
Context
As previously mentioned in another Redshift Flavored Automation Article AWS Redshift isn't that common and so tools on the internet are hard to come by.
Testing tables are important in the data world, did the criteria you specify work? Are there anomalies in your data?
But tables can be big and be made up of multiple different data points and logic. This can mean that to do due diligence for testing a table you might need to run five, ten, fifteen, even twenty separate checks on the table after its been built. Human nature means that this doesn't always happen, and certainly not consistently across every table and analyst.
One of my team vocalized this issue and we got talking about a checklist that we could generate once we've built a table to know what to test, this would also go a long way to helping the tester in seeing whats been mitigated. I played around with the idea of creating some VSCode plugin that reads your code and generates a checklist but the more I looked into it the more a different solution made more sense, and felt easier to do.
Why build a checklist of things to test, which would then require the analyst to create the test queries when I can just jump straight to building a tool that generates the test queries??? Sure this won't cover all scenarios but nothing ever would, the reason you built the table may never be apparent in the code.
So I knew what I wanted to build, however I only knew HTML/CSS, SQL/PLSQL, Batch and a splash of power shell. While I could have done this in PLSQL or power shell I saw this as a great opportunity to learn Python.
Version 1
I had briefly been exposed to Pandas and so I was familiar with data frames, a familiar to someone who works with data every day. A few Pandas tutorials later and I had a general direction.
Methodology
Where I landed in terms of a mechanic was to use the tables Data Definition Language or DDL which is the blueprint for how the table was created. See below for an example.

My script would read this DDL and then based on what data type the column was, String, Integer, Date, would spin off a bunch of per-fabricated tests. So if the column was a date it would spit out a query that tested the min and max value of that date column, something we do to check that we have got records in the correct date range.
I did this by getting the user to copy the DDL to their clipboard and then using the Pandas copy clipboard would ingest the DDL into the script.
sql_load = pd.read_clipboard(sep='\n',header=None, squeeze=1)
I then checked to make sure that the content being loaded was valid, the first word needed to be 'create' so I enforced that and forced an error if it didn't find that.If it did pass the test the script read what the table name was as this would be used later.
#GET FIRST ROW OF DDL
sql_header = sql_load.iloc[0]
#VALIDATE THAT THIS IS A VALID DDL
sql_validate = re.search(r'^\w*\b',sql_header, flags=re.U)[0]
sql_validate = sql_validate.upper()
if sql_validate != 'CREATE':
filename = "script_terminated_with_error.txt"
error_output = open(filename,"w")
error_output.write("If you are reading this message, the python script has terminated. \n")
error_output.write("Reason? The first word on the clipboard wasn't CREATE.\n")
error_output.write("This means you have not copied a valid Redshift SQL Table Create Statement to your clipboard. \n")
error_output.write("For more help refer to: https://github.com/ronsoak/SQL_Test_Script_Gen.\n")
error_output.close
os.startfile(fr'{filename}')
sys.exit("Not a valid DDL, must start with CREATE")
else: sql_table = re.search(r'\w+\.\w+',sql_header, flags=re.U)[0]
I decided that the output of this script would be written to a text file so I had to get python to create a text file, rename it the name of the table name and then write content to it. But tables are often called schema.tablename and we can't have a dot in a filename so I had to re-arrange how all that looked.
sql_table_file = sql_table.replace(".","][")
filename = "[table_testing]["+sql_table_file+"].txt"
filename = filename.lower()
sql_output = open(filename,"w")
So now I've got this whole DDL loaded in but the only thing I need are the column names and there data types, I don't need their compression types nor do I need the tables diststyle,distkey, or sortkey. So seeming I'm using data frames I went through the process of whittling down the entire DDL to just rows that contained a data type, to which I had loaded all of the possible data types into a list called red_types.
