
Hi there 👋
Today, let's dive into 8 Language Models and Deep Learning repos that the top 1% of developers use (and those you have likely never heard of).
Ready?

How do we find the repos that the top 1% of devs use? 🔦
In this post, we rank developers based on their DevRank.
In simple terms, DevRank uses Google’s PageRank algorithm to measure how important a developer is in open source based on their contributions to open source repos.
To come up with this list, we looked at the repos that the top 1% have starred.
Then, we calculated the likelihood that the top 1% of developers will star a repo compared to the likelihood that the bottom 50% won’t. 👇
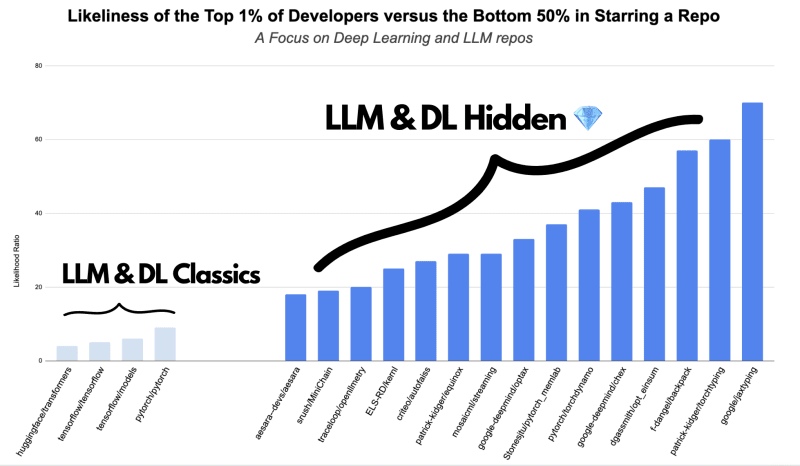
Lastly, after a little hand-picking, we find the below 8 repos.
These repos will be particularly useful when you’re training Machine Learning models.
However, if you’re more on the applied AI side we recommend you check out Creator Quests, an open-source challenge that rewards developers for creating cool GenerativeAI apps with ChatGPT, Claude, Gemini and more. 🙃 💰
The latest Creator Quest challenges you to build an education app using Generative AI. To participate, simply sign up to Quine and head to Quests.
jaxtyping
Type annotations and runtime checking

Why should you care? Type annotation and runtime checking are like a "smart assistants" who double-checks you're using the right data in the right way. This saves you time fixing errors and helps you learn faster and build reliable models.
With jaxtyping, you have type annotations and runtime shape checking for Tensors in JAX, PyTorch and TensorFlow. This means no more size assertions in your deep-learning code!
Set up: pip install jaxtyping
Here's an example of what to get started with:
from jaxtyping import Array, Float, PyTree
# Accepts floating-point 2D arrays with matching axes
def matrix_multiply(x: Float[Array, "dim1 dim2"],
y: Float[Array, "dim2 dim3"]
) -> Float[Array, "dim1 dim3"]:
...
def accepts_pytree_of_ints(x: PyTree[int]):
...
def accepts_pytree_of_arrays(x: PyTree[Float[Array, "batch c1 c2"]]):
...
https://github.com/google/jaxtyping
MiniChain
The core prompt chaining functionality in a tiny digestible library

Why should you care? Core prompt chaining allows you to build more complex and intelligent applications by sequentially connecting simpler prompts.
LangChain, Promptify, and LlamaIndex are popular libraries for prompt chaining but are, in turn, extremely large and complex. MiniChain aims to implement the core prompt chaining functionality in a tiny digestible library. The repo includes a built-in visualisation system using Gradio, which helps debug and understand the flow of prompt chains.
Set up: pip install minichain followed by export OPENAI_API_KEY="sk-***.
With MiniChain, functions are annotated as prompts.

Here's how to get started:
@prompt(OpenAI())
def color_prompt(model, input):
return model(f"Answer 'Yes' if this is a color, {input}. Answer:")
# to access the result, you need to call run()
if color_prompt("blue").run() == "Yes":
print("It's a color")
You can also chain prompts together. Find out more about it in the repo:
https://github.com/srush/MiniChain
streaming
Your data streaming repo when playing with neural network training

Why should you care? Data streaming enables the efficient handling of large datasets, ensuring your models learn from up-to-date information. It accelerates the training process and improves the accuracy of your applications, making them more robust and reliable.
Streaming enables streaming of large datasets from cloud storage for multi-node and distributed training.
Set up: pip install mosaicml-streaming
After prepping your data and uploading it to the cloud storage, you can build your StreamingDataset and DataLoader:
from torch.utils.data import DataLoader
from streaming import StreamingDataset
# Remote path where full dataset is persistently stored
remote = 's3://my-bucket/path-to-dataset'
# Local working dir where dataset is cached during operation
local = '/tmp/path-to-dataset'
# Create streaming dataset
dataset = StreamingDataset(local=local, remote=remote, shuffle=True)
# Let's see what is in sample #1337...
sample = dataset[1337]
img = sample['image']
cls = sample['class']
# Create PyTorch DataLoader
dataloader = DataLoader(dataset)
https://github.com/mosaicml/streaming
aesara
Aesara is a fast, hackable, meta-tensor library in Python

