In this tutorial I will show you how we go from network data to a rectangular format that is suited for machine learning.
Many things in the world are graphs (networks). For instance: real-life friendships, business interactions, links between websites and (digital) social networks. I find graphs (the formal name for networks) fascinating, and because I am also interested in machine learning and data engineering, the question naturally becomes:
How do I get (social) network data into a rectangular structure for ML?
Predicting connections
In this tutorial I’m taking data from a network and modify it so we can use it later on to answer the following question:
Can we predict if two nodes in the graph are connected or not?
But let’s make it very practical:
Let’s say you work in a social media company and your boss asks you to create a model to predict who will be friends, so you can feed those recommendations back to the website and serve those to users.
You are tasked to create a model that predicts, once a day for all users, who is likely to connect to whom.
I will show you how I would do it with the following steps:
- load a flat file into R and turning it into a graph format
- finding connections between ‘users’ to predict for (positive examples)
- finding non-connections between ‘users’ to predict for (negative examples)
- creating features to use in machine learning
- creating a dataset with positive examples, negative examples and features
I leave the actual predicting for another post, this post is about making the data suitable for ML.
A small detour into networks
(You can skip to =»file loading if you are familiar with this)
Networks consist of nodes (also called vertices or individuals) and connections between nodes, called edges (or links).

For example: You (a node) and I (also a node) are friends (edge). You have another friend (edge), let’s call him Barry (node). Maybe, if we learn about me and Barry, we can predict if Barry and I will be friends too! That will be the prediction that the next post will be about.
Loading data into a graph
The problem is that most machine learning assumes a rectangular structure, a ‘tidy’ structure: with one case per row and different metrics for that case in a column each:
id | measure 1 | measure 2 | outcome
123| 2 | 2 | 1
124| 3 | 2 | 0
But network data is graph data and graph data is usually not saved in that format.
Input data
There are many ways to store network data, but I’ve seen a lot of datasets where the data is split into a file with connections (edgelist) and a file with information about the nodes. In this case we start with
- an edgelist (connecting id to id; there are no headings in this file)
1, 611
2, 265
2, 182
- and a node information file (nothing more than name and id here; there are headings in this file)
id, name, new_id
402449106435352, Josh Marks, 386
368969274888, Blue Ribbon Restaurants, 473
765596333518863, Pat Neely, 1
We first have to assemble these two sources of information into a graph and than flatten it into edge-information only.1
Data source
The data is from a very successful clone of myspace, with a focus on seeing each other’s faces, lets call it SpaceBook. I downloaded the data from networkrepository.com and I do not know exactly how they got the data.2 I unzipped the folder into a folder called ‘data/’ on my computer.
Packages and loading data
library(readr) # for faster reading in (not necessary, but oh so nice)
library(dplyr) # lovely data manipulation
library(tidygraph) # for graph manipulation # this also loads igraph
library(ggraph) # for graph visualisation # this also loads ggplot2
Load the data:
# This assumes you saved your data in a folder 'data' relative to this script.
nodes <- readr::read_csv("data/fb-pages-food.nodes")
edges <- readr::read_csv("data/fb-pages-food.edges",col_names = c("from","to"))
Data cleaning
First some checks on the data.
range(nodes$new_id) # 0-619
range(edges$from) # 0-618
range(edges$to) # 15-619
nodes %>%
count(name, sort = TRUE) %>%
head(8)
# A tibble: 8 x 2
name n
<chr> <int>
1 McDonald's 59
2 KFC 27
3 Domino's Pizza 20
4 Nando's 15
5 Dunkin' Donuts 10
6 Jumia Food 10
7 foodpanda 8
8 Magnum 7
There are several problems with this data that I figured out over time.
- ids start with 0 and igraph cannot handle 0 as index, so we have to add 1 to all ids.
- ‘id’ in the nodes dataset is an ID that refers to a bigger data set so what we really want from this file is the ‘new_id.’
