
What is Generative Modeling?
Let’s understand this with an example. Suppose that we have a dataset of some rare species of animals on the planet. Since those are rare species the dataset won’t contain enough pictures for our model to learn from and this might lead to underfitting of the model.
To tackle this, we wish to build a model that can generate a new image of the species that never existed but still looks real because the model has learned the general rules that govern the appearance of a species.
In short, generative modeling is generating something new in terms of a probabilistic model. By sampling from this model, we are able to generate new data.
It is our goal to build a model that can generate new sets of features that look as if they have been created using the same rules as the original data. As easy as it may sound, for image generation this is an incredibly difficult task, considering the number of pixels associated with an image and the probability associated with them.
A generative model must also be probabilistic rather than deterministic. Let’s suppose we govern our model with a rule to generate images based on the average value of each pixels in the dataset. This is not the characteristic of a generative model. Rather, the model must include a stochastic element (random noise) which influences the individual samples generated by the model.
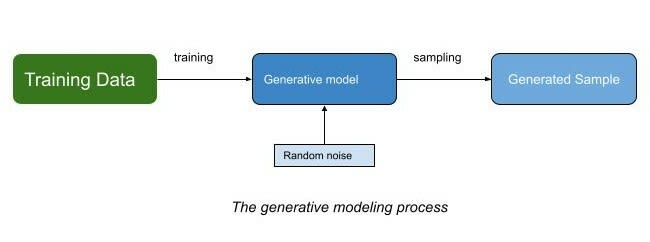
Generative versus Discriminative modelling
To truly understand what a generative model tries to achieve, we must compare it to it’s counterpart, Discriminative modelling.
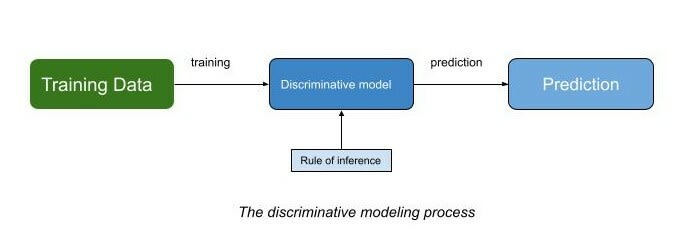
So what is discriminative modeling ? A simpler answer would be, a model which discriminates between two or more objects and identifies which is what.
In a cats vs dogs model, the main aim is to identify which image is of cat and which one is of a dog. The model learns about the several details on how to differentiate between a cat and a dog and draws a rule based on which it can perform inference.
The dataset consists of two parts, an observation and a label. For a binary classification problem for cats vs dogs, the image of cat would be labeled as 0 and the image of a dog would be labeled as 1.
Discriminative model is somewhat similar to supervised learning but not exactly. Generative modeling is usually performed with an unlabeled dataset (form of unsupervised learning), though it can also be applied to labeled dataset as well.
In mathematical notations, we can represent Generative and Discriminative models as follows:
Generative modeling estimates p(x) —- the porbability of observing an observation x.
If the data is labeled then it is represented as p(x | y).Discriminative modeling estimates p(y | x) —- the probability of a model y given observation x.
In general, discriminative modeling aims to estimate the probability that an observation x belongs to category y whereas generative modeling aims to estimate the probability of seeing the observation at all.
Hope you had a good read! :)
Please do give it a like.

Top comments (1)
You can also try writing on early and late Fusion of models as well