#LIST OF DATA TYPES
red_types = ("SMALLINT|INT2|INTEGER|INT|INT4|BIGINT|INT8|DECIMAL|NUMERIC|REAL|FLOAT4|DOUBLE|DOUBLE PRECISION|FLOAT8|FLOAT|BOOL|BOOLEAN|DATE|TIMESTAMP|TIMESTAMPTZ|CHAR|CHARACTER|NCHAR|BPCHAR|VARCHAR|CHARACTER VARYING|NVARCHAR|TEXT|GEOMETRY")
#READ THE COL NAMES AND DATA TYPES
sql_load = pd.Series(sql_load)
sql_load = sql_load.str.upper()
sql_load = sql_load.str.replace(r"\(\S*\)","")
sql_reduce = sql_load.loc[(sql_load.str.contains(fr'(\b({red_types})\b)', regex=True,case=False)==True)]
sql_reduce = sql_reduce.str.split(expand=True)
sql_cols = sql_reduce.loc[:,0:1]
sql_cols = sql_cols.rename(columns = {0:'COL_NAME',1:'DATA_TYPE'})
sql_cols['COL_NAME'] = sql_cols['COL_NAME'].str.replace(',','')
sql_cols['DATA_TYPE'] = sql_cols['DATA_TYPE'].str.replace(',','')
Then once I had whittled down the data frame to the exact rows I wanted, I created a function that wrote the tests to a text file dependent on the rows data type, and then looped through the data frame.
#DEFINE FUNCTION FOR PRINTING
def col_func(a,b,c):
if b in red_nums:
sql_output.write("select min("+a+"), avg("+a+"), max("+a+") from "+c+"; \n \n" )
sql_output.write("select median("+a+") from "+c+"; \n \n" )
elif b in red_dates:
sql_output.write("select min("+a+"), max("+a+") from "+c+"; \n \n" )
elif b in red_string:
sql_output.write("select "+a+", count(*) from "+c+" group by 1 order by 2 desc limit 50; \n \n" )
sql_output.write("select count(distinct("+a+")), count(*) from "+c+" limit 50; \n \n" )
elif b in red_bool:
sql_output.write("select "+a+", count(*) from "+c+" group by 1 order by 2 desc limit 10; \n \n" )
elif b in red_geo:
sql_output.write("Geospatial Data not currently supported. \n \n")
else:
sql_output.write("Column:"+a+"is not a know Datatype. Datatype passed was:"+b+"\n \n")
for index, row in sql_cols.iterrows():
col_func(row['COL_NAME'], row['DATA_TYPE'], sql_table)
Finally once the script was done, I wrapped a batch script around it so a user could just double click the script and they would be prompted to copy the DDL to their clipboard and then they could prompt the batch script to kick off the python script.
Outcomes
Once I had it up and running I gave it to my team to use and test. We encountered a few issues right off the bat, like the regex used to detect table names needed a few iterations. And data types that had parameters after them like varchar(300) continued to cause issues. It also would hard fail if the wrong thing was copied to the clipboard (like a file).
After a month of testing I showed it off to some other analysts and got them using it. It would throw an error every now and again but not the end of the world for my first python automation.
Learnings
I knew when I made the script that it was over-engineered and relied too heavily on external libraries and hacky workarounds. The header of my script looked like this.
#IMPORTS
import pandas as pd
import re
import warnings
import sys
import os
#SUPRESS WARNINGS
warnings.filterwarnings("ignore", 'This pattern has match groups')
I posted the script on a reddit thread looking for feedback and pretty succinctly was told that I shouldn't be using Pandas for this, and if I was going to use Pandas not to use itterows in it.
I knew I could do better.
Version 2
So I set out to rebuild this script not using Pandas, in fact as little external libraries as possible was my aim. So I brushed up on my lists, tuples, and dicts and got coding.
Methodology
Not using Pandas meant I couldn't copy a DDL off of the clipboard, native python can't do this, other libraries can but I decided the DDL could be in a text file and get loaded that way. So the first thing the batch file does now is open up the text file and gets the user to save the DDL into it.
So now I've locked the DDL load to a text file the next few steps are the same. Read the table name and prepare the output text file, and it's file name.
You will note that I've removed the validation that checks that the first word is 'Create' the analyst will figure it out soon enough.
#LOAD THE DDL
load_file = open('test_script_input.sql','r')
file_contents = load_file.readlines()
#GET THE TABLE NAME
table_head = file_contents[0:1]
table_name = re.search(r'\w+\.\w+',str(table_head), flags=re.U)
table_name = table_name.group(0)
table_name = str(table_name)
#FILE OUTPUT
sql_table_file = table_name.replace(".","][")
filename = "[table_testing]["+sql_table_file+"].txt"
filename = filename.lower()
sql_output = open(filename,"w")
So no data frames this time right? Which means the DDL has been loaded into a list. How did I refine that list down to just the right columns? Last time took 15 lines of code, this time it's all done in a one line lambda.
