
At the beginning of last year we wrote about both the history of the data engineering "megatrend" and a few major trends in data engineering that we saw taking shape in 2021.
In this post, we wanted to share our thoughts on the data industry in 2022, first by reviewing the predictions we made in early 2021, then outlining our view of the state of data engineering with new predictions as we enter the new year.
Revisiting our 2021 predictions
It's been a year since our last set of predictions, so let's see how good of an oracle we were.
Our first prediction was that data would be discussed on the board level. Of course they are, without data to drive the discussion board meetings wouldn't be possible. But, we're kind of cheating here because that's not what we meant by this prediction. We missed on this one with too aggressive a stance. We haven't seen a data role report directly to the board yet, and that probably won't happen.
Data is extremely important, but its customers are primarily internal. Even when the customer is external, the product will guide the conversation. Now, what is increasingly happening at the board level is a review of the data competency of the organization, which ultimately translates to another vector of accountability for the leadership team.
The next prediction was that we would see dedicated data engineering support for each team. I think that we got very close on this one. Now, there are different structures emerging. For example, organizations might have one team of data engineers supporting all other teams, in other cases each team might have its own data engineer, but the details aren't important. More companies are realizing the need for dedicated data support across the organization, and we expect this trend to keep accelerating in 2022 (more below).
We also said that we would see more unicorns solving data problems. We were right on this. Even in an environment where the VC market is extremely inflated, some of the biggest rounds focused on data related companies. Clickhouse raising $250M and Airbyte's $150M are just two recent examples.
The commoditization of data platforms continues, and it will accelerate. The spearhead here is still pipelines and ELT, but we see more and more categories growing. For example, anything that has to do with data quality and observability. As the market is still young this effect will continue. It's still early, but there are plenty of signs, so we'll take a win on this one as well.
Real time and streaming infrastructure will become standard. We will take partial credit on this one. It's hard to tell if real time data has become more important than batch data, but companies are investing heavily in real time infrastructure and continue to do so. Two good examples of this trend are the amazing IPO of Confluent and new products like Apache Hudi that offer real time capabilities over data lakes. We would keep a very close eye on any company that comes up with a new product in this space in 2022.
The state of data engineering in 2022
Let's take a look at both the current state and a few predictions about the data space in 2022.
The data space is still young and trying to define itself
As we mentioned in our evaluation of the 2021 prediction on data unicorns, there's no question about how massive the industry is or how quickly it's growing.
Even though data tooling and engineering have been around for a relatively long time (Talend and Informatica are nearing the ripe old age of 20), modern cloud architectures are still relatively young, which is a major source of the excitement around the space. Some of the most popular tools used today were in their infancy less than 5 years ago. Even for history-making titans of the cloud data era like Snowflake and Databricks, the battle has just begun.
The excitement about how far we've come in a short time can make it easy to forget that we are still in early innings in the data space.
One indicator of the youth of the industry is the proliferation of new terminology, as well as difficulty in defining terms that have become common vernacular throughout the last year or two.
For example, when you say CRM, everyone thinks about Salesforce and has a really specific idea of the role that tool plays in the business. When you hear terms like "modern data stack," "operational analytics" or "data lakehouse," though, the average person working in data often has trouble offering articulate definitions. This is due in large part to the terms being coined by companies paving new ground with specific technologies, which their product marketing teams publicize.
Even the "modern data stack" itself lacks definition across the industry, and terms like "data fabric" and "data mesh" have been used to describe new architectures.
The industry will ultimately help shape definitions for specific tooling and architectural patterns as actual users layer the technology into their stacks and establish use cases.
The data stack is increasing in size and complexity
The data tooling we work with today is getting better and better. In an environment where specific data tasks that used to be really hard are made easy or even fully automated by good tooling, it can be hard to step back and appreciate that the "modern data stack" is actually growing in size and complexity.
