kafkacat gives you Kafka super powers 😎
I’ve written before about kafkacat and what a great tool it is for doing lots of useful things as a developer with Kafka. I used it too in a recent demo that I built in which data needed manipulating in a way that I couldn’t easily elsewhere. Today I want share a very simple but powerful use for kafkacat as both a consumer and producer: copying data from one Kafka cluster to another. In this instance it’s getting data from Confluent Cloud down to a local cluster.
Why would I want to copy data from one Kafka cluster to another? In this instance it was because I had set up a pipeline streaming data into one cluster (on Confluent Cloud) and I needed that data locally so that I could work on building code around it whilst offline. Offline happens less and less often nowadays but it still happens—on many flights, and often at conferences/hotels with "WiFi" that isn’t.
There are several proper ways to replicate data from one Kafka cluster to another, including MirrorMaker (part of Apache Kafka) and Replicator (part of Confluent Platform). If what I needed was a proper solution then obviously I’d reach for Replicator—but here I just needed quick & dirty, didn’t care about replicating consumer offsets etc.
Unix pipelines are a beautiful thing, because they enable you to build fantastically powerful processing out of individual components that each focus on doing their own thing particularly well. kafkacat fully supports the pipelines concept, which means that you can stream data out of a Kafka topic (using kafkacat as a consumer) into any tool that accepts stdin, and you can also take data from any tool that produces stdout and write it to a Kafka topic (using kafkacat as a producer).
Guess what happens when you hook up two kafkacat instances, one consuming and one producing? A delightful thing happens; you read from one topic and write to another!

At a very simply level you can do this:
kafkacat -b localhost:9092 -C -t source-topic -K: -e -o beginning | \
kafkacat -b localhost:9092 -P -t target-topic -K:
That will take every message on source-topic and write it to target-topic on the same cluster. Some flags:
-Koutput/parse keys separated by:-eexit once at the end of the topic
The above will run once, and you get a copy of that topic at the point in time at which the script runs. If you re-run it you’ll get another full copy of the data.
What about if you want to resume consumption after each execution, or even scale it out? kafkacat supports consumer groups!
kafkacat -b localhost:9092 \
-X auto.offset.reset=earliest \
-K: \
-G cg01 source-topic | \
kafkacat -b localhost:9092 -t target-topic -K: -P
The arguments are a bit different this time. We replace -C (consumer) and specifying the topic with -t
-C -t source-topic
with -G to specify using the balanced consumer, its name, and which topic(s) to subscribe to
-G cg01 source-topic
We also change -o beginning for -X auto.offset.reset=earliest. When this is run we see the partitions of the six-partition topic that have been assigned to it:
% Group cg01 rebalanced (memberid rdkafka-894c0f84-9464-42dd-b76a-885420b6c557): assigned: source-topic [0], source-topic [1], source-topic [2], source-topic [3], source-topic [4], source-topic [5]
% Reached end of topic source-topic [2] at offset 11
% Reached end of topic source-topic [0] at offset 0
% Reached end of topic source-topic [1] at offset 0
% Reached end of topic source-topic [5] at offset 0
% Reached end of topic source-topic [3] at offset 0
% Reached end of topic source-topic [4] at offset 0
and if we run a second instance of it with the same consumer group id both rebalance:
-
Instance 1
% Group cg01 rebalanced (memberid rdkafka-894c0f84-9464-42dd-b76a-885420b6c557): assigned: source-topic [3], source-topic [4], source-topic [5] -
Instance 2
% Group cg01 rebalanced (memberid rdkafka-2416395f-7232-4fc0-8fbc-121d3bbc3758): assigned: source-topic [0], source-topic [1], source-topic [2]
Copying data from Confluent Cloud to a local Kafka cluster
Now let’s add Confluent Cloud into the mix—or any other secured Kafka cluster for that matter. We just need a few extra parameters in our call :
kafkacat -b $CCLOUD_BROKER_HOST \
-X security.protocol=SASL_SSL -X sasl.mechanisms=PLAIN \
-X sasl.username="$CCLOUD_API_KEY" -X sasl.password="$CCLOUD_API_SECRET" \
-X ssl.ca.location=/usr/local/etc/openssl/cert.pem -X api.version.request=true \
-X auto.offset.reset=earliest \
-K: \
-G copy_to_local_00 source-topic | \
kafkacat -b localhost:9092,localhost:19092,localhost:29092 \
-t target-topic \
-K: -P
And off we go. How can we check it’s worked? kafkacat of course! We can sample some records:
$ kafkacat -b localhost:9092 -t source-topic -o beginning -e -C -c 5
{"batt":97,,"acc":200,"p":98.689468383789062,"bs":1,"vel":0,"vac":93,"t":"u","conn":"w","tst":1569316069,"alt":97,"_type":"location","tid":"FF"}
{"cog":193,"batt":45,"acc":16,"p":100.14543914794922,"bs":1,"vel":0,"vac":3,"conn":"w","tst":1569330854,"tid":"RM","_type":"location","alt":104}
{"batt":97,,"acc":200,"p":98.689468383789062,"bs":1,"vel":0,"vac":93,"t":"u","conn":"w","tst":1569316069,"alt":97,"_type":"location","tid":"FF"}
{"cog":193,"batt":45,"acc":16,"p":100.14543914794922,"bs":1,"vel":0,"vac":3,"conn":"w","tst":1569330854,"tid":"RM","_type":"location","alt":104}
{"batt":97,,"acc":200,"p":98.689468383789062,"bs":1,"vel":0,"vac":93,"t":"u","conn":"w","tst":1569316069,"alt":97,"_type":"location","tid":"FF"}
and we can count how many are currently in the topic:
$ kafkacat -b localhost:9092 -t target-topic -o beginning -e|wc -l
% Auto-selecting Consumer mode (use -P or -C to override)
% Reached end of topic target-topic [0] at offset 1668: exiting
1668
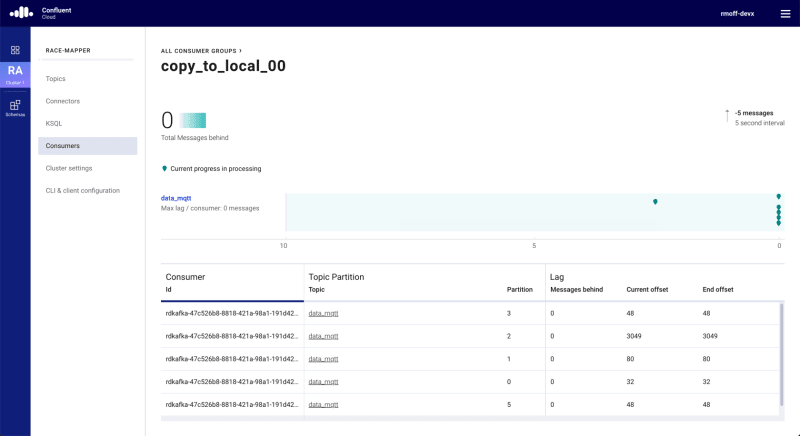
We can see the consumer group in Confluent Cloud (with similar views in Confluent Control Center if you’re running Apache Kafka for yourself), showing any lag in each consumer:
Like I said above, there are dozens of reasons why you would not want to use this method for getting data from one Kafka cluster to another, including:
No copying of offsets from source to target cluster
Probably mangles binary data
Doesn’t copy topic properties (partition count, replication factor) from source to target
Doesn’t copy headers
Hacky as hell!




Top comments (0)