caso não queira ler o artigo e queria ver diretamente o código, segue o repositório no Github
… afinal, vai que cola! Eu já havia dito que tentaria vender esta ideia como um padrão de projeto. Talvez você embarque nesta comigo, talvez você ria de mim ou talvez você aprecie meu esforço. Não importa muito, meu intuito aqui não é efetivamente disseminar um novo padrão, jamais teria tanta ambição (mas, novamente, vai que cola). A ideia é compartilhar uma linha de raciocínio e fomentar a troca de ideias; o que pode não funcionar tendo em vista que é provável que poucas pessoas efetivamente irão ler isto!
Padrões como strategy e chain of responsibility são ótimas ferramentas para solucionar problemas em um código orientado a objetos, principalmente quando adotamos uma abordagem de desenvolvimento pautada em composição de comportamento. Composição de comportamento, por sua vez, é uma ferramenta, sob o meu ponto de vista, essencial para construir aplicações modernas. Isto porque ela tem impactos profundos tanto a nível de design quanto de arquitetura: possibilita uma arquitetura evolutiva, que passa por mudanças graduais e permite que aplicações se adequem a novas necessidades e realidades. Seja como for, composição de comportamento está fora do escopo deste artigo e será abordada em momento oportuno.
É interessante avaliar como são padrões que se complementam, afinal de contas, a própria cadeia de execução pode ser vista como uma estratégia de execução. Em sua implementação mais simples, o strategy é bem direto: um conjunto de diferentes estratégias que recebem determinados parâmetros para sua execução.
A decisão da estratégia pode não ser tão trivial assim, o que não tem relação com o padrão em si. Me recordo agora de uma conversa onde foi-se afirmado que o strategy quebrava o princípio open closed. A discussão, na verdade, foi iniciada por uma outra pontuação, mas me chamou a atenção esta afirmativa. A idea por trás da mesma é que sempre que uma nova estratégia é adicionada, o código deve ser modificado para prever a criação e utilização desta estratégia, o que automaticamente violaria o princípio. Em uma rápida pesquisa pelo google, é fácil encontrar a definição: "Aberto para extensão significa que, ao receber um novo requerimento, é possível adicionar um novo comportamento. Fechado para modificação significa que, para introduzir um novo comportamento (extensão), não é necessário modificar o código existente."
Uma definição simples, correto? Antes fosse apenas simples; na verdade, ela é simplista. Não vou dar uma de professor Pasquale aqui, mas, na minha humilde opinião, simples é aquilo na medida, resolve a questão sem complexidade desnecessária, enquanto simplista ignora detalhes importantes do contexto. Aliás, questão delicada é chegar na solução simples! Seja como for, chamo esta definição de simplista numa pura análise sintática; sabemos que a intenção do autor pode não ser exatamente esta, mas dado que cada um interpreta de uma forma, uma contextualização melhor se mostra necessária. Exemplo disto é a conclusão da quebra levantada acima.
Fato é que, seguindo esta definição no PÉ DA LETRA, é inviável de se atingir o open closed em qualquer aplicação que seja. É improvável que a evolução de um software não leve a alterações em código existente, afinal de contas, é extremamente provável que construtos novos interajam com construtos antigos e, nesse sentido, algum ponto da cadeia de execução terá que ser modificado para interagir com o novo código.
Open closed não é sobre modificar linhas de código, mas sim sobre modificar comportamento pertinente. Adicionar uma mensagem de log ou incluir uma nova chamada a um objeto numa aplicação não é uma quebra do princípio, assim como adicionar uma nova condicional para seleção de uma nova estratégia também não o é. Alterar um algoritmo de buffer para também compactar uma informação ou trocar a seleção das estratégias de condicionais para reflexão é que configura uma quebra do princípio.
Voltando ao que interessa - sinto em lhe dizer que o discutido acima foi apenas uma ideia desconexa - o strategy é um padrão muito útil quando falamos em abstração. Porém, ao contrário do cenário pintado acima, nem sempre sua implementação é tão simples assim. Existem casos onde diferentes estratégias podem precisar de diferentes dados para sua execução. Pode-se argumentar que, se suas estratégias precisam de diferentes inputs, existe um problema de design no seu código. Não vou negar que esta é uma possibilidade e, de fato existem implementações que assim o são por falta de um design melhor, mas acredito que não necessariamente é o caso (ou ao menos assim espero). Por enquanto, vamos combinar que esta necessidade pode realmente surgir em casos reais e que isto não significa um design ruim.
A solução mais simples é a utilização de um mapa que será passado como parâmetro, certo? Não, claro que não! E aqui estava eu pensando que simples X simplista fosse um ponto apaziguado entre nós. A passagem de mapa é, na maioria dos casos, uma solução simplista; expõe dados e remove comportamento, uma receita ideal para um modelo anêmico que não acomoda mudança. Ainda assim, não julgo a prática que pode salvar muito trabalho e complexidade - resta rezar para que os ventos de mudança sejam poucos e agradáveis.
