Pixel-comparison based visual regression testing

When you see that Netflix has a simple visual bug on their website for over three months now (still life as of August 2019, visit http://devices.netflix.com/en/), the trend towards visual regression testing of websites is understandable. This approach guards you from unexpected changes (for which writing assertions is impossible) and is much more complete than assertion-based testing. Most current approaches today are pixel based, meaning that they compare screenshots of the pages pixel-by-pixel. This makes a lot of sense:
- The first version of a pure pixel-diffing tool is easy to implement.
- It works for any browser, app or other situation, as long as a screenshot can be retrieved.
- It gives instant results.
However, there are also some downsides to pixel-based visual regression testing:
- Similar changes cannot easily be recognized: e.g. if the header or footer of the site changes, this affects all tests.
- You usually get a lot of false positives, as even a small change can result in many elements changing e.g. position.
- Filtering these false positives is tricky, because it can result in either too many false positives (irrelevant changes being reported) or false negatives (important changes being missed).
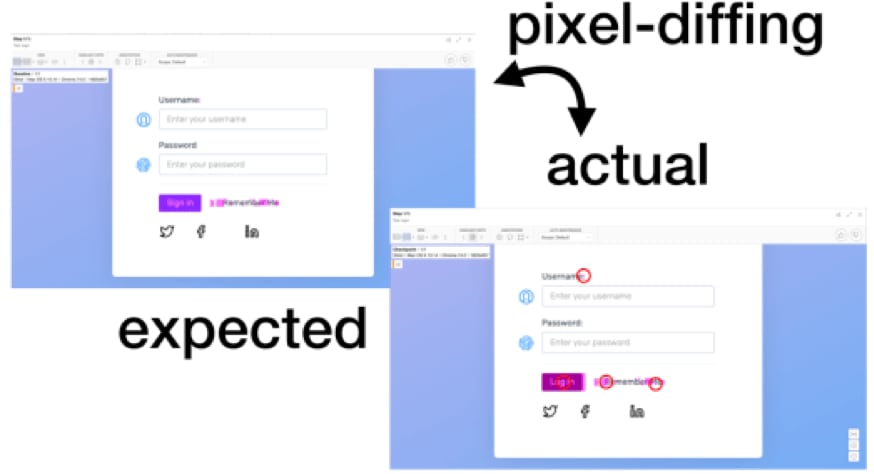
In the below example, you see all of this play out. The demoed tool uses an AI algorithm to filter the differences for artifacts. As you can see, it produces both false negatives – the added colon after “Password” being missed – and false positives – the “Remember Me” checkbox did not change but was merely moved to the left as a whole.
Deep visual regression testing
recheck-web goes a different route and compares all rendered elements and their respective CSS attributes. So instead of being reported that the pages differ in pixel, where a human has to review the difference and interpret it, recheck reports the exact way in which they differ:

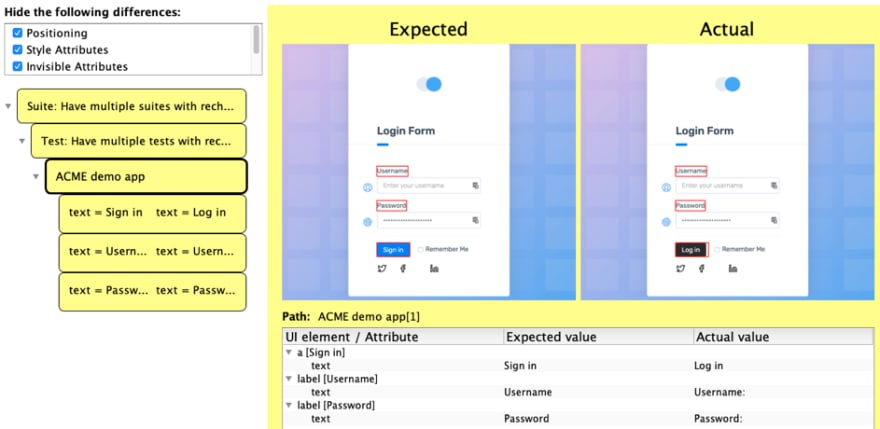
As you can see, as the text of the button changed from “Sign in” to “Log in”, the type of the element changed from a (a link) to button. Also, the class changed from btn-primary to btn-secondary. All other changes to the button are probably a result of those last two changes. The changes in the labels (added colons) were truthfully reported.
Since these are now semantic changes in contrast to pixel differences, it is easy to add rules and filters for handling them. Both the review GUI and CLI come with predefined filters. For instance, for the given situation, you could choose to ignore all invisible differences (class, type, background color, etc.). You could also choose to ignore all changes to any CSS style attributes, focusing only on relevant content changes (i.e. text).
Filtering changes
In the case of the changed login button, filtering all of these would show only the changes below.
This powerful mechanism lets you quickly focus on changes that are relevant to you. This works for CSS animations (try pixel-diffing that: http://www.csszengarden.com/215/) as well as for websites that are completely different in layout, but not in content. With this mechanism, you can easily ignore font but not text or color but not size.
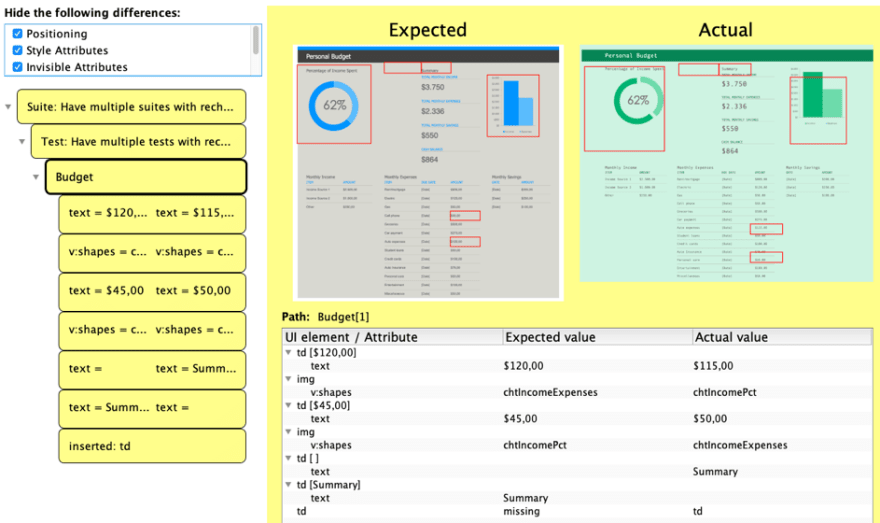
It lets you see where these two differ in content:
Even better – you can create your own filters using a simple git-like syntax. For instance, you can filter specific elements (e.g. of tag meta) with: matcher: type=meta. To filter attributes globally (e.g. for the class attribute), use: attribute=class. To ignore attributes e.g. of specific elements (e.g. alt of images), use: matcher: type=img, attribute: alt. You can also use regex for both elements or attributes: attribute-regex=data-.*.
More details and examples can be found in the documentation.
Use recheck in your own automated tests (https://retest.de/recheck-open-source/) or demo it using the Chrome Extension (https://retest.de/recheck-web-chrome-extension/).

Top comments (0)