#RESTRICT TO APPLICABLE COLUMNS
valid_rows = list(filter(lambda x: re.search(r'\b(SMALLINT|INT2|INTEGER|INT|INT4|BIGINT|INT8|DECIMAL|NUMERIC|REAL|FLOAT4|DOUBLE|DOUBLE PRECISION|FLOAT8|FLOAT|BOOL|BOOLEAN|DATE|TIMESTAMP|TIMESTAMPTZ|CHAR|CHARACTER|NCHAR|BPCHAR|VARCHAR|CHARACTER VARYING|NVARCHAR|TEXT|GEOMETRY)',x,flags=re.IGNORECASE),file_contents))
The methodology is the same, looking for entries in the list that only contain a redshift data type, but this was vastly more elegant, I don't even need to have the data types loaded in a separate list. It could also handle full data type names, where before my script went to the effort to first reduce decimal(50,5) down to just decimal, then it would detect it, while in this script it can detect data types without needed to first remove the brackets.
The next steps are very similar. Now I've got my valid rows, I needed to convert some of the values into strings, and rather than pass the actual data types into the function I passed the high level type. So where it was a int, bigint, decimal I passed it as 'Number'.
#CREATE TEST SCRIPT
for table_line in valid_rows:
table_line = str(table_line)
col_name = table_line.split()[0:1]
col_name = str(col_name)[1:-1]
col_name = col_name.replace("'","")
col_name = col_name.replace("(","")
col_name = col_name.replace(")","")
dat_type = table_line.split()[1:2]
dat_type = str(dat_type)
if (re.search(r'\b(CHAR|CHARACTER|NCHAR|BPCHAR|VARCHAR|CHARACTER VARYING|NVARCHAR|TEXT)',dat_type,flags=re.IGNORECASE)): col_type= 'STRING'
elif (re.search(r'\b(SMALLINT|INT2|INTEGER|INT|INT4|BIGINT|INT8|DECIMAL|NUMERIC|REAL|FLOAT4|DOUBLE|DOUBLE PRECISION|FLOAT8|FLOAT)',dat_type,flags=re.IGNORECASE)): col_type= 'NUMBER'
elif (re.search(r'\b(BOOL|BOOLEAN)',dat_type,flags=re.IGNORECASE)): col_type = 'BOOL'
elif (re.search(r'\b(DATE|TIMESTAMP|TIMESTAMPTZ)',dat_type,flags=re.IGNORECASE)): col_type = 'DATES'
elif (re.search(r'\b(GEOMETRY)',dat_type,flags=re.IGNORECASE)): col_type = 'GEO'
else: col_type= 'BAD'
col_type = str(col_type)
script_gen(col_name,col_type,table_name)
In the previous version I generated one or two test queries per column type. This time I wanted to go further, and so I thought about more scenarios we would want to check, like if it's an number, checking the 25, 50, and 75 quartiles. I even added headings to give each area structure, while before it was a text file with a number queries. Needless to say my function got a lot bigger.
