
Hi there 👋
Today, let's dive into 7 ML repos that the top 1% of developers use (and those you have likely never heard of)!

What defines the top 1%?
Ranking developers is a difficult problem, and every methodology has its issues.
For example, if you rank developers by the number of lines of code they have written in Python you’ll probably get some pretty good Python developers at the top.
However, you may get people who have just copy-pasted lots of Python code to their repos and they aren’t that good. 🙁
At Quine, we have developed a methodology that we think is robust in most cases, but again not 100% perfect!
It’s called DevRank (you can read more about how we calculate this here).
The notion of the Top 1% that I use in this article is based on DevRank.
And yes, we continue working on this to make it better every day!
Btw, if you’re interested in finding out your DevRank, whether within the global community or in a specific language, you can check it out by signing up to quine and hovering on the top right icon as shown below.
How do we know which repos the top 1% use?
We look at the repos that the 99th percentile has starred.
We then compare the propensity of the top 1% of devs vs the bottom 50% of devs to star a repo, and automatically generate the list.
In other words, these repositories are the hidden gems used by the top 1% of developers, and yet to be discovered by the wider developer community. 🚀
CleverCSV
I handle your messy CSVs

A package developed by some friends of ours to handle common pain points of loading CSV files. A small but common problem at the start of many ML pipelines, solved well. 🔮
CleverCSV is able to detect and load various different CSV dialects, without needing to be told anything in its arguments. CSV files do not provide the necessary information to perform this natively, so some clever inference is required by the library.
CleverCSV can even handle messy CSV files, which have mistakes in their formatting.
In addition to the Python library, CleverCSV also includes a command line interface for code generation, exploration and standardization.
https://github.com/alan-turing-institute/CleverCSV
skll
Streamline ML workflows with scikit-learn through CLI

Are you writing endless boilerplate in sklearn to obtain cross-validated results with multiple algorithms? Try skll’s interface instead for a much cleaner coding experience. ⚡️
Skll is designed to enable running machine learning experiments with scikit-learn more efficiently, reducing the need for extensive coding.
The leading utility provided is called
run_experiment, and it runs a series of learners on datasets specified in a configuration file.It also offers a Python API for straightforward integration with existing code, including tools for format conversion and feature file operations.
https://github.com/EducationalTestingService/skll
BanditPAM
k-Medoids Clustering in Almost Linear-Time
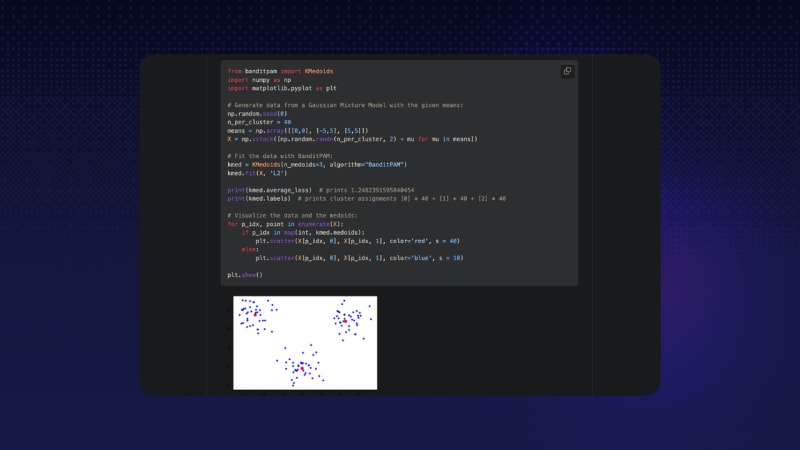
Back to fundamental algos here — BanditPAM is a new k-medoids (think a robust “k-means”) algorithm that can run in almost linear time. 🎉
Runs in O(nlogn) time rather than O(n^2) time, as per previous algorithms.
Cluster centers are data points, and hence correspond to meaningful observations. The center of a k-means cluster may correspond to invalid data; this is not possible with k-medoids.
Arbitrary distance metrics can be used (think L1, or Hamming distance for example), efficient k-means algos are typically limited to L2 distance.
Implemented from this paper, BanditPAM is ideal for data scientists looking for a powerful, scalable solution for group work, especially those dealing with large or complex data.
https://github.com/motiwari/BanditPAM
recordlinkage
The record matcher and duplicate detector everyone needs

