Problem statement
Context
- Lets assume that we have data pipeline(s) dumping messages into Google BigQuery tables (lets call them raw tables).
- There maybe duplicate messages being stored in the raw table due to reasons like:
- Duplicate messages sent from source
- Message inserted multiple times due to network issues and retries between the data pipeline and big query (although this can be addressed to some extent by using unique request ids while loading the data into BQ)
- BigQuery doesn't have unique indexes
Assumptions
- Duplicate messages have the same identifier (maybe message_id), although they may differ by any additional metadata injected by the data pipeline, e.g.: receive_timestamp
- The message has a business timestamp that is provided by upstream systems
- Messages can arrive late (maybe several days)
- Lets assume that we have a raw orders table with these fields:
- message_id: unique id identifying one message
- message_timestamp: timestamp provided by the source systems
- order_id: unique id identifying an order
- order_amount: amount against the order
- receive_timestamp: receive time injected by the ingestion pipeline
Objective
- These messages need to be exposed as a data product to consumers in de-duplicated form and the consumers shouldn't have to worry about de-duplication
- Cost effectiveness. NOTE: BQ billing is based on number of bytes scanned and stored according to the on demand pricing model.
Solution 1
One way would be to create a view that selects distinct entries from the raw table. E.g. view SQL:
CREATE OR REPLACE VIEW views.orders AS
SELECT
DISTINCT
message_id,
message_timestamp,
order_id,
order_amount
FROM raw.orders
Now a consumer could query this view with an SQL like: SELECT * FROM views.orders WHERE DATE(message_timestamp) BETWEEN '2023-01-01' AND '2023-01-31' to get orders placed in the month of january.
If the raw orders table is partitioned on message_timestamp field, then BiqQuery will query only those entries belonging to January's partition.
However, if we need some more flexibility in the uniqueness criteria then a DISTINCT keyword doesn't help. Example use cases:
- receive_timestamp needs to be part of the view: The same message may have multiple entries with different receive_timestamps, in which case de-duplication by message_id won't work. Although in this specific case one could argue that receive_timestamp should not be exposed to consumers.
- in case of multiple entries with same message_id, the entry with the latest receive time needs to be selected
Solution 2
We can bring in more flexibility into the uniqueness criteria by using a QUALIFY CLAUSE in the view:
CREATE OR REPLACE VIEW views.orders AS
SELECT
*
FROM raw.orders
QUALIFY ROW_NUMBER() OVER (PARTITION BY message_id ORDER BY receive_timestamp DESC) = 1
This works, however, if the table is partitioned by message_timestamp, and consumers query the view with filtering on message_timestamp using a query like: SELECT * FROM views.orders WHERE DATE(message_timestamp) BETWEEN '2023-01-01' AND '2023-01-31', that does not reduce the partitions scanned, and BQ ends up scanning all the partitions.
It would have worked if we could have placed the WHERE clause before the QUALIFY clause, something like:
CREATE OR REPLACE VIEW views.orders AS
SELECT
*
FROM raw.orders
WHERE DATE(message_timestamp) BETWEEN '2023-01-01' AND '2023-01-31'
QUALIFY ROW_NUMBER() OVER (PARTITION BY message_id ORDER BY receive_timestamp DESC) = 1
But while defining the view, we do not know the exact message_timestamp that needs to used for filtering, because it is known only at run time.
Solution 3
What if we could have the WHERE clause before the QUALIFY clause, and inject the values at runtime?
Table functions can do that !
CREATE OR REPLACE TABLE FUNCTION functions.orders(start_date DATE, end_date DATE) AS
SELECT
*
FROM raw.orders
WHERE DATE(message_timestamp) BETWEEN start_date AND end_date
QUALIFY ROW_NUMBER() OVER (PARTITION BY message_id ORDER BY receive_timestamp DESC) = 1
Consumers can then query this function like this:
SELECT * FROM functions.orders('2023-01-01', '2023-01-31') WHERE <other filters>
Here only January's partition is scanned by BQ.
