
Back in the early days of software development, having multiple developers working on the same application was a tough challenge. That’s why VCS (Version Control System) like Git was created and methodology like Feature Branching was introduced.
1 feature = 1 branch
The basic idea of working per git branch (also known as Feature Branching) is that when you start to work on a feature, you take a branch of your repository (e.g: git) to work on that feature.

The advantage of feature branching is that each developer can work on their own feature and be isolated from changes going on elsewhere. This concept has been initiated for stateless application. However, most applications rely on databases (also known as “stateful application”).
The question is: How to use the concept of Feature Branch with a stateful application?
Let’s take a concrete example:
We have a NodeJS application that connects to a PostgreSQL database, for which we have 3 distinct branches: master, staging and feature_1.
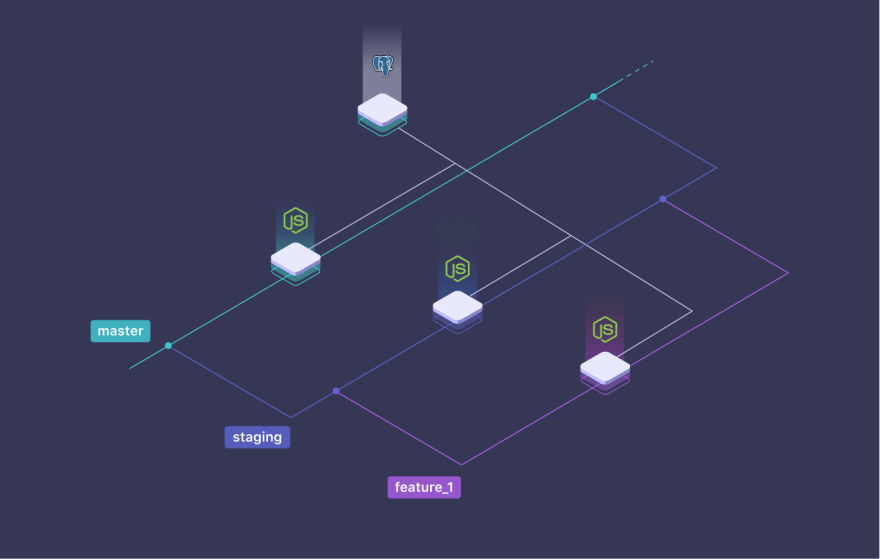
No matter which branch we are working on, we are always connected to the same database. If our application writes, modifies or deletes data in the database, while we are on the "feature_1" branch, all branches will also be impacted by these changes. Meaning, we violate the main Feature Branch principle - isolation. There is nothing more stressful than having to keep in mind that we can lose data and break everything at any time.
so -
How to be compliant to the feature branch principle (isolation) with a database?
One possible solution is to have one copy of the database per branch. Each database can be modified without the risk of modifying the others.
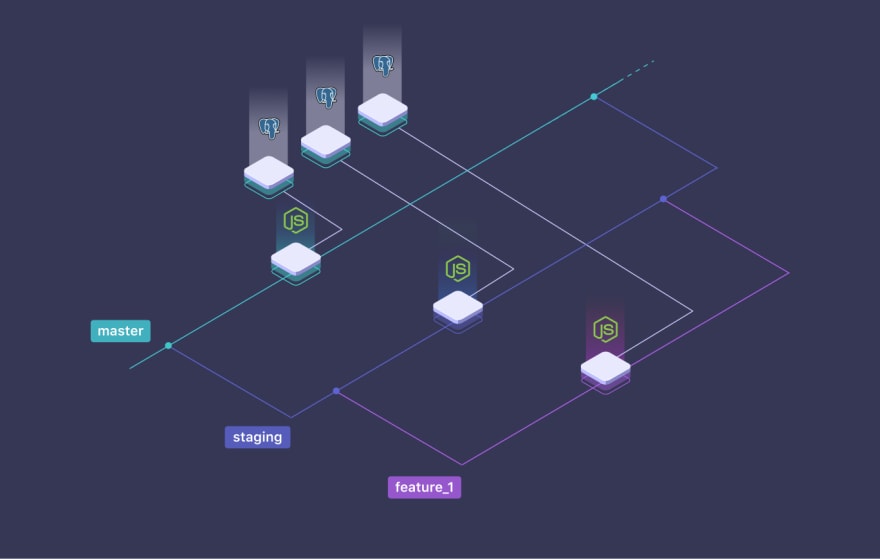
How to have one database per branch?
3 main choices are possible (manual, partially automated and fully automated) with all their advantages and disadvantages.
Manual
Manual means that you need to install all your required services (DNS, databases, VPC...) manually. This approach is fast enough to bootstrap, but it is hard to maintain over time.
Advantages
- Fast to bootstrap
Disadvantages
- You need to configure system and network services (DNS, network, security...)
- You need to manually create the databases according to the number of branches
- You need to manually synchronize the data between the databases
- You need to setup observability, monitoring and alerting
- Hard to maintain over time
- Error prone
Partially automated
Partially automated means that you will spend time to set up a complete system that is provisioning your required services for your project. This type of architecture required times and effort from experienced DevOps. It's a good choice for large corporations that can support the cost, but most of the time a really bad for smaller one.
Advantages
- Automatic system and network configuration + database provisioning with tools like Terraform (Infrastructure as Code)
- Automatic data synchronization between databases (with a custom script)
- Perfectly fit your need
Disadvantages
- You need to manually create the databases according to the number of branches
- Required months to fully set up
- Expensive maintenance over time (experienced DevOps engineer required)
- You need to setup observability, monitoring and alerting
Fully automated (with Qovery)
Fully automated means that all the required resources by the developer will be deployed no matter his needs. With Qovery, all resources are automatically provided and the developer don't even have to change their habits to deploy their application. Feature Branching is supported out of the box.
Qovery gives to any developer the power to clone an application and a database without having to change their habits
Let's take the example of our 3 branches with a NodeJS application and a PostgreSQL database

Here is the commands necessary to have a fully isolated application and database on each branch
$ pwd
~/my-nodejs-project
# Github, Bitbucket, Gitlab seamless authentication
$ qovery auth
Opening your browser, waiting for your authentication...
Authentication successful!
# Wizard to generate .qovery.yml
$ qovery init
$ git add .qovery.yml
$ git commit -m "add .qovery.yml file"
# Deploy master environment
$ git push -u origin master
# Show master environment information
$ qovery status
# Create branch staging
$ git checkout -b staging
# Deploy staging environment!
$ git push -u origin staging
# Show staging environment information
$ qovery status
# Create branch feature_1
$ git checkout -b feature_1
# Deploy feature_1 environment!
$ git push -u origin feature_1
# Show feature_1 environment information
$ qovery status
Advantages
- Accessible to any developer
- No set up time
- Programming language agnostic
- Integrated to git (no other dependencies required)
- Compliant to Feature Branching concept
Disadvantages
- Know how to create a Dockerfile
- Deployment only available on AWS, GCP and Azure
- Only integrated to Github, Gitlab and Bitbucket
Conclusion
In this article, we have seen that the purpose of the Feature Branch is to be able to develop a feature without being impacted by changes that can be made to other branches.
However, the Feature Branch concept is difficult to apply when our application needs to access a database. Because each application (coming from several branches) access to the same database. This is contrary to the Feature Branch isolation principle and brings serious data safety problems.
Qovery allows application and database to be seamlessly duplicated from one branch to another. And thus to respect the isolation principles of the Feature Branch.
Useful links: Feature Branching and Continuous Integration from Martin Fowler - Stateless vs Stateful from StackOverflow

Top comments (0)