- the names are not unique, for instance there are 59 nodes with the name McDonald’s and 10 with the name Jumia Food. Let’s make the node names unique by concatenating the id to the name.
nodes_ <- nodes %>%
# rename and select in one go
select(id = new_id, name) %>%
mutate(
id = id +1,
name=paste0(name," (",id,")")
)
edges_ <- edges %>%
mutate(
from= from+1,
to=to+1
)
g <-
tidygraph::tbl_graph(
edges=edges_,
nodes = nodes_,
directed = FALSE,
node_key = "id" # tbl_graph chooses the first column in the nodes data.frame
# by default, so it should work, but let's be extremely clear here.
)
g
# A tbl_graph: 620 nodes and 2102 edges
#
# An undirected multigraph with 1 component
#
# Node Data: 620 x 2 (active)
id name
<dbl> <chr>
1 387 Josh Marks (387)
2 474 Blue Ribbon Restaurants (474)
3 2 Pat Neely (2)
4 543 La Griglia (543)
5 190 Jose Garces (190)
6 455 Zac Kara (455)
# … with 614 more rows
#
# Edge Data: 2,102 x 2
from to
<int> <int>
1 1 277
2 1 59
3 1 133
# … with 2,099 more rows
I’m using tidygraph to work with the data. {tidygraph} displays the graph structure as 2 tibbles (data.frames), as you can see; one for the edges, and one for the nodes. This allows for a workflow where you can trigger the edges data.frame or nodes data.frame. So you choose to work with one and manipulate that with the {dplyr} and {purrr} verbs.3
So if you are familiar with working with pipes and dplyr you can work with graphs too!
A quick peek into the graph for now
If we now look at the graph as it is, the result is … not super useful.
ggraph(g)+
geom_node_point(color = "lightblue")+
geom_edge_link(alpha = 1/3)+
labs(
subtitle = "Very often just plotting your data leads to a hairball plot",
caption="food network from facebook pages (blog.rmhogervorst.nl)"
)

Finding connections
When we have a rectangular dataset that does not contain time effects we can can randomly split the dataset into pieces, train on a bit, and test on another bit. But with networks that is problematic. Many properties of nodes in the network depend on the entire network. If we cut the network in pieces the metrics will change drastically. In reality, if we are working for a social network company we can take snapshots over time and predict the ‘future’ that we already know.

But in this case we only have this moment in time. So let’s pretend this is the end state and create a state in the past that was still connected but with less connections.
Positive examples
As positive examples we take edges that can be taken away without breaking the network into pieces.
I ‘simulate’ a network growing over time like this.
I created a custom function that goes edge by edge through all the edges in the edge file, removes one, checks if the network is still connected and continues, if breaking that connection breaks the network into two unconnected pieces we take the previous version of the network and continue.

If you run this interactively, I would advise to add the progress bar, by uncommenting selected lines.
find_possible_edges <- function(g, edges, seed=12445){
## for interactive use, uncomment progressbar lines.(one #)
#library(progress)
#pb <- progress_bar$new(total = nrow(edges))
## We gradually cut more edges in the graph, so it matters where your start
## but the loop goes from top to bottom, and therefore I randomize the order,
## a different seed will lead to slightly different results.
set.seed(seed)
idx <- sample(1:nrow(edges),size = nrow(edges),replace = FALSE)
edges <- edges[idx,]
## Preallocate result (because growing a vector is slower)
pos_examples_idx <- rep(FALSE, nrow(edges))
g_temp <- g
## Go through edges one by one
for (row in seq_len(nrow(edges))) {
#pb$tick()
## remove one edge from the graph
g_temp1 <- g_temp %>%
activate(edges) %>%
anti_join(edges[row,], by=c("from","to"))
## check if graph is still connected
verdict <- with_graph(g_temp1, graph_is_connected())
pos_examples_idx[row] <- verdict
## if positive, we continue with this graph in the next loop
if(verdict){g_temp <- g_temp1}
}
message(paste0("Found ",sum(pos_examples_idx), " possible links"))
## Return positive examples only
edges[pos_examples_idx,]
}
Run the function on the edges.
system.time(
# just to show you how slow this process is.
{pos_examples <- find_possible_edges(g, edges_)}
)
Found 1617 possible links
user system elapsed
14.652 0.503 16.922
Negative examples
We want our model to predict possible links between edges. So what are possible, reasonable edges? If you and me are friends and Barry is a friend of yours but not of me it is probable that Barry and me can become a friend. But it is less likely that a friend of Barry or a friend further away becomes friends with me. Not impossible but unlikely.
So what do I select as negative examples? What are possible candidate connections? I use nodes that are at distance 2 from each other.
In the (ugly) picture below, I count the number of steps from the pink node to other nodes. I select all nodes at distance 2 as negative examples. Distance 2 also excludes all direct connections (because they are at distance 1).
