
Common wisdom says that K/V stores are a bad fit for time series (TS) data. Reasons are lots of writes and a large data volume implied by time series. But the common wisdom maybe sometimes wrong. Today we will discuss an approach for building a (relatively) efficient TS storage on top of RocksDB, an embedded key/value (K/V) store from Facebook. RocksDB is a perfect fit for our needs, as it’s production-ready, well-maintained, and provides solid write speed thanks to the LSM tree data structure. A TS storage built with the approach should be capable of showing good read/write throughput, as well as a decent data compression ratio.
Disclaimer. Before we go any further, I need to say that in situations when you can use an existing TS database, you certainly should go for it. But sometimes you might need an embedded TS storage and then the list of options is almost empty.
This blog post is a short, napkin writing style summary of the approach, which is described with a greater amount of detail in this talk I gave some time ago. While that talk was focused on the needs of Hazelcast Management Center and included some code snippets in Java, I’m going to keep this post as short and language-agnostic as possible.
My ultimate goal is to shed enough light on the idea so that any developer can build an embedded TS storage on top of RocksDB (or any other K/V store) in any popular programming language.
Let’s start with the terms and assumptions necessary for further explanation. For the sake of readability, I’m going to use TypeScript for the code snippets.
Terminology
“Metric” — a numerical value that can be measured at a particular time and has real-world meaning. Examples: CPU load, used heap memory. Uniquely characterized by a name and set of tags.
“Data point” (aka “sample”) — a metric value measured at the given time. Characterized by a metric, timestamp (Unix time), and value.
“Time series” — a series of data points that belong to the same metric and have monotonically increasing timestamps.
A data point could be described by the following interface.
Here is how a real-world data point can look like.

The storage itself can be expressed with the following interface.
As you may see, the public API is very simple and provides methods for storing a list of data points and querying a single time series (i.e. a single metric). That is why the term “storage” is used here: it’s not a TS database, as it lacks query language and execution engine powered by indexes for metric metadata, aggregation API, as well as some other modules. On the other hand, many of those features can be built on top of the storage, but that goes beyond our today’s topic.
Assumptions
All TS databases and storages make assumptions for the shape of the time series data and so do we.
Firstly, we assume that timestamps have one-second granularity, i.e. each timestamp corresponds to a start of a second. As we will see later, this assumption opens up opportunities for bitmap-based data compression.
Secondly, data point values have to be integer numbers. This assumption also allows us to use certain compression techniques, but this one is not a must-have and it’s possible to support float numbers by using a different compression algorithm.
Now, when we have a better understanding of our needs, let’s discuss K/V data layout.
Key-value layout
The main idea here is very natural for time series and may be found in most (if not all) TS DBs. In order to reduce the number of K/V entries and enable ways to compress data, we store time series in minute buckets. The choice of a minute as the time interval is a compromise between durability (smaller interval, more frequent on-disk persistence) and overall storage efficiency (more data points in a bucket, better compression and read/write throughput).
As the second step, we also extract metrics into a separate K/V store (RocksDB calls them “databases”) with assigned integer identifiers. This way each data point record in the main store contains identifiers instead of lengthy metric descriptions.

The layout of the main K/V store which holds minute buckets looks like the following.
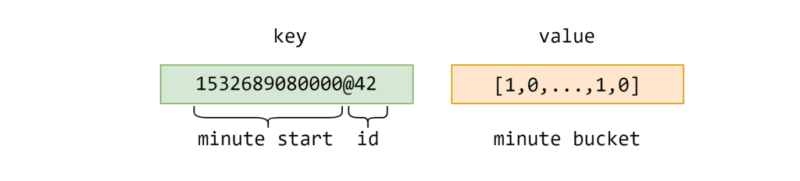
Here the value holds a byte buffer (a blob) with the compressed minute bucket data.
As you might have guessed already, the next topic is data compression.
Data point compression
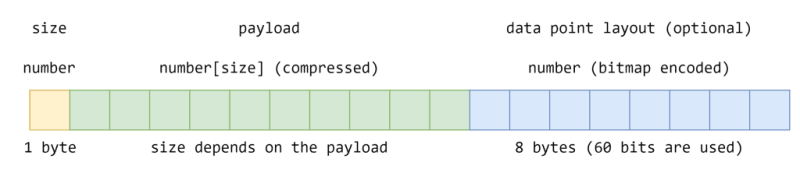
In our design, each minute bucket may hold up to 60 data points. In reality, some of them may be missing or the data collection interval may be bigger than one second. The most straightforward approach is to store the whole bucket in a number array of 60 elements and, maybe, compress it with one or another algorithm. But we should try to avoid storing “holes”, so we need something smarter.
As we already store timestamps of minute starts in keys, for each data point we only need to store the offset of the corresponding minute start. And here comes bitmap encoding, the first compression technique we shall use. We only need 64 bits to encode all offsets. Let’s call this part of the blob “data point layout”.
As for the values (the “payload”), we can put them in an array and compress it with a simple algorithm that combines delta encoding and run-length encoding. We are going to leave all details of the exact algorithm out of scope, but if you want to learn more, this blog post would be a good starting point.
This picture illustrates the layout of each minute bucket.
It is time to discuss how these building blocks work together as a whole.
TS storage design
Let’s look at how the implementation may look like from the high-level design perspective.
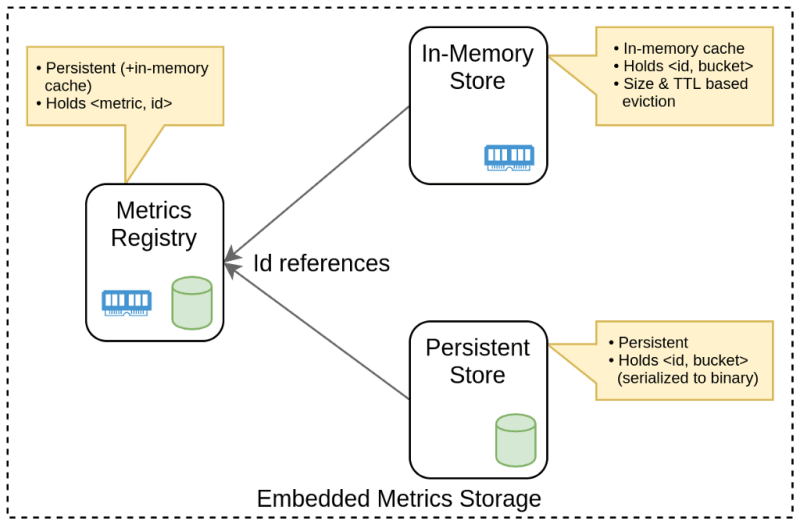
Here Metrics Registry stands for the K/V store containing metric-to-identifier pair, Persistent Store holds minute buckets, and In-Memory Store serves as a write-behind cache.
Each write goes through the following flow.
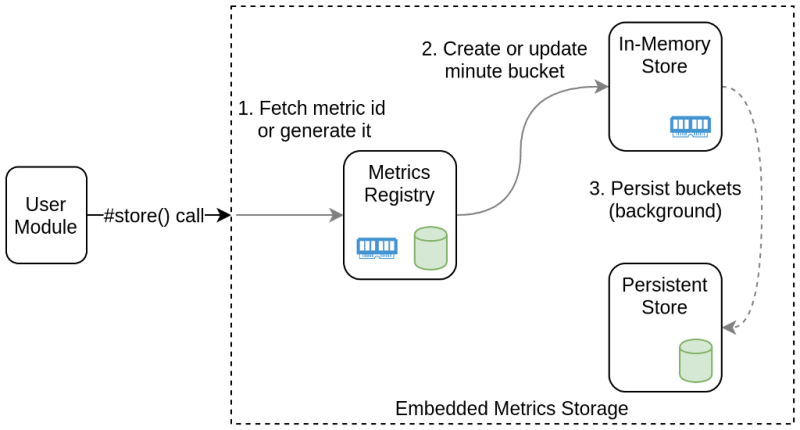
On each store() call data points are accumulated in minute buckets stored in the cache, while on-disk persistence happens periodically in a background job. Each run of the job iterates over all cached buckets and persists those which were accumulated for at least one minute. As the last piece of the puzzle, the compression should be applied before persisting buckets.
This way we group data points into buckets and benefit from both data compression and batch writing.
As shown below, the read flow time series is a way simpler.

When reading data points, we first check Metrics Registry to find the identifier (hint: an in-memory cache will certainly speed up this step). Then we check In-Memory Store trying to find the bucket and only then we read it from the disk (from RocksDB, to be more precise). This way we make sure that queries for recent data points will be fast, which is valuable for many use cases, like showing the latest data in UI.
That is basically the whole approach. Congrats on your new knowledge!
While the theory is valuable, no doubt, some of you might want to know the characteristics of a concrete implementation of the TS storage.
Potential characteristics
Some time ago we have developed an embedded TS storage for Management Center, which is a cluster management & monitoring application for Hazelcast IMDG. The storage was written in Java on top of RocksDB and followed the described design.
Along with other types of testing, we benchmarked the storage in order to understand its performance characteristics. The benchmark was emulating 10 cluster nodes reporting 120K metrics every 3 seconds. Random integer numbers from the 0–1,000 range were used as data point values. As the result, on a decent HW with SATA III connected SSD the storage showed a throughput of 400K data point writes per second and 19K minute series (physical) reads per second. These numbers can be called good enough, at least for our needs.
As for the compression efficiency, on average the storage spends around 5.25 bytes per data point. Raw data point data takes 16 bytes, so the compression ratio is around x3. This result is worse than what standalone TS DBs usually show, but it is not terrible and may be sufficient for many use cases, especially when considering how simple the storage is.
Summary
I’m intentionally leaving additional challenges, like potential enhancements and technical restrictions, out of the scope of this blog post, but you may find them mentioned in the talk. Also, the design is not carved in the stone and leaves a lot of room for variations.
My main intent is to show that a simple, yet good enough TS storage can be easily built on top of RocksDB or any other suitable K/V store. So, if you plan to write one, then I wish you good luck and fun coding!




Top comments (0)