To summarise:
- We can create functions (lets call them raw table functions) on top of raw tables that accept data ranges as input and injects those parameters into the WHERE clause before QUALIFY
- Based on business needs, we may also create higher order functions if needed by composing one or more raw table functions (across different domains) so that the input date can be propagated till the lowest level.
Solution 4-A
Can we retain the semantics of a table ? One way to do that would be to:
- Dump the raw data first into a raw table partitioned by receive time
- Run a scheduled query to take the latest partition from the raw table and merge it into another deduplicated table (deduplicated table is partitioned by message_timestamp)
- Remove old partitions from the raw table
Sample scheduled query that can be run daily to scan yesterday's raw records and merge them:
MERGE INTO dedup.orders dest USING (
SELECT
*
FROM raw_partitioned_by_receive_timestamp.orders
WHERE DATE(receive_timestamp) = CURRENT_DATE()-1
QUALIFY ROW_NUMBER() OVER (PARTITION BY message_id ORDER BY receive_timestamp DESC) = 1
) src
ON dest.message_id = src.message_id
WHEN NOT MATCHED THEN INSERT(message_id, message_timestamp, order_id, order_amount, receive_timestamp)
VALUES (src.message_id, src.message_timestamp, src.order_id, src.order_amount, src.receive_timestamp)
This scheduled query will scan:
- Only one partition of raw table
- One column (message_id because that is part of the merge ON clause) from all partitions of the deduplicated table. Can we optimise this ?
Also note that at query time (e.g.: when a consumer queries the deduplicated table to fetch orders for one month), the deduplicated table's partitions will also be scanned based on partition column based where clause.
Solution 4-B
We optimise the previous solution by replacing the scheduled merge query with a scheduled two step stored procedure.
- As a first step, we query the minimum and maximum message_timestamp from the latest partition of raw table like this: ```
SELECT
DATE(min(message_timestamp)) AS minimum_message_timestamp,
DATE(max(message_timestamp)) AS maximum_message_tiemstamp
FROM raw_partitioned_by_receive_timestamp.orders
WHERE
DATE(receive_timestamp) = CURRENT_DATE()-1
2. We can:
1. select entries from deduplicated table within the minimum_message_timestamp and maximum_message_tiemstamp window
2. compare the latest raw table's partition with the entries selected in previous step to figure out new entries that need to be added to the deduplicated table and then insert only those entries
INSERT INTO dedup.orders
WITH existing AS (
SELECT
message_id
FROM dedup.orders
WHERE
message_timestamp BETWEEN <> AND <>
)
SELECT
raw.*
FROM raw_partitioned_by_receive_timestamp.orders raw
LEFT JOIN existing
ON raw.message_id = existing.message_id
WHERE
receive_timestamp = CURRENT_DATE()-1
AND existing.message_id IS NULL
NOTE: It is important to perform these two steps separately and not combine them into one INSERT query because the partition based where clause provides cost benefit only if the operands are provided statically.
This scans:
- One column (message_timestamp) of latest partition of raw table
- All columns from latest partition of raw table
- One column (message_id) from few partitions of deduplicated table. Number of partitions scanned depends on the minimum and maximum message time obtained from the raw table's latest partition.