Matt Turck's data and AI landscape reports are a great way to visualize this trend:
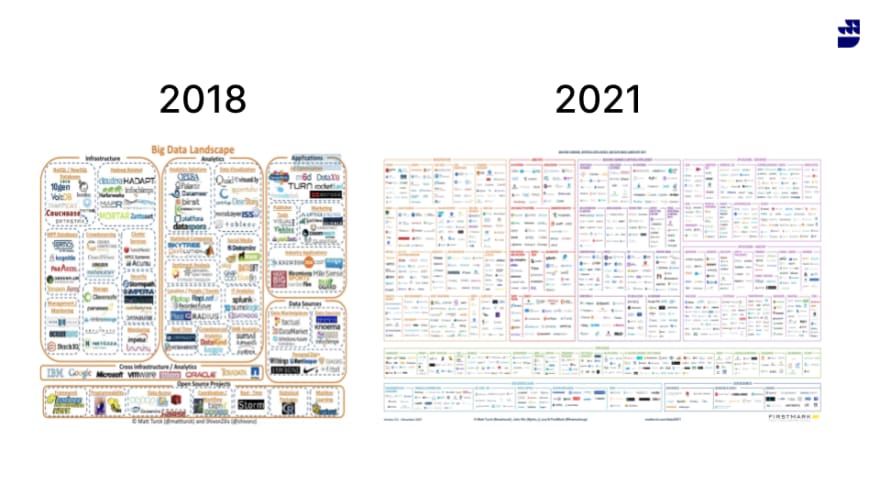
The cloud data warehouse and data lake have been established as central components, but the number and variety of tools surrounding and supporting them is exploding, and the rate of growth is increasing. This is happening as 'old' technologies are re-invented (ETL and CDC for example)new technologies (ML as a service on the warehouse) are added. Choice in high-quality tooling is ultimately a great thing for data professionals, but evaluation of options will become increasingly difficult.
As we wrote before, the marketing technology landscape went through a similar phase of explosion in tooling. Data infrastructure, though, is a different animal, and the stakes are much higher when the impact is stack-wide (as opposed to a problem with an email marketing tool).
The pain of dealing with increased complexity has accelerated another trend and created an entirely new class of data tooling that draws on software engineering principles.
Software development principles and processes are saturating the data space
This is an expected and welcome trend, but it's magnitude makes it worth noting. While data engineering is an engineering discipline, if you talk to software engineers who have entered the data space, they are always surprised by the lack of process and tooling for data compared with software development, i.e., version control, ops, testing, continuous integration, etc.
Teams and data leaders are rapidly implementing principles from software development, and a myriad of tools are being built to support them.
Observability is a hot topic and it's being built for the data use case, but we're also seeing products that fully embrace specific paradigms from software development, envisioning configurable 'package managers' for the entire end-to-end data stack.
At RudderStack, we see advanced data teams increasingly desire APIs from their data tooling that allow them to manage their data stack in a way that looks more and more like CI/CD processes from software development. We believe this trend will continue to take hold as data teams eschew the pain of dealing with a growing number of separate user interfaces for things like pipeline management.
Data quality and governance are really hard problems, and the jury is still out on how to solve them
Of all the challenges created by a stack that is increasing in complexity, data quality and governance are perhaps the most difficult to solve. This makes sense: governing a growing, dynamic system is hard.
Companies are trying to solve this at multiple points in the stack. Some approach the problem at the point of capture, others within pipelines themselves, and some apply governance in/on the data warehouse or data lake itself after the data has been loaded.
Lots of money has been invested in the companies building these kinds of products, but we've yet to see wide adoption of a stack-wide governance architecture that works well for a large number of companies. More often than not, data teams use a combination of the above methods combined with internally built tooling and processes, which we'd expect in the context of pipelines that feed cloud tools directly as well as internal data infrastructure, in addition to the warehouse/data lake.
It is surprising that governance mechanisms in/on the warehouse/data lake haven't seen mass adoption yet, especially as those data stores have been cemented as the center of the stack for modern companies. It could be that post-load governance isn't as valuable to data teams on the ground as it seems, or that this particular pain point is lagging behind warehouse/data lake centralization projects. We also wonder if, in part, modern tooling for analytics engineers, which solves governance in the specific context of reporting, makes more comprehensive governance less urgent.
In 2022 we will begin to see the emergence of architectural patterns that answer these questions.
ML in the data stack is a huge wave...
This is one of the more enjoyable trends to watch because more companies are doing incredible things with data.
