
The central idea behind microservices is that some types of applications become easier to build and maintain when they are broken down into smaller, composable pieces which work together. Each component is continuously developed and separately maintained, and the application is then simply the sum of its constituent components. This is in contrast to a traditional, monolithic application which is developed all in one piece.
Applications built as a set of modular components are easier to understand, easier to test, and most importantly easier to maintain over the life of the application. It enables organizations to achieve much higher agility and be able to vastly improve the time it takes to get working improvements to production. This approach has proven to be superior, especially for large enterprise applications which are developed by teams of geographically and culturally diverse developers.
There are some other benefits as well for a microservice architecture, which include:
- Developer independence: Small teams work in parallel and can iterate faster than large teams.
- Isolation and resilience: If a component dies, you spin up another while and the rest of the application continues to function.
- Scalability: Smaller components take up fewer resources and can be scaled to meet increasing demand of that component only.
- Lifecycle automation: Individual components are easier to fit into continuous delivery pipelines and complex deployment scenarios not possible with monoliths.
But how did we reach here? Believe it or not, but we've come a long way in the past decade to design microservices the way that we do today. To understand why things are done the way they are in the microservice land, I believe it is important to understand the process of evolution of the microservice architecture.
Origins
Traditional application design is often called monolithic because the whole thing is developed in one piece. Even if the logic of the application is modular, it is deployed as one group, like for example a Go application, which, when built, gives us an executable file. We can imagine this as if all of notes of different subjects of a college student were compiled into one long stream.
This type of code writing and deploying is convenient because it all happens in one spot, but it incurs significant technical debt over time. That’s because successful applications have a tendency of getting bigger and more complex as the product grows, and that makes it harder and harder to run.
As these systems had a tight coupling process, any changes made to the code could potentially endanger the performance of the entire application. The functionalities were too interdependent for a new technological age that demanded constant innovations and adaptation.
Another issue with monolithic architecture was its inability to scale individual functionalities. One crucial aspect of successful businesses is their ability to keep up with consumer demands. Naturally, these demands depend on various factors and fluctuate over time.
At some point, the product will need to scale only a certain function of its service to respond to a growing number of requests. With monolithic apps, you weren’t able to scale individual elements but rather had to scale the application as a whole.
Enter microservices. However, the idea of separating applications into smaller parts is not new. There are other programming paradigms which address this same concept, such as Service Oriented Architecture (SOA). However, recent technology advances coupled with an increasing expectation of integrated digital experiences have given rise to a new breed of development tools and techniques used to meet the needs of modern business applications.
But this initial microservice / SOA architecture, which just simply took monoliths and broke them up into smaller units, had some problems of it's own. After being broken down to smaller units, these microservices needed to communicate among themselves to function. The first natural choice to facilitate this communication was, and in many cases, still remains, REST APIs.

This worked to a point. But then, synchronous request-response communication led to tight point-to-point coupling. This brought us all the way back to where we were. It became so tightly coupled that this problem was coined a term called as distributed monoliths. So basically you have microservices for the namesake, but you still have all the problems of monoliths like having to co-ordinate with teams, dealing with big fat releases, and a lot of the fragility that comes along. Some of the problems of such a distributed monolith architecture are:
Clients knowing a bit too much
Initially, the clients — which could be a mobile app, a web app, or any client of that sort — used to get a big fat documentation containing information about the APIs to be integrated. This resulted in the client knowing a bit too much than what they were supposed to. This essentially resulted in a bottle-neck when it came to making changes to the microservices. Adding a new microservice now meant changes to be introduced to the client as well. Making changes to existing microservices also forced changes to be made in the client.

Unavoidable redundancies
When breaking monoliths into smaller units, It becomes tricky to decide who will be responsible for what function of the system. If the system's architecture fails to address these issues properly, it would often result in some unavoidable redundancies. For example, If a microservice sends a request to another microservice and it fails to respond, suddenly the questions like what happens