- At query time selected partitions of deduplicated table are also scanned
---
## Trade-offs
| | Sol 1 | Sol 3 | Sol 4-B
|-|-|-|-|
| **Uniqueness criteria** | Works efficiently only if upstream provided attributes are exactly same for duplicate entries with same message_id, and if only upstream provided attributes are required to be projected through the view | + Flexible uniqueness definition | + Flexible uniqueness definition |
| **Semantics** | + View semantics | Consumers need to work with functions. Functions do not have user friendly schemas like views | + View semantics
| **Latency** | + No delay | + No delay | Depends on the frequency of scheduled query |
| **Development / maintenance overhead** | + Simple to maintain | + Simple to maintain | Relatively complex to maintain. May even need alerting to check for accidental duplicates |
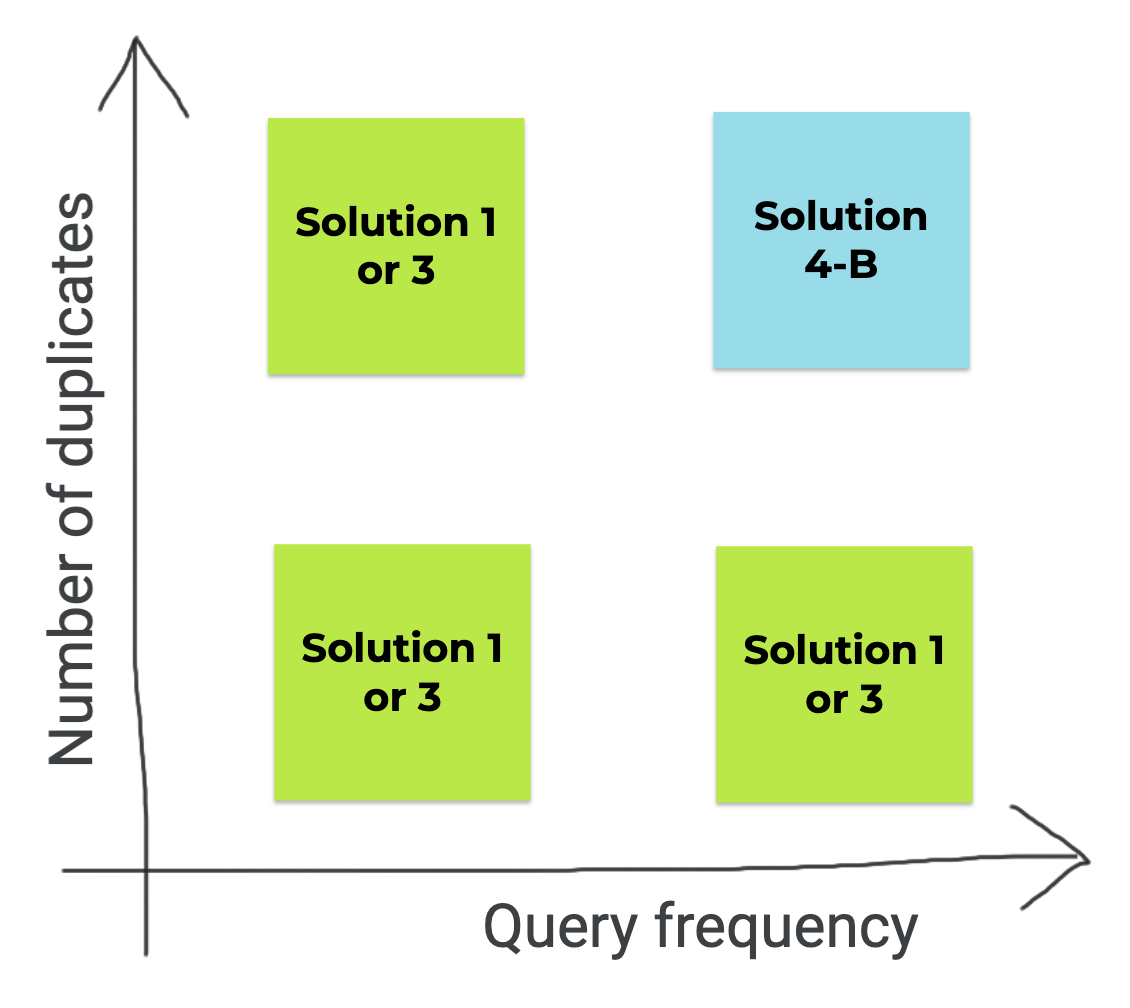
From a cost point of view, this is the decision matrix:

Top comments (0)