For example, at RudderStack we see customers building and updating centralized customer profile stores in low-latency key-value stores (in real-time), exposing that database to their entire stack via APIs, then delivering ML-driven customer experiences (like recommendations) across their stack. Putting ML to work operationally in this way is evidence that "the future" is here.
These innovative architectures are made possible by the relationship between accessibility and cost, and the emergence of new technologies. It is becoming easier to use advanced technologies around ML and those technologies are becoming more cost effective. One investor describes this trend as "ML folding into the classic data stack."
ML isn't new, but historically the required quantities of data plus the complexity and cost of infrastructure were barriers of entry for most companies. The lingering effects of those barriers still exist---even today, many companies leverage ML for insights and learning, not driving actual customer experiences.
But that is changing quickly. Commoditization of data collection is solving the quantity problem, while standardization and deep out of the box integration are making the required infrastructure 'turn key.' One major, exciting trend here is ML-as-a-service, directly on the warehouse/data lake, which makes it easier than ever for companies of all sizes to build competence in operationalizing ML.
Another trend to keep an eye on is ML SQL. Python-Spark is the clear leader, but we see increasing numbers of our customers leveraging ML SQL with some pretty powerful results. BigQuery, in particular, is gaining significant traction in this space and there's no doubt other warehouse vendors will make advances in this space as well. ML tooling is still young, but SQL has the potential to truly democratize ML. We wouldn't be surprised if 2022 reveals powerful, creative ML architecture that leverages a dbt+ML/SQL-flavored toolset.
...but the most exciting days for analytics are just around the corner
Developments in ML for the data stack are very exciting, but if you zoom out and consider the broader market, you'll quickly learn that a huge number of companies are still working hard to build robust, scalable analytics.
Analytics can almost feel like a worn out term when it comes to the data space, or even a problem that has been mostly solved, but anyone close to analytics inside a fast growing or large, complex company knows that good, automated reporting is hard work.
The tools aren't to blame for the difficulty---data infrastructure and BI technology have never been better. It comes from what we mentioned above: companies are pulling more and more data into an increasingly complex stack. Analytics is already more of a journey than a destination, but in the modern context, it's a constantly moving target. One symptom of this problem is that localized analytics become really good, i.e., product or marketing, but comprehensive analytics across business functions become more elusive.
Tools for the modern stack and new analytics architectures are quickly solving that problem, which means that there are very exciting days ahead for data analytics.
One of the most promising developments is a "metrics layer" architecture, which abstracts analytics from specific, localized tooling (i.e, BI, product analytics, or even SQL on the warehouse) and allows teams to centrally manage stack-wide analytics data and modeling. This solution is being applied both in/on the warehouse and data lake directly, and via tools built on query engines, which extend the metrics layer metaphor to operate 'on top' of the entire stack regardless of the tools, leveraging MPP for analytics without having to move data. It's likely that companies will leverage both approaches at enterprise scale.
Another exciting trend is reverse-ETL. Reverse-ETL pipelines make it possible to send enriched or even synthetic data from the warehouse/data lake to both central and localized analytics tools, making those analytics even more powerful and valuable. (We discussed this exact architecture in a recent webinar with Snowflake and Mixpanel.)
We're also seeing companies build interesting analytics products based on known schemas---if the model is already defined, many reports can be completely automated by 3rd party SaaS. Practically, this means pointing a pipeline at the analytics tool and instantly getting access to robust dashboards without an analyst having to do any work at all. The widespread implementation of the metrics layer architecture will create a very interesting wave of innovation in this kind of fully automated analytics and BI.
Data roles and team structure are becoming competitive advantages
Behind all of these trends in data stack architecture and tooling is the massive movement of companies organizing themselves around the importance of data. One clear indicator of this is job openings for data engineers.
DICE's 2020 tech jobs report showed data engineering jobs were up 50% year over year. The bigger news, though, was the salary growth from 2018 to 2020, which was significant and now is on par with (or, in some cases, higher than) software engineering compensation. The war for engineering talent has always been fierce, and now data engineering specifically has become one of the primary battlefields.
But the bigger, long-term story is how smart data teams organize around the toolset to deliver value and trust across their organizations. Simply having a dedicated data function within the organization won't be enough---the highest performing companies will build modern data teams, not just modern data stacks.

Top comments (0)