
A year ago we evaluated Rockset on the Star Schema Benchmark (SSB), an industry-standard benchmark used to measure the query performance of analytical databases. Subsequently, Altinity published ClickHouse’s results on the SSB. Recently, Imply published revised Apache Druid results on the SSB with denormalized numbers. With all the performance improvements we've been working on lately, we took another look at how these would affect Rockset's performance on the SSB.
Rockset beat both ClickHouse and Druid query performance on the Star Schema Benchmark. Rockset is 1.67 times faster than ClickHouse with the same hardware configuration. And 1.12 times faster than Druid, even though Druid used 12.5% more compute.
Rockset executed every query in the SSB suite in 88 milliseconds or less. Rockset is faster than ClickHouse in 10 of the 13 SSB queries. Rockset is also faster than Druid in 9 queries.
The performance gains over ClickHouse and Druid are due to several enhancements we made recently that benefit Rockset users:
- A new version of the on-disk format for the column-based index that has better compression, faster decoding and computations on compressed data.
- Leveraging more Single Instruction/Multiple Data (SIMD) instructions as part of the vectorized execution engine to take advantage of higher throughput offered by modern processors.
- The introduction of a custom block size policy in RocksDB to increase the throughput of large scans in the column-based index.
- The automated splitting of column-based clusters to improve the read throughput and ensure all column clusters are properly sized.
- A more efficient check for set containment to reduce compute costs.
- The caching of column-based clustering metadata to improve aggregation performance.
As a result of these performance gains, users can build more interactive and responsive data applications using Rockset.
SSB Configuration & Results
The SSB measures the performance of 13 queries typical of data applications. It is a benchmark based on TPC-H and designed for data warehouse workloads. More recently, it has been used to measure the performance of queries involving aggregations and metrics in column-oriented databases ClickHouse and Druid.
To achieve resource parity, we used the same hardware configuration that Altinity used in its last published ClickHouse SSB performance benchmark. The hardware was a single m5.8xlarge Amazon EC2 instance. Imply has also released revised SSB numbers for Druid using a hardware configuration with more vCPU resources. Even so, Rockset was able to beat Druid’s numbers on absolute terms.
We also scaled the dataset size to 100 GB and 600M rows of data, a scale factor of 100, just like Altinity and Imply did. As Altinity and Imply released detailed SSB performance results on denormalized data, we followed suit. This removed the need for query time joins, even though that is something Rockset is well-equipped to handle.
All queries ran under 88 milliseconds on Rockset with an aggregate runtime of 664 milliseconds across the entire suite of SSB queries. Clickhouse’s aggregate runtime was 1,112 milliseconds. Druid’s aggregate runtime was 747 milliseconds. With these results, Rockset shows an overall speedup of 1.67 over ClickHouse and 1.12 over Druid.
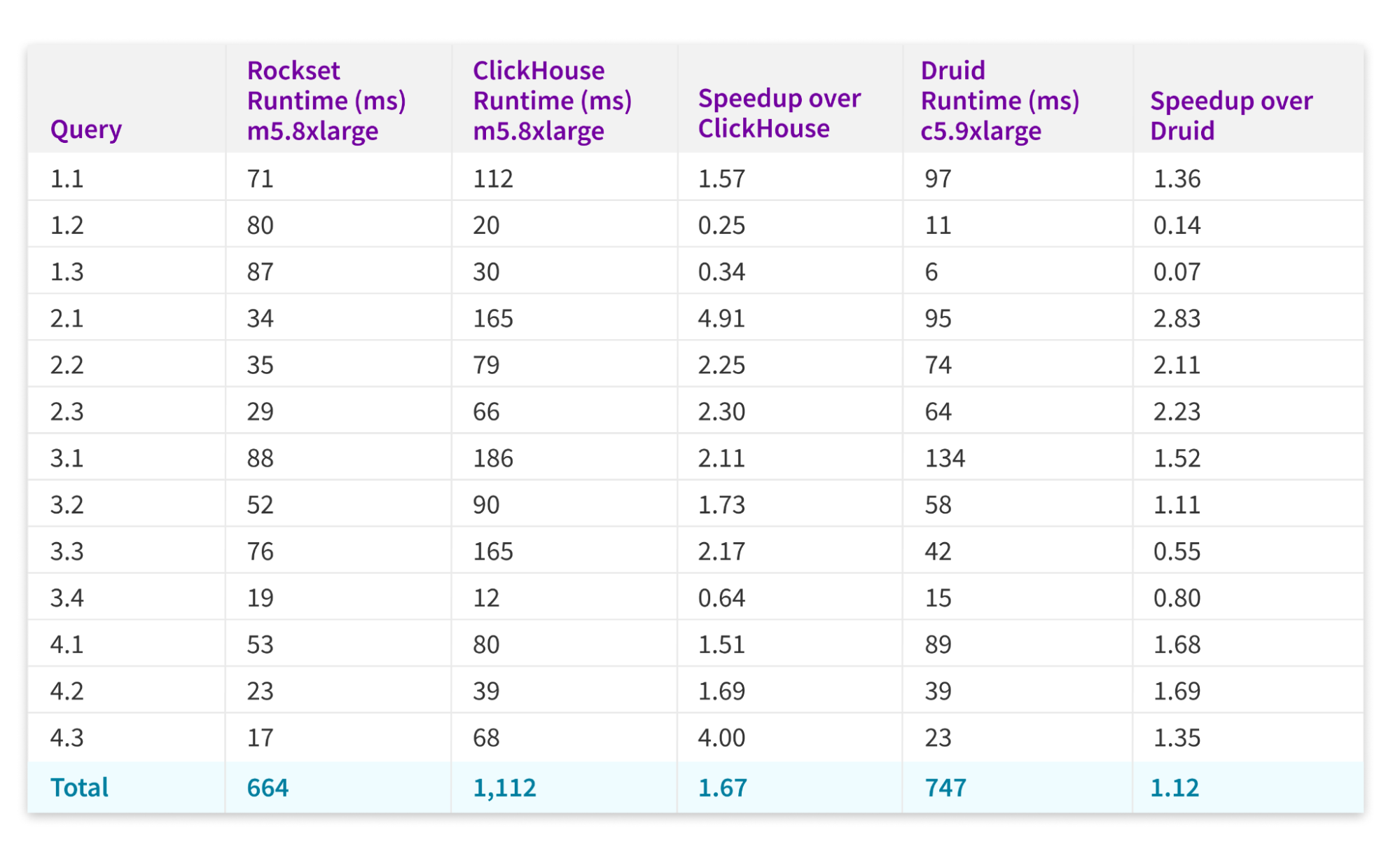
Figure 1: Chart comparing ClickHouse, Druid and Rockset runtimes on SSB. The configuration of m5.8xlarge is 32 vCPUs and 128 GiB of memory. c5.9xlarge is 36 vCPUs and 72 GiB of memory.