#SCRIPT_GEN FUNCTION
def script_gen(a,b,c):
if b == 'NUMBER':
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing for Column: "+a+"\n")
sql_output.write("-- Column Type: Number \n")
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing counts of column \n")
sql_output.write("select count(*) as row_count, count(distinct("+a+")) as distinct_values from "+c+"; \n \n" )
sql_output.write("-- Checking for nulls, are you expecting nulls? \n")
sql_output.write("select count(*) from "+c+" where "+a+" is null; \n \n" )
sql_output.write("-- Testing mins, avgs and max values \n")
sql_output.write("select min("+a+"), avg("+a+"), max("+a+") from "+c+"; \n \n" )
sql_output.write("-- Testing median, redshift doesn't like doing medians with other calcs \n")
sql_output.write("select median("+a+") from "+c+"; \n \n" )
sql_output.write("-- Testing 25% quartile, can be slow \n")
sql_output.write("select percentile_cont(.25) within group (order by"+a+") as low_quartile from "+c+"; \n \n" )
sql_output.write("-- Testing 50% quartile, can be slow\n")
sql_output.write("select percentile_cont(.50) within group (order by"+a+") as mid_quartile from "+c+"; \n \n" )
sql_output.write("-- Testing 75% quartile, can be slow\n")
sql_output.write("select percentile_cont(.75) within group (order by"+a+") as high_quartile from "+c+"; \n \n" )
elif b == 'DATES':
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing for Column: "+a+"\n")
sql_output.write("-- Column Type: Date \n")
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing counts of column \n")
sql_output.write("select count(*) as row_count, count(distinct("+a+")) as distinct_values from "+c+"; \n \n" )
sql_output.write("-- Checking for nulls, are you expecting nulls? \n")
sql_output.write("select count(*) from "+c+" where "+a+" is null; \n \n" )
sql_output.write("-- Checking for highs and lows, are they as you expected? \n")
sql_output.write("select min("+a+"), max("+a+") from "+c+"; \n \n" )
sql_output.write("-- Checking how many dates are in the future. \n")
sql_output.write("select count(*) from "+c+" where "+a+" >sysdate; \n \n" )
sql_output.write("-- Checking how many dates have a timestamp. \n")
sql_output.write("select count(*) from "+c+" where substring("+a+",12,8)<> '00:00:00'; \n \n" )
elif b == 'STRING':
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing for Column: "+a+"\n")
sql_output.write("-- Column Type: String \n")
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing counts of column \n")
sql_output.write("select count(*) as row_count, count(distinct("+a+")) as distinct_values from "+c+"; \n \n" )
sql_output.write("-- Checking for nulls, are you expecting nulls? \n")
sql_output.write("select count(*) from "+c+" where "+a+" is null; \n \n" )
sql_output.write("-- Top 50 values \n")
sql_output.write("select "+a+", count(*) from "+c+" group by 1 order by 2 desc limit 10; \n \n" )
sql_output.write("-- Check string lengths \n")
sql_output.write("select min(len("+a+")) as min_length,max(len("+a+")) as max_length from "+c+"; \n \n" )
elif b == 'BOOL':
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing for Column: "+a+"\n")
sql_output.write("-- Column Type: BOOL \n")
sql_output.write("-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- \n")
sql_output.write("-- Testing counts of column \n")
sql_output.write("select count(*) as row_count, count(distinct("+a+")) as distinct_values from "+c+"; \n \n" )
sql_output.write("-- Checking for nulls, are you expecting nulls? \n")
sql_output.write("select count(*) from "+c+" where "+a+" is null; \n \n" )
