Creating cost optimized highly scalable cloud architecture is challenging but it is possible! Using Spot Amazon Elastic Compute Cloud (Amazon EC2) instances you can save up to 90% of on-demand pricing. In this article you will learn what spot instances and what should be your strategy to use spot instances. Additionally, I will give you scenarios where most of the customers are using spot instances.
Amazon EC2 Purchasing Options
Amazon Elastic Compute Cloud (Amazon EC2) offers 3 purchasing options:
- On-Demand
- Reserved Instances
- Saving Plans
- Spot Instances
All of the above Amazon EC2 purchase options are also available in Microsoft Azure and Google Cloud Platform (GCP). So if you are still in a Multi-Cloud environment still you must continue reading this article.
Normally, when you are designing your workload in the cloud. Make sure you combine all three of them to get better performance and huge cost savings. Amazon Auto Scaling Group (ASG) can help you to set up rules and conditions to add the desired type of the instances when set up correctly. You can combine on-demand, reserved and spot instances in a single ASG.
On-Demand Instances
Pay for compute capacity by the second or hour with no long-term commitments. Mostly you will use these instances for the spiky workloads or to define needs of your workload. Example: Netflix uses on-demand EC2 instances at off hours to split, encode the video files.

Reserved Instances
Significant discount (up to 70%) compared to on-demand instance pricing. You should use these types of instances for steady state applications or predictable usages, databases.
Example: your production servers or database servers or domain controllers that work regularly every year. You don’t want to turn them off for several years and keep these instances for the next 3-4 years or more. Then you can purchase reserved instances, with discounted prices and save huge costs.
Saving Plans
Same level of discount as you get from Reserved Instances however, you get more flexibility.
The flexibility to access computers across EC2 and AWS Fargate.

Spot Instances
Spare Amazon EC2 capacity for up to 90% discount compared to on-demand instance pricing. You can use these instances for fault tolerant stateless applications, instance flexible or time-sensitive workloads. Spot instances are identical to on-demand instances in terms of performance, infrastructure platform.

One thing to note is that AWS can reclaim these instances with just a 2 minute notice. Therefore, you must plan for a backup strategy while you are using spot instances. Or try to use the spot instances for the use case where you do not want to store the files, data, state or session. You should do stateless activities on spot instances to be on safer side. Amazon EC2 Spot instances are low cost, easy to use and flexible. In Big Data and Analysis use cases lots of customers are using spot instances.
AWS Spare Capacity
Amazon AWS does not reserve a minimum or maximum amount of capacity in spare. However, for the on-demand instances in order to give elasticity AWS has to keep spare capacity. Additionally, when a customer is not using on-demand instances then those capacity AWS keep it for spot customers to leverage the available capacity. AWS offers a huge up to 90% discount to spot customers with the caveat that whenever AWS needs the capacity back from you for on-demand customers, AWS will give you a 2-minute warning and take the server back off from you.
On average, every week, AWS customers are using more compute capacity on Amazon EC2 Spot Instances than customers in 2013 were running across all of Amazon EC2.
Spot Instance Use Cases
Spot instances are perfectly good for below scenarios:
- Fault-tolerant
- Flexible workloads
- Loosely coupled systems
- Stateless workloads
In all of these above scenarios, you can trade off spot instance interruption with the huge money saving. Many customers are using spot instances for below use cases:
- Big Data
- CI/CD
- Web Services
- HPC (High Performance Compute)
Big Data use cases you might have some state while computing and when you lose the computer with 2-minute notice then your work is interrupted. However, in order to not lose state make sure you are using non-instance state like s3, HDFS, etc.
CI/CD use cases you can use spot instances. In CI/CD server you run build, test etc. Maximum time CI/CD tasks, workflows and pipelines are well capable to handle any kind of server failure. Therefore, a good use case for spot instances.
WebServices can use spot instances. If you are designing stateless and scalable web services by creating multiple spot instances putting them behind the load balancer then in-case one machine is taken away by AWS, you have other capacity to server for future requests. Only 5% of the time your one instance will be interrupted by AWS so existing running work interruption chances are there but very less. Since most of the time your work will be finished.
High Performance Computers (HPC) can use spot instances. In the Finance domain most of the Grid that uses HPC with high throughput computing workloads which is loosely coupled can be done using spot instances. In Grid single node failing does not destroy the entire cluster. Similarly for big data we can use spot instances where anytime interruption occurs it’s just a matter of quickly reprocessing.
Spot Market
The Spot Market is the unique combination of instance type and availability zone. The supply and demand of the instance type in that availability zone is what drives the price.
The following screenshot shows a price comparison for different instance types. If you see the price history of c5 large instance types over the past 3 months it is pretty stable. In this graph below we are looking at the spot market for 4 different type of instances.

Spot Instance Best Practices
While AWS never runs out of spot capacity it is possible for a specific instance, for a specific zone might not be enough spot instances available for you. Therefore, if you ask for 100 spots you may get only 50 of them. So in order to solve this problem you should not be tied with one type of spot instance rather you should use the spot capacity pool given by AWS.
Additionally you must plan for interruptions since at 2 minute notice AWS can take back the spot instance from you. Over the last 3 months, 95% of spot instance interruptions were from a customer manually terminating the instance because the application had completed its work. So basically 5% of the time Amazon actually interrupts customers so 95% of time you should be able to work with spot instances without interruption.
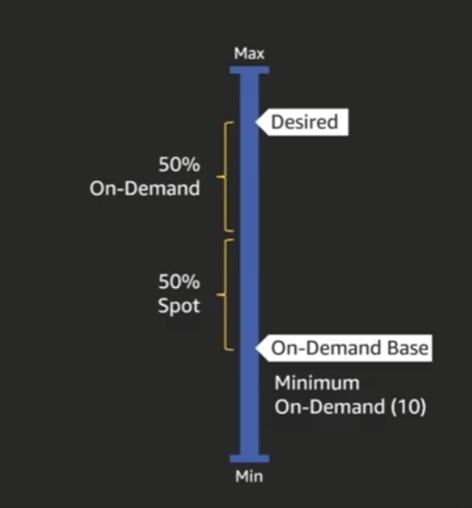
If you are architecting a highly scalable workload then Amazon auto scaling group (ASG) can help you to select the instance type, spot allocation strategy like cheapest instance, also define the split percentage between spot and on-demand instances and let ASG handle this AWS spot instance take back interruption. AWS will automatically spin up new spot instances. I have seen customers define base on-demand instances and in order to boost their application they utilize spot instances and save on 90% cost.
Either you can set up ASG to spin 100% spot instances on top of the on-demand instances as your base capacity.