Why should you care? Defining, optimising, and evaluating mathematical expressions with multi-dimensional arrays enables you to handle complex data structures more effectively, leading to more powerful and efficient software solutions.
Aesara is library for performing symbolic manipulation, simplification and differentiation of tensor-valued variables. If you ever wanted to check your hand-written gradients, Aesara performs symbolic manipulation and can compile down to Numba, JAX and C.
Set up: pip install aesara
Here's how to get started:
import aesara
from aesara import tensor as at
# Declare two symbolic floating-point scalars
a = at.dscalar("a")
b = at.dscalar("b")
# Create a simple example expression
c = a + b
# Convert the expression into a callable object that takes `(a, b)`
# values as input and computes the value of `c`.
f_c = aesara.function([a, b], c)
assert f_c(1.5, 2.5) == 4.0
# Compute the gradient of the example expression with respect to `a`
dc = aesara.grad(c, a)
f_dc = aesara.function([a, b], dc)
assert f_dc(1.5, 2.5) == 1.0
# Compiling functions with `aesara.function` also optimizes
# expression graphs by removing unnecessary operations and
# replacing computations with more efficient ones.
v = at.vector("v")
M = at.matrix("M")
d = a/a + (M + a).dot(v)
aesara.dprint(d)
# Elemwise{add,no_inplace} [id A] ''
# |InplaceDimShuffle{x} [id B] ''
# | |Elemwise{true_divide,no_inplace} [id C] ''
# | |a [id D]
# | |a [id D]
# |dot [id E] ''
# |Elemwise{add,no_inplace} [id F] ''
# | |M [id G]
# | |InplaceDimShuffle{x,x} [id H] ''
# | |a [id D]
# |v [id I]
f_d = aesara.function([a, v, M], d)
# `a/a` -> `1` and the dot product is replaced with a BLAS function
# (i.e. CGemv)
aesara.dprint(f_d)
# Elemwise{Add}[(0, 1)] [id A] '' 5
# |TensorConstant{(1,) of 1.0} [id B]
# |CGemv{inplace} [id C] '' 4
# |AllocEmpty{dtype='float64'} [id D] '' 3
# | |Shape_i{0} [id E] '' 2
# | |M [id F]
# |TensorConstant{1.0} [id G]
# |Elemwise{add,no_inplace} [id H] '' 1
# | |M [id F]
# | |InplaceDimShuffle{x,x} [id I] '' 0
# | |a [id J]
# |v [id K]
# |TensorConstant{0.0} [id L]
https://github.com/aesara-devs/aesara
kernl
Speed up inference of language models on GPU

Why should you care? The inference of language models on GPUs helps speed up the processing of natural language tasks, allowing for real-time interactions and more intelligent applications. This knowledge opens the door to building advanced, responsive AI features that can understand and generate human-like text efficiently. With a single line of code, Kernl lets you run Pytorch transformer models several times faster on GPU.
Set up: pip install 'git+https://github.com/ELS-RD/kernl'
For local dev, after git clone: pip install -e .
Get started:
import torch
from transformers import AutoModel
from kernl.model_optimization import optimize_model
model = AutoModel.from_pretrained("model_name").eval().cuda()
optimize_model(model)
inputs = ...
with torch.inference_mode(), torch.cuda.amp.autocast():
outputs = model(**inputs)
https://github.com/ELS-RD/kernl
pytorch_memlab
Profiling and inspecting memory in PyTorch

Why should you care? Profiling and inspecting memory in PyTorch enables you to identify memory issues in your deep-learning models. This knowledge ensures your models run efficiently, saving time and resources. If you hit OOM errors during model training, you can profile and debug them using this tool.
Set up: pip install pytorch_memlab
To get started, I recommend you check out this simple demo here.
https://github.com/Stonesjtu/pytorch_memlab
openllmetry
Observability for your LLM application based on OpenTelemetry

Why should you care? Observability using OpenTelemetry provides deep insights into your application's performance and behaviour. It ensures you can identify and fix issues in a relatively quick timeframe.
OpenTelemetry is a framework for monitoring and analyzing LLMs through standardized data collection and processing. OpenLLMetry is built on OpenTelemetry and offers comprehensive observability tools designed for LLMs.
Set up: pip install traceloop-sdk
Get started:
from traceloop.sdk import Traceloop
Traceloop.init()
# You're now tracing your code with OpenLLMetry. If you're running this locally, you may want to disable batch sending, so you can see the traces immediately:
Traceloop.init(disable_batch=True)
https://github.com/traceloop/openllmetry
Autofaiss
Automatically create Faiss knn indices with the most optimal similarity search parameters

