract. These extracts can come from scraping application database tables, pulling data from APIs, scraping logs, etc.
At the extract phase, the data is still often either limited to be a snapshot of the database at the current time or all the historical data. Again, there are a lot of nuances even here that change the design of your ETL like is data allowed to be modified, deleted, duplicated, and so on.
There is a good reason for the application database being set up this way as it is great for keeping the site fast and responsive, but limits the insights analysts can get.
Statuses might change over time as users make updates to profiles and edit various bits of information.
Thus, an ETL will also help insert data in such a way that tracks changes over time. Often this form of tracking change management is referenced as slowly changing dimensions.
Once the data is transformed it will then be loaded into the data warehouse.
DAGs
DAG stands for Directed Acyclic Graph.
ETLs are just one part of the very complex puzzle that is a DAG. When transforming data there is often a specific order to the steps you will take. But how do you tell your system that? How does an ETL know which part to run and when?
That's where DAGs come into play.
DAGs have always sort of existed in the data engineering world. Just for a long time, they were managed through a combination of CRON, some custom-built meta-databases and bash, python and Power-shell scripts.
This was very messy and time-consuming.
Today there are a lot of modern tools and libraries that can help manage your ETL pipelines. This includes Airflow, Luigi, Petl, and dagster.io (for starters). There are tens if not hundreds of tools and libraries focused on this very subject.
Personally, we rely heavily on Airflow because it has a large user base. But there are plenty of great libraries and you will probably use a few as you get more versed in the data field.
Fact tables
Now, what about the tables the ETLs load their data into?
Why do they have such odd prefixes?
When you start working in a data warehouse you will see the prefix "fact_" or "f_" attached to a table.
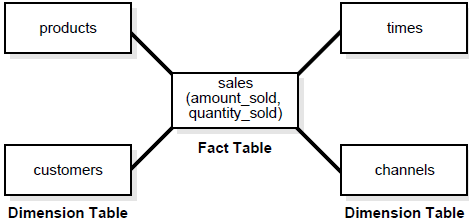
This prefix references the type of data you will find in this table. In particular, facts are typically the actual transaction type data. This could be the orders on an e-commerce site, the total for the health claim, etc. In general, facts will have some sort of aggregatable value like the total number of items purchased or the total sale as well as what is called dim_ table keys like store_id, product_type_id, and so on.
Facts can generally be looked at like a central table.
For example, in the image below you will see that the fact table is at the center of everything. Again, this is because facts represent the core idea you are analyzing and reporting on. This could be transactions, uses, email opens, etc.
Dimension Tables
There are really many different types of tables in a data warehouse. However, fact tables and dimension tables are probably the most common.
Dimension tables are more descriptive data. Think about when you are analyzing data you often want to group it by store, region, website, office manager, etc.
So maybe you want to count how many employees are in each building that your company owns. The building descriptive information is in a dimension table while the actual facts about the employees that connect to that building are in the fact table.
Again, looking at the picture above, the dimension tables sit all around the fact table.
It will help you describe and group your factual data.
What Will We Talk About Next?
This was the first of what we hope are several posts about data engineering. We would like to continue these series start going into data pipeline development, metrics, data warehouse design, etc.
We hope this was helpful and we will be looking to continue on these topics. Let us know if you had any questions or would like help with a specific portion of this topic.
Thanks!
Are You Interested In Learning About Data Science Or Tech?
What Is Data Ops And How It Is Changing The Data World
Our Favorite Machine Learning Courses On Coursera For Free
Dynamically Bulk Inserting CSV Data Into A SQL Server
4 Must Have Skills For Data Scientists
SQL Best Practices --- Designing An ETL Video

Top comments (0)