Many customers also set up ASG to spin 50% spot instances and 50% on-demand instances on top of spot instances. Still keep their base capacity as on-demand instances.
Amazon EC2 Auto Scaling dynamically reacts to the changing demand and optimizes cost as well. ASG has Fleet management where it replaces unhealthy instances. ASG also has Dynamic scaling to scale on demand.
In order to optimize your Amazon EC2 workload combine the purchase options.
- In order to run steady-state workloads use reserved instances or saving plans,
- For bursty, new or stateful spiky workloads use on-demand instances and
- For fault tolerant applications, flexible and stateless workloads use spot instances.

Bursty Workload Optimization strategy with Spot Instances
Bursty Workload example
In typical capital market domain different types of analytical workloads are there such as below:
- Research
- How to increase profit or reduce risk of a portfolio
- Reactionary
- Human or an automatic system determine significant market volatility in the middle of trading day
- Overnight Jobs
- At the end of the trading day, you collect most recent input for your models and you run them at large scale
- Model backtesting
- When you make code changes to the model you need to test the changes with 10-20 years of historical data. High resource intensive workload and you need performance since you want to deploy the model in production as well.
In order to support such a high bursty workload you need infrastructure to auto spinning spot instances and shut them down once a task is done. You can use your own job scheduler or open source from HashiCorp as below.
Let’s take one high bursty workload example:
Trading desk running on 2000 core scale to 15,000 core scale during trading hours and overnight it runs about 30,000 core scale. This is the bursty nature of the system in action.
User sends the work job to Queue, the auto scaler docker container checks the state of capacity and talks to the provisioning system and spins up a couple of new capacities. Once the queue is drained it submits the request to shut down the extra capacity to the provisioning system.
2000 jobs are put on the queue at the beginning of trading day they drain quickly. Then 8000, 15000 jobs are put on the queue they drain quickly.
Similarly at the beginning in order to handle 2000 jobs you need 1000 workers then they all shut down again this is very bursty nature. Similarly at different time spans of the day different sets of workers will spin up like 3000 workers for 2 hours, next 4000-7000 workers for next 2 hours and so on. These are all bursty behaviour of your system.
Spot Instances Strategy for Bursty Workloads
How would you strategize your spot market such that you create a healthy and performant workload in this situation?
Diversified allocation strategy across as many instance pools as possible is the key to quickly achieving scale and minimizing the size of termination events.
- Configure your fleet to start up in multiple spot markets in parallel
- Build your Launch spec a large number of spot markets that you need to accept resources
- It will give you quick fleet whenever you need to compute in high volume
- Your instances are spread out across a large number of spot markets with few instances belonging to a single spot market.
- So if you get termination notification from AWS in one spot market it wont impact much in your over workload.
In order to spin up 32 instances each of 30,000 core clusters of spot instances may take an hour or so. Therefore, if you use multiple spot market pools in your launch specification that can reduce your fleet startup time to around 15 minutes. Your startup time can be sped up 70-80% with this diversified allocation strategy. So create a pool of instances and diversify them.
Make it as simple as possible. AWS gives variety of EC2 instances you can group machines by their features such as
- Compute intensive : high compute capacity category
- Memory intensive : memory optimized capacity category
- Standard : rest machines can be categorized as standard
This way you can abstract out the AWS terminologies, instance types, number of cores etc. Rather you define workload memory intensive if they require more memory during work.
Build in safeties governors everywhere. Tag your resources such that you know which team stakeholders are responsible for the payment. Put a threshold on capacity by applying some policy and governance to not spin 3000 vCore machines if you need only 1000 vCore. If you made a mistake and scale up unnecessary then you will end up paying a couple of thousands extra. Therefore, you have to apply strong governance and safety.
Monitor & Alert : If you have bursty large-scale systems where 30,000 vcore spot fleets and 3 or 4 of them running. However, if your system is not working then you are wasting your huge amount of money. Therefore, you must set up monitoring and alerts to send sms to the core team to get human involvement to tackle the next set of actions for a critical incident.
Summary
The Amazon bill is pretty complex. I am pretty sure every cloud provider bills must be the same structure. You have a lot of things and various associated costs with your virtual machines / EC2 instances. Therefore you must do your own maths and explore your cost in depth. There are many other costs you have to consider, not just the machines. Cost management is not a one day job. You must monitor them very frequently. You can check quarterly and also check future expected bills etc to learn more and tune them. Spot instances are great but power comes with responsibility. So make sure the applications that you are designing to run on spot are fault tolerant, stateless and scalable.
Thanks for reading my article till end. I hope you learned something special today. If you enjoyed this article then please share to your friends and if you have suggestions or thoughts to share with me then please write in the comment box.
💖 Say 👋 to me!
Rupesh Tiwari
Founder of Fullstack Master
Email: rupesh.tiwari.info@gmail.com
Website: RupeshTiwari.com






Top comments (0)