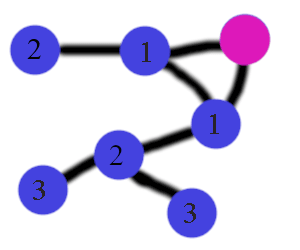
I think there are probably better ways to do this, maybe there are tidygraph verbs that I’m not utilizing here, but I’m falling back on {igraph} here. All tidygraph objects are also fully qualified igraph objects so all igraph methods work on tidygraph objects.
How do we find the distance of every node to every other node? We create a distance matrix.
dist_g <- igraph::distances(g)
For reasons I do not yet know this matrix has the names of the vertices and not the ids. The top corner of this matrix looks like this:
dist_g[1:3, 1:3]
Josh Marks (387) Blue Ribbon Restaurants (474) Pat Neely (2)
Josh Marks (387) 0 3 3
Blue Ribbon Restaurants (474) 3 0 2
Pat Neely (2) 3 2 0
I could create a function that finds for every name in the matrix the row and column name. But I’m going to cram the matrix into a data.frame and re-attach the node ids back from the nodes_ data.frame. Next I select only rows where the distance equals exactly 2.
distances <-
reshape2::melt(dist_g, value.name = "distance") %>%
left_join(nodes_, by=c("Var1"="name")) %>%
rename(to=id) %>%
left_join(nodes_, by=c("Var2"="name")) %>%
rename(from=id)
neg_examples <-
distances %>%
filter(distance ==2)
head(neg_examples, 4)
Var1 Var2 distance to from
1 Andy Luotto (485) Josh Marks (387) 2 485 387
2 Domino's Pizza (383) Josh Marks (387) 2 383 387
3 McDonald's (165) Josh Marks (387) 2 165 387
4 Alex Guarnaschelli (57) Josh Marks (387) 2 57 387
Combining the positive and negative examples
Combine the positive and negative examples into 1 data.frame and label the examples too.
# We should probably remove some duplicates here. because the graph is undirected a link between A-B and B-A is identical. and we can remove one of those.
trainingset <-
bind_rows(
pos_examples %>%
filter(from != to) %>%
mutate(target=1),
neg_examples[,c("from","to")] %>%
filter(from != to) %>%
mutate(target=0)
)
trainingset %>% count(target)
# A tibble: 2 x 2
target n
<dbl> <int>
1 0 34306
2 1 1606
This leads to many more negative than positive examples, something we have to take into account when we start to do some machine learning on this problem. Note though, that it is not super strange to get so many more negative than positive examples: there are many possible people around you with whom you can connect, but you only connect with a few of them.
Creating Features
I want to classify the potential edges into link or not a link and so we need features to do that. I’m going to retrieve information about every node in the network, features that tell us something about the position that a node takes into a network. To calculate node features, we shouldn’t calculate them on the graph where the positive examples are already connected. That leads to information leakage (where the test set data are used (directly or indirectly) during the training process). We would make overly optimistic estimations that would not generalize to new cases. And we want to predict for new cases!
So we should create features on the graph without the positive edges.
emptier_graph <- g %>%
activate(edges) %>%
anti_join(pos_examples, by = c("from", "to"))
# make sure we didn't do something stupid
stopifnot(with_graph(emptier_graph, graph_is_connected()))
#readr::write_rds(emptier_graph,file = "data/emptier_graph.Rds")
Create features for all the vertices
Calculate some features about every node in the graph.{Tidygraph} has many, many functions that can give us information about nodes. I’m selecting the node information here (and it pretends to be a data.frame so we can ‘just’ use dplyr verbs) and adding features to it.
My experience with networks, and my domain knowledge about this dataset are not super high. I’m taking some measures that, to me, seem to measure slightly different things about the nodes.
- degree: the number of direct connections
- betweenness: Something like: How many shortest paths go through this node
- pagerank: Something like: How many links pointed to me come from lot of pointed-to-nodes
- eigen centrality: something like the page rank but slightly different (
?igraph::eigen_centrality) - closeness: something like: how central is this node to the rest of the network (
?NetSwan::swan_closeness) - bridge score: the average decrease in cohesiveness if each of its edges were removed from the graph (
?influenceR::bridging) - coreness: K-core decomposition (
igraph::coreness)
node_features <-
emptier_graph %>%
activate(nodes) %>%
mutate(
degree= centrality_degree(normalized=FALSE),
betweenness = centrality_betweenness(cutoff = 5,normalized = TRUE),#
pg_rank = centrality_pagerank(),
eigen = centrality_eigen(),
closeness= centrality_closeness_generalised(0.5),
br_score= node_bridging_score(), # takes quite long,
coreness = node_coreness()
) %>%
as_tibble() %>%
select(-name)
head(node_features, 3)
# A tibble: 3 x 8
id degree betweenness pg_rank eigen closeness br_score coreness
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 387 2 11 0.00170 0.00000412 183. 0.000208 1
2 474 1 0 0.000819 0.173 236. 0.000255 1
3 2 1 0 0.000819 0.173 236. 0.000255 1
So now we have information about every node, let’s merge it back into the trainingset. Right now there will be columns for the left side of the edge and for the right side of the edge. More advanced feature combinations can be made later.
