
Positional Embeddings always looked like a different thing to me, so this post is all about explaining the same in plain english..
We all hear and read this word ("Positional Embeddings") wherever Transformer Neural Network comes up and now as Transformers are everywhere from Natural Language Processing to Image Classification(after ViT), it becomes more important to understand them.
What are Positional Embeddings or Positional Encodings?
Let's take an example : Consider the input as "King and Queen". Now if we change the order of the input as ""Queen and King", than the meaning of the input might get change. Same happens if the input is in the form of 16*16 images(as it happens in ViT), if order of images changes, than everything changes.

Also, the transformer doesn't process the input sequentially, Input is processed in parallel.

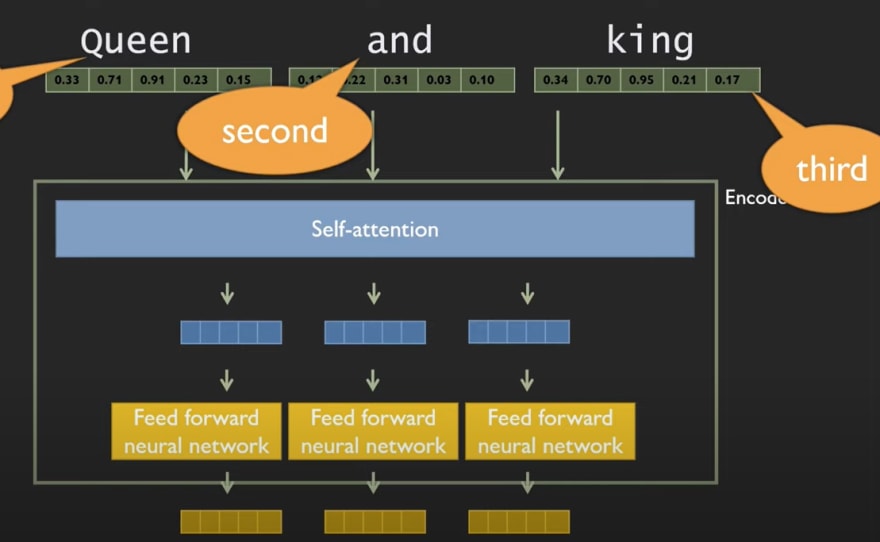 For each element it combines the information from the other element through self-attention, but each element does this aggregation on its own independently of what other elements do.
For each element it combines the information from the other element through self-attention, but each element does this aggregation on its own independently of what other elements do.
The Transformer model doesn't model the sequence of input anywhere explicitly. So to know the exact sequence of input Positional Embeddings comes into picture. They works as the hints to Transformers and tells the model about the sequence of inputs.
These embeddings are added to initial vector representations of the input.
 Also,Every position have same identifier irrespective of what exactly the input is.
Also,Every position have same identifier irrespective of what exactly the input is.


There is no notion of word order (1st word, 2nd word, ..) in the initial architecture. All words of input sequence are fed to the network with no special order or position; in contrast, in RNN architecture, n-th word is fed at step n, and in ConvNet, it is fed to specific input indices. Therefore model has no idea how the words are ordered. Consequently, a position-dependent signal is added to each word-embedding to help the model incorporate the order of words. Based on experiments, this addition not only avoids destroying the embedding information but also adds the vital position information.
The specific choice of (sin, cos) pair helps the model in learning patterns that rely on relative positions.
Further Reading: Article by Jay Alammar explains the paper with excellent visualizations.
The example on positional encoding calculates PE(.)the same, with the only difference that it puts sin in the first half of embedding dimensions (as opposed to even indices) and cos in the second half (as opposed to odd indices). This difference does not matter since vector operations would be invariant to the permutation of dimensions.
This article is inspired by this Youtube Video from AI Coffee Break with Letitia
That's all folks.
If you have any doubt ask me in the comments section and I'll try to answer as soon as possible.
If you love the article follow me on Twitter: [https://twitter.com/guptarohit_kota]
If you are the Linkedin type, let's connect: www.linkedin.com/in/rohitgupta24
Have an awesome day ahead 😀!

Top comments (0)