Have you ever struggled to match users within different datasets who have spelt their name wrong, or who have slightly different attributes? Use this great library inspired by the Freely Extensible Biomedical Record Linkage (FEBRL), rebuilt for modern Python tooling. 🛠️
- Provides a python native implementation of the powerful FEBRL library, making use of numpy and pandas.
- Includes both supervised and unsupervised approaches.
- Includes tools for generating matching pairs to enable supervised ML approaches.
- RecordLinkage is ideal for data scientists looking for a flexible, Python-based solution to perform record linkage and data deduplication tasks.
https://github.com/J535D165/recordlinkage
dragnet
A sole focus on web page content extraction

Content extraction from webpages. Dragnet focuses on the content and user comments on a page, and ignores the rest. It's handy for our scraper-friends out there. 🕷️
Dragnet aims to extract keywords and phrases from web pages by removing unwanted content such as advertising or navigation equipment.
Provides simple Python functions (
extract_contentandextract_content_and_comments) with the option to include or exclude comments for extracting content from HTML strings.A
sklearn-styleextractor class is there for more advanced use, allowing customisation and training of extractors.
https://github.com/dragnet-org/dragnet
spacy-stanza
The latest StanfordNLP research models directly in spaCy

Interested in standard NLP tasks such as part-of-speech tagging, dependency parsing and named entity recognition?🤔
SpaCy-Stanza wraps the Stanza (formerly StanfordNLP) library to be used in spaCy pipelines.
The package includes named entity recognition capabilities for selected languages, extending its utility in natural language processing tasks.
It supports 68 languages, making it versatile for various linguistic applications.
The package allows your pipeline to be customised with additional spaCy components.
https://github.com/explosion/spacy-stanza
Littleballoffur
"Swiss Army knife for graph sampling tasks"

Have you ever worked with a dataset so large that you need to take a sample of it? For simple data, random sampling maintains distribution in a smaller sample. However, in complex networks, snowball sampling - where you select initial users and include their connections - better captures network structure. This helps avoid bias in analysis. 🔦
Now, do you have graph-structured data and need to work on samples of it (either for algorithmic or computational reasons)? 👩💻
Littleballoffur offers a range of methods for sampling from graphs and networks, including node-, edge-, and exploration-sampling.
Designed with a unified application public interface, making it easy for users to apply complex sampling algorithms without deep technical know-how.
https://github.com/benedekrozemberczki/littleballoffur
I hope these discoveries are valuable to you and will help build a more robust ML toolkit! ⚒️
If you are interested in leveraging these tools to create impactful projects in open source, you should first find out what your current DevRank is on Quine and see how it evolves in the coming months!
Lastly, please consider supporting these projects by starring them. ⭐️
PS: We are not affiliated with them. We just think that great projects deserve great recognition.

See you next week,
Your Dev.to buddy 💚
Bap
If you want to join the self-proclaimed "coolest" server in open source 😝, you should join our discord server. We are here to help you on your journey in open source. 🫶






Top comments (16)
Wow. I love that I didn't know about any of these tools before, and that each of them is worth a GitHub star.
I adore that none of the links were: [ pandas, polars, pytorch, keras, numpym spacy]
Great job on novel content!
So trueee! Great job @fernandezbaptiste ⭐️
Thanks a lot szymonkrupa - super appreciated! ⭐️
Appreciate this comment a lot Dave 🙏
Let me know how you get along with some of these tools :)
Just clicked through to find out about Quine too. Gonna try and rattle these around with the content.ai challenge you have and see if anything comes out!
ouhhh very nice! 👌
I have been working as a DS for last 5 years yet knew 3/7.Thank you for digging these gems.
What I would have done to make the article 110% is sharing code teaser snippets to demonstrate the usage.
Nevertheless, the absence of code snippets does not take away the brilliant packages 📦 mining 👌🏾
Hey Prayson, I'm so glad this brought some value 🙏
That's a good point, maybe I'll do this in my next article. 🙂
Thanks for sharing! I haven't used Python in a while, but seeing all this cool libraries just makes me want sit down and try them all :)
Glad you enjoyed the article! You should get back to it, Python is life 🐍😉
Nice data, I really enjoyed this.
Thanks a lot Nathan!
Love this! Love the sleuthing and it's so interesting to find new repos to look into.
Happy you like this :D
This is pure gold!! So cool 🤩!!
Thanks a lot for the kind comment Gerda! 🙏