
I have been following a course on udemy on Machine Learning. Here is a quick explanation of how predict_proba() works and how it can be useful to us.
predict_proba() basically returns probabilities of a classification label
How does it work?
Official Documentation: The predicted class probabilities of an input sample are computed as the mean predicted class probabilities of the trees in the forest. The class probability of a single tree is the fraction of samples of the same class in a leaf.
Let's try and understand this with an example.
Our first 5 records of X_test are:
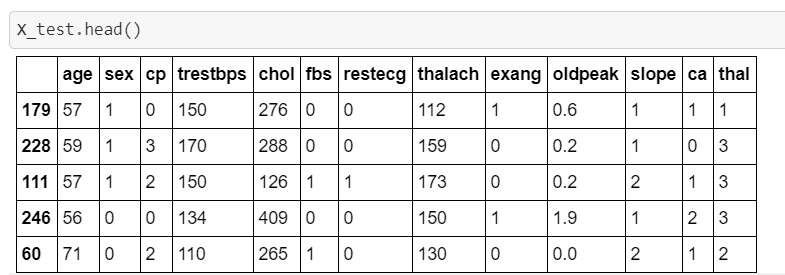
using predict_proba() on the same data...
clf.predict_proba(X_test[:5])
O/P 1:

On the same data predict() gives:
clf.predict(X_test[:5])
O/P 2:
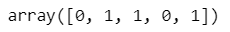
Observations from two outputs:
- In o/p 1 the sum of values in each row is 1 (0.89 + 0.11 = 1)
- In o/p2, when the prediction is of 0, the corresponding column in op/1 has higher value/probability.
- Observe that in 1st row value is higher when prediction is of 0 and vice
versa.
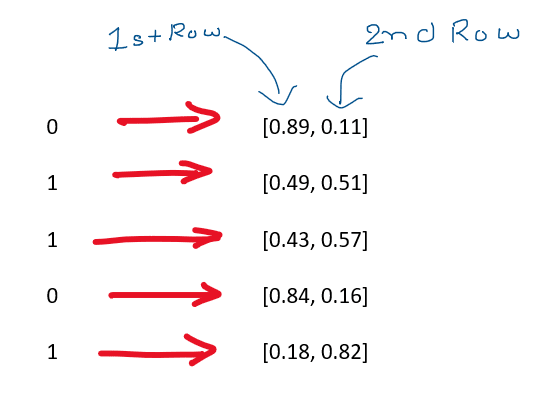
Conclusion:
Predict_proba() analyses the values of a row in our dataset and gives the probability of a result. So this can help us understand what factors determine the higher or lower probability of the result.

Top comments (1)
This is the cleanest and easiest to understand explanation of a piece of computer code I have ever seen. Thank you.