sql_output.write("-- Breakdown of boolean \n")
sql_output.write("select "+a+", count(*) from "+c+" group by 1 order by 2 desc limit 10; \n \n" )
elif b == 'GEO':
sql_output.write("Geospatial Data not currently supported. Suggest Something? \n \n")
else:
sql_output.write("Column:"+a+"is not a know Datatype. Datatype passed was:"+b+"\n \n")
And voila we get this:
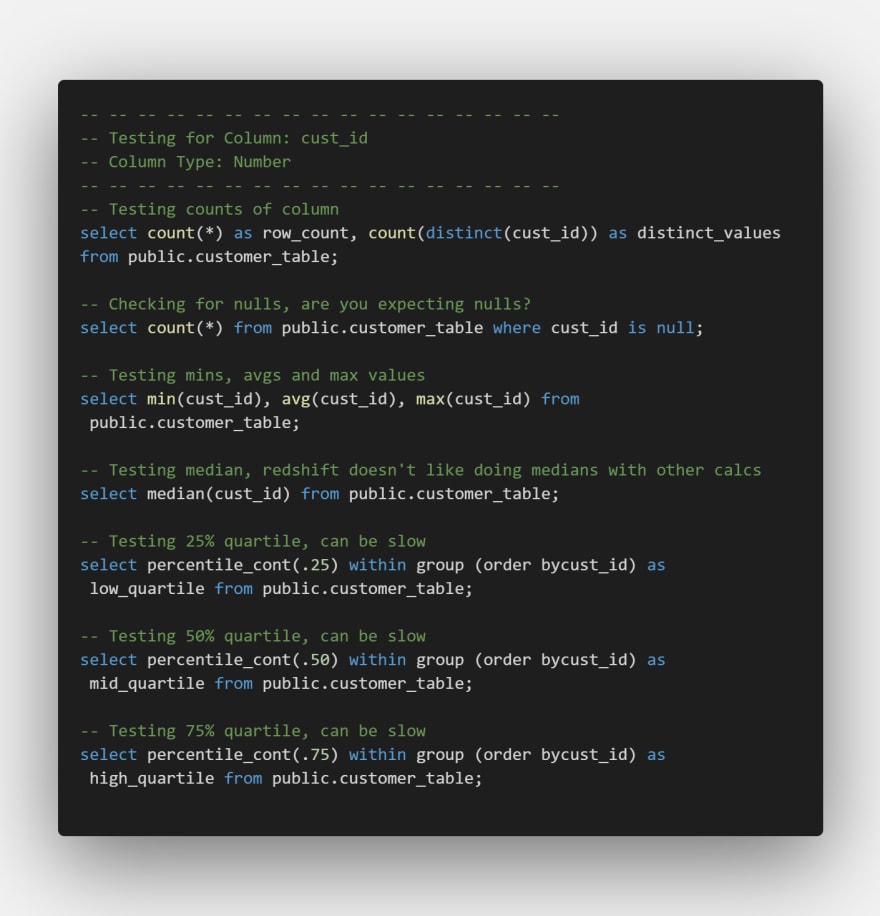
Outcomes
This script is a lot more 'pure' in my eyes, doesn't import an excessive amount of libraries and definitely no suppressed warnings. It can handle nuances in different code a lot better than the previous one did. Doesn't matter whether it's varchar(15) or varchar (400000) it handles both correctly.
Sure I've made a few compromises, like not validating the input, or allowing the user to just copy the DDL to the clipboard, it doesn't even open the test script automatically for them any more, but those are all very minor things that hardly impact the analyst.
Things to do in V3
Originally I wanted a GUI to load the DDL, where an input box would open up and the user would paste the DDL there. Couldn't quite spare the mental energy to learn Tkinter this time around but definitely something to explore.
Another thing I envisioned when I set out to rebuild this was that this would actually send the queries to our Redshift Enviroment, run them, and return the results. Again biting off more than I can chew on this pass, primarily because I don't have permission to install the command line postgress tool needed to send commands to Redshift at work so something I'll look into that another day.
Git Repo
 ronsoak
/
SQL_Test_Script_Gen
ronsoak
/
SQL_Test_Script_Gen
A python application for generating SQL test scripts based off of a table DDL.

SQL Test Script Generator
For Redshift Table Builds
What is this?
This is a python script that reads a table build written in Redshift Syntax and then for every column outputs a text file with some basic test scripts.
Why?
Part of thorough testing in SQL is ensuring that each column you have pulled through is operating as expected, this script quickly creates the basic tests you should run, leaving you to write more personalised tests.
Pre-requisites
- Latest version of Python 3.0+
- Tables built using Redshift, will not (currently) work on tables built in Oracle, TSQL,Postgresql,MySQL etc.....
Instalation / Configuration
- Download the git as a Zip, you only really need 'Launch_Me.bat' and 'Gen_Test_Script.py'
- Place these two files in the folder of your choosing
- Edit 'Launch_Me.bat' and go to line 11
- Edit 'C:/path to your python install/python.exe' to be where your python.exe is installed
- Edit 'c:/path to this script/Gen_Test_Script.py' to be…
Reminder: All views expressed here are my own and do not represent my employer, Xero.
Who am I?


 Ronsoak 🏳️🌈🇳🇿@ronsoak
Ronsoak 🏳️🌈🇳🇿@ronsoak Who Am I❓
Who Am I❓
|🇳🇿 |🇬🇧 |🏳️🌈
📊 Senior Data Analyst for @Xero
⚠️ My words do not represent my company.
✍️ Writer on @ThePracticalDev (dev.to/ronsoak)
✍️ Writer on @Medium (medium.com/@ronsoak)
🎨 I draw (instagram.com/ronsoak_art/)
🛰️ I ❤️ space!03:11 AM - 13 Oct 2019







Top comments (2)
Nice work. In a way, not using the clipboard could have another silver lining. By not relying on the user to select the right stuff, the script becomes more deployable and more iterable. You can maybe put it up in an AWS lambda that is triggered if a DDL hits an S3 bucket. You can also write another script which will run this script over all the text files in a folder :)
Great stuff!
Lambda on a lambda!