Há pouco tempo atrás me deparei com este problema e, dado que não me agradava em nada usar um mapa, me encontrei numa situação complexa. Comecei a pesquisar sobre o problema sem muito sucesso. Não vou dizer que me recordo exatamente do fruto desta pesquisa, mas lembro especificamente de uma proposta de solução baseada em uma espécie de abstração de parâmetros. Os detalhes da solução não vem ao caso aqui, mas você pode ler mais a respeito no seguinte link: Extending the Strategy Pattern for parametrized Algorithms
Não vou discutir a aplicabilidade da solução disposta na URL acima, certamente ela foi fruto de pesquisa (e muita dor de cabeça). É suficiente dizer que, para minha situação, ela não me pareceu adequada. Além disso, existem uma série de preocupações que fogem às necessidades da estratégia em si. Isso não é um problema, mas é algo que não era relevante para o meu caso.
Acredito que convém uma breve explicação do meu problema. Estava numa situação em que era necessário conectar dois contextos distintos (no caso eram dados de autenticação e autorização, mas o domínio do problema existe para qualquer contexto). Os contextos não eram específicos, portanto, a tradução pode ocorrer de qualquer contexto para qualquer contexto dentro de um domínio (neste caso, entenda contexto como OAuth, SAML, Basic Authentication, etc). Sendo assim, eu precisava traduzir informações sem saber, de antemão, qual era o contexto fonte e qual era o contexto alvo.
A pesquisa infrutífera me motivou a pensar numa possível forma de resolver esta situação. Depois de um processo de ideação, cheguei à solução que chamo de Polymorphic Data; mais detalhes sobre este processo podem ser verificados em Modelagem de um domínio OO: um estudo de caso sobre a criação de um modelo para um gateway de autenticação e autorização.
Não foi tão problemático pensar em como executar a transição em si; chain of responsibility se mostrou bastante adequado. O problema foi justamente em fornecer as informações para cada passo. A este ponto, acredito já estar claro que mapas e modelos anêmicos não se enquadram como uma solução na minha mente.
Na minha humilde opinião, o que governa a orientação a objetos é a abstração, o encapsulamento. Polymorphic Data é um meio de encapsular dados (e comportamentos) que, de forma contrária, estariam disponíveis para todas as partes que precisam interagir, ainda que cada parte precise apenas de uma pequena fatia do universo de dados.
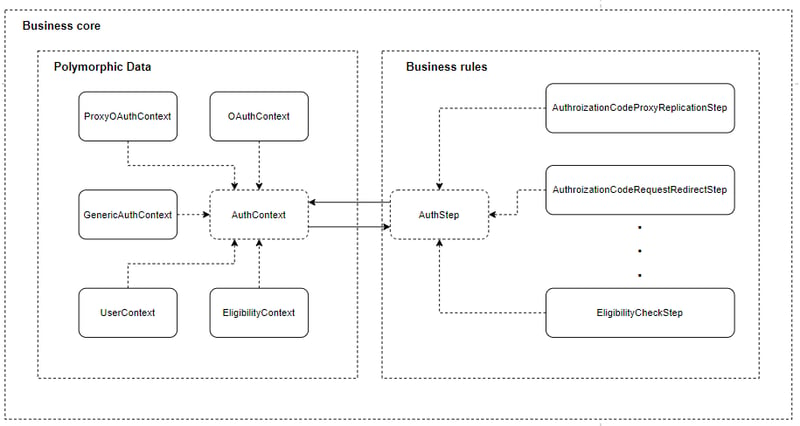
A idea central por trás do "padrão" é possibilitar que um universo maior de dados esteja presente num mesmo repositório, mas disponível somente em subconjuntos diretamente correlacionados. Aliás, o correto não é disponibilizar dados, mas disponibilizar informações de domínio relevantes. A alteração de uma informação em um contexto não pode impactar o contexto necessário para o próximo passo na cadeia de execução. Dessa forma, todos os passos recebem a mesma instância de um PolymorphicData e requisitam a transformação para o domínio adequado, tendo acesso unicamente aos comportamentos e informações estritamente necessários.
O resultado final é que, numa situação onde para se atingir um objetivo final, passos dinâmicos e diversos devem ser executados, se alcança uma forma de compartilhar um repositório de comportamentos e dados que se especializa segundo a necessidade, promovendo o encapsulamento e a alta coesão. De fato, PolymorphicData pode ser visto como um design que promove uma camada de anti-corruption.
Ao contrário da solução de parâmetros linkada acima, eu não disponibilizarei um artigo extensivo sobre a solução. Segue um repositório no Github contendo uma espécie de proof of concept do padrão. Recomendo ler o README.MD e também o Javadoc das classes.
É isso! :)





Top comments (0)