Figure 2: Graph showing ClickHouse, Druid and Rockset runtimes on SSB queries.
You can dig further into the configuration and performance enhancements in the Rockset Performance Evaluation on the Star Schema Benchmark whitepaper. This paper provides an overview of the benchmark data and queries, describes the configuration for running the benchmark and discusses the results from the evaluation.
Rockset Performance Enhancements
The execution plan for all queries in the SSB benchmark is similar. They involve a clustered scan followed by evaluating functions, applying filters and calculating aggregations. The speed up in Rockset queries comes from a common set of performance enhancements. So, we cover the performance enhancements that contributed to the query speed in the benchmark below.
New On-Disk Format for the Column-Based Index
Rockset uses its Converged Index to organize and retrieve data efficiently and quickly for analytics. The Converged Index is composed of a search index, column-based index and a row store. Rockset introduced a new on-disk format for the column-based index that supports dictionary encoding for strings.
This means that if the same string is repeated multiple times within one chunk of data in the column-based index, the string is only stored on disk once, and we just store the index of that string. This reduces space usage on disk, and since the data is more compact, it is faster to load from disk or memory. We continue to store the strings in dictionary encoded format in memory, and we can compute on that format. The new columnar format also has other advantages, like handling null values more efficiently, and it is more extensible.
SIMD Vectorized Query Execution
Query execution operators exchange and process data chunks, which are organized in a columnar format. In vectorized query execution, operations are performed on a set of values rather than one value at a time in a data chunk for more efficient query execution. With SIMD instructions, we leverage modern processors that can compute on 256 bits or 512 bits of data at a time with a single CPU instruction.
For example, the _mm256_cmpeq_epi64 intrinsic can compare four 64-bit integers in a single instruction. For batch processing operations, this can substantially increase throughput. The comparison itself isn’t the end of the story though. SIMD instructions typically operate within a lane - so if you use four 64-bit inputs, you get four 64-bit outputs. That means instead of getting booleans as outputs, you get four 64-bit integers at the output. Typically when operating on booleans, you either want an array of booleans as the output, or a bitmask. We took great care to optimize that conversion step to see the maximum possible performance gain from SIMD.
RocksDB Block Size
RocksDB is a high-performance embedded storage engine used by modern datastores like Kafka Streams, ksqlDB and Apache Flink. Rockset stores its indexes on RocksDB. As the SSB queries access data using the column-based index, larger storage blocks were configured for that index to improve throughput.
RocksDB divides data into blocks. These blocks are the unit of data lookup for various operations, like reading from disk or reading from RocksDB’s in-memory block cache. The size of these blocks is configurable. Larger blocks help with throughput for large scans because you need to do fewer total lookups in the block cache and fewer random accesses to main memory. Smaller blocks help with performance for point lookups because if you only need one key you can load less surrounding data. The cost of loading a large block does not amortize well if you only need 1% of the data in it. You also waste space in the cache by storing data that was not recently accessed.
For Rockset’s inverted index and row-based index, which are often used for point lookups, a small block size makes sense. For the column-based index though, which is often used for bulk scans, a much larger block size improves throughput. We created a custom block size policy under the hood to tune the block size for each index independently and increased the size of the column-based index blocks.
Performance Gains for Rockset Users
Rockset is 1.67 times faster than ClickHouse and 1.12 times faster than Druid on the Star Schema Benchmark. Data engineering teams have over the years put up with a tremendous amount of complexity in the name of performance when using ClickHouse and Druid. Teams have traditionally had to do time-consuming data preparation, cluster tuning and infrastructure management in order to meet the performance requirements of their application. Rockset, with Converged Indexing and built-in data connectors, is the easiest real-time analytics platform to scale. We’re happy to share it also has the fastest query performance. Try Rockset and experience the performance enhancements on your own dataset and queries.

Authors: Ben Hannel, Software Engineering, and Julie Mills, Product Marketing
Rockset is the real-time analytics database in the cloud for modern data teams. Get faster analytics on fresher data, at lower costs, by exploiting indexing over brute-force scanning.

Top comments (0)