enriched_trainingset <-
trainingset %>%
left_join(node_features, by=c("from"="id")) %>%
left_join(node_features, by=c("to"="id"), suffix=c("","_to"))
#readr::write_rds(enriched_trainingset, file="data/enriched_trainingset.Rds")
Conclusion
So that is how I would create a ‘rectangular’ dataset, that can be used for machine learning, from graph data.
How would I use this in a production setting?
- First use an approach like this (take a subset of your graph and do these kinds of things) on your data and see if the features are good enough for prediction. (What is good enough? What are you doing now? How does that compare to current approach? Are these features even correlated with links?)
- Add checks on input data pipeline so you can be sure your data set over time remains good. (test your assumptions, like uniqueness of names, distance between nodes, etc)
- check performance in real world, how well do you predict real cases? Do you need to change some steps (probably yes).
- set up a pipeline where you ingest data, train model, validate, predict on new data, and where your predictions are picked up by the front of the website to recommend to actual users.
- than try to improve the process.
Reproducibility
At the moment of creation (when I knitted this document ) this was the state of my machine: **click here to expand**
sessioninfo::session_info()
─ Session info ────────────────────────────────────────────────────────────────────────────────────────────────────────
setting value
version R version 4.0.2 (2020-06-22)
os macOS Catalina 10.15.7
system x86_64, darwin17.0
ui RStudio
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Europe/Amsterdam
date 2020-11-25
─ Packages ────────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date lib source
assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.2)
blogdown 0.21 2020-10-11 [1] CRAN (R 4.0.2)
bookdown 0.21 2020-10-13 [1] CRAN (R 4.0.2)
cli 2.2.0 2020-11-20 [1] CRAN (R 4.0.2)
codetools 0.2-18 2020-11-04 [1] CRAN (R 4.0.2)
colorspace 2.0-0 2020-11-11 [1] CRAN (R 4.0.2)
crayon 1.3.4 2017-09-16 [1] CRAN (R 4.0.2)
digest 0.6.27 2020-10-24 [1] CRAN (R 4.0.2)
dplyr * 1.0.2 2020-08-18 [1] CRAN (R 4.0.2)
ellipsis 0.3.1 2020-05-15 [1] CRAN (R 4.0.2)
evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.1)
fansi 0.4.1 2020-01-08 [1] CRAN (R 4.0.2)
farver 2.0.3 2020-01-16 [1] CRAN (R 4.0.2)
fastmap 1.0.1 2019-10-08 [1] CRAN (R 4.0.2)
generics 0.1.0 2020-10-31 [1] CRAN (R 4.0.2)
ggforce 0.3.2 2020-06-23 [1] CRAN (R 4.0.2)
ggplot2 * 3.3.2 2020-06-19 [1] CRAN (R 4.0.2)
ggraph * 2.0.4 2020-11-16 [1] CRAN (R 4.0.2)
ggrepel 0.8.2 2020-03-08 [1] CRAN (R 4.0.2)
glue 1.4.2 2020-08-27 [1] CRAN (R 4.0.2)
graphlayouts 0.7.1 2020-10-26 [1] CRAN (R 4.0.2)
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.0.2)
gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.2)
hms 0.5.3 2020-01-08 [1] CRAN (R 4.0.2)
htmltools 0.5.0 2020-06-16 [1] CRAN (R 4.0.2)
httpuv 1.5.4 2020-06-06 [1] CRAN (R 4.0.2)
igraph * 1.2.6 2020-10-06 [1] CRAN (R 4.0.2)
influenceR 0.1.0 2015-09-03 [1] CRAN (R 4.0.2)
jsonlite 1.7.1 2020-09-07 [1] CRAN (R 4.0.2)
knitr 1.30 2020-09-22 [1] CRAN (R 4.0.2)
later 1.1.0.1 2020-06-05 [1] CRAN (R 4.0.2)
lifecycle 0.2.0 2020-03-06 [1] CRAN (R 4.0.2)
magrittr 2.0.1 2020-11-17 [1] CRAN (R 4.0.2)
MASS 7.3-53 2020-09-09 [1] CRAN (R 4.0.2)
mime 0.9 2020-02-04 [1] CRAN (R 4.0.2)
miniUI 0.1.1.1 2018-05-18 [1] CRAN (R 4.0.2)
munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.2)
netrankr 0.3.0 2020-09-09 [1] CRAN (R 4.0.2)
NetSwan * 0.1 2015-11-01 [1] CRAN (R 4.0.2)
pillar 1.4.7 2020-11-20 [1] CRAN (R 4.0.2)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.2)
plyr 1.8.6 2020-03-03 [1] CRAN (R 4.0.2)
polyclip 1.10-0 2019-03-14 [1] CRAN (R 4.0.2)
processx 3.4.4 2020-09-03 [1] CRAN (R 4.0.2)
promises 1.1.1 2020-06-09 [1] CRAN (R 4.0.2)
ps 1.4.0 2020-10-07 [1] CRAN (R 4.0.2)
purrr 0.3.4 2020-04-17 [1] CRAN (R 4.0.2)
R6 2.5.0 2020-10-28 [1] CRAN (R 4.0.2)
Rcpp 1.0.5 2020-07-06 [1] CRAN (R 4.0.2)
readr * 1.4.0 2020-10-05 [1] CRAN (R 4.0.2)
rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.0.2)
remedy 0.1.1 2020-11-21 [1] local
reshape2 1.4.4 2020-04-09 [1] CRAN (R 4.0.2)
rlang 0.4.8 2020-10-08 [1] CRAN (R 4.0.2)
rmarkdown 2.5 2020-10-21 [1] CRAN (R 4.0.2)
rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.0.2)
scales 1.1.1 2020-05-11 [1] CRAN (R 4.0.2)
servr 0.20 2020-10-19 [1] CRAN (R 4.0.2)
sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.2)
shiny * 1.5.0 2020-06-23 [1] CRAN (R 4.0.2)
stringi 1.5.3 2020-09-09 [1] CRAN (R 4.0.2)
stringr 1.4.0 2019-02-10 [1] CRAN (R 4.0.2)
tibble 3.0.4 2020-10-12 [1] CRAN (R 4.0.2)
tidygraph * 1.2.0 2020-05-12 [1] CRAN (R 4.0.2)
tidyr 1.1.2 2020-08-27 [1] CRAN (R 4.0.2)
tidyselect 1.1.0 2020-05-11 [1] CRAN (R 4.0.2)
tweenr 1.0.1 2018-12-14 [1] CRAN (R 4.0.2)
utf8 1.1.4 2018-05-24 [1] CRAN (R 4.0.2)
vctrs 0.3.5 2020-11-17 [1] CRAN (R 4.0.2)
viridis 0.5.1 2018-03-29 [1] CRAN (R 4.0.2)
viridisLite 0.3.0 2018-02-01 [1] CRAN (R 4.0.1)
withr 2.3.0 2020-09-22 [1] CRAN (R 4.0.2)
xfun 0.19 2020-10-30 [1] CRAN (R 4.0.2)
xtable 1.8-4 2019-04-21 [1] CRAN (R 4.0.2)
yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.2)
[1] /Library/Frameworks/R.framework/Versions/4.0/Resources/library
Notes
- I created the ugly ‘people connected together’ picture by using icons from undraw
- This post was inspired by a nice python post about networks from analyticsvidhya.com here, that post used the same data and positive and negative examples but threw a deeplearning method against it immedately..
- According to the data description: “Data collected about Facebook pages (November 2017). These datasets represent blue verified Facebook page networks of different categories. Nodes represent the pages and edges are mutual likes among them.” Ah, 2017, when I did not realize how awful the company facebook was. Blessed time…
References
Find more tutorials by me in this tutorial overview page
Find post by me on beginner level
Find an Rmarkdown only version on my github
-
Creative destruction, if you will ↩︎
-
They really want attribution for networkrepository.com so I’ll give them that, but there is no further information except for: scraped in 2015, no who, no criteria, so assume nothing about this data ↩︎
-
This is a nice result of the power of tidy-flavor-packages in the last 6 years, I wrote about it here ↩︎


Top comments (0)