Why should you care? Optimizing similarity search parameters enables fast and accurate searches within large datasets. This knowledge helps build scalable, high-performance applications that handle tasks like recommendation systems and image retrieval.
This library allows an easy build of a FAISS nearest-neighbour index, with a great option to place the data on disk (”memory-mapped”) rather than in RAM.
Set up: pip install autofaiss
Example of in-memory numpy arrays:
from autofaiss import build_index
import numpy as np
embeddings = np.float32(np.random.rand(100, 512))
index, index_infos = build_index(embeddings, save_on_disk=False)
query = np.float32(np.random.rand(1, 512))
_, I = index.search(query, 1)
print(I)
https://github.com/criteo/autofaiss
I hope these discoveries are valuable to you and will help build a more robust LLM toolkit!⚒️
If you want to leverage these tools today to earn rewards, we have just launched a challenge to build an education app using Generative AI.
If that's of interest, log into Quine and discover Quests, your opportunity to code, build cool projects and bag some awesome rewards! 💰

Lastly, please consider supporting these projects by starring them. ⭐️
PS: We are not affiliated with them. We just think that great projects deserve great recognition.
See you next week,
Your Dev.to buddy 💚
Bap
If you want to join the self-proclaimed "coolest" server in open source 😝, you should join our discord server. We are here to help you on your journey in open source. 🫶






Top comments (25)
Cool list. There are a couple more repos on vector search and RAGs that I am starting to play with. I have listed em here:
dev.to/debadyuti/8-rusty-open-sour...
Let me know if you have tried any of them. :)
Really cool list man! Thanks for sharing that with me. Polars sounds cool 😏
Thank you for the awesome list!
Thanks for the comment! Happy you enjoyed it 🫶
Awesome projects list @fernandezbaptiste 🔥.
FAISS and Autofaiss are really awesome!
Thanks for the kind comment Saurabh - yes they are!
Got a cool repo or know a project that the community shouldn't miss? Drop them here, and let's geek out together. 👩💻
Ha ha yeah!! I think this one 👇 it uses NLP extensively
Resume Matcher is an open source, free tool to improve your resume. It works by using language models to compare and rank resumes with job descriptions.
Resume Matcher
𝙹𝚘𝚒𝚗 𝙳𝚒𝚜𝚌𝚘𝚛𝚍 ✦ 𝚆𝚎𝚋𝚜𝚒𝚝𝚎 ✦ 𝙳𝚎𝚖𝚘 ✦ 𝙷𝚘𝚠 𝚝𝚘 𝙸𝚗𝚜𝚝𝚊𝚕𝚕 ✦ 𝙲𝚘𝚗𝚝𝚛𝚒𝚋𝚞𝚝𝚎 ✦ 𝙳𝚘𝚗𝚊𝚝𝚎 ✦ 𝚃𝚠𝚒𝚝𝚝𝚎𝚛
Resume Matcher is an AI Based Free & Open Source Tool. To tailor your resume to a job description. Find the matching keywords, improve the readability and gain deep insights into your resume.
Upvote us on ProductHunt 🚀.
Don't let your resume be a roadblock from getting your next job. Use Resume Matcher!
How does it work?
The Resume Matcher takes your resume and job descriptions as input, parses them using Python, and mimics the functionalities of an ATS, providing you with insights and suggestions to make your resume ATS-friendly.
The process is as follows:
Parsing: The system uses Python to parse both your resume and the provided job description, just like an ATS would.
Keyword Extraction: The tool uses advanced machine learning algorithms to extract the most relevant…
Nice! Really cool repo, not looking for a job right now but will share it around with the network that could benefit from this 😉
Thats a very cool list of repos. Thanks for this!
Thanks a lot Harsh, appreciate your comment! Out of curiosity, did you know one of the repos? :)
thank
You're welcome! :)
I was checking out github.com/tinygrad/tinygrad recently, they seem to be super simple to get you started w deep learning.
Oh wow! It looks awesome and 20k+ stars, super impressive! Thanks for sharing 😄
This is a nice list and bookmarked it so I can come back to it.
Happy it helps 😄
A lot of good stuff!
Thanks! 🤩
Might save this for later 💎!
Happy this helps and thanks a lot for the comment, always very much appreciated 🙏
Wow that's awesome
Thanks a lot! 💃
Areon Network's Hackathon launch marks an exciting opportunity for visionaries to converge, innovate, and shape the future of decentralized finance, propelling the ecosystem towards boundless possibilities.
Top 1%!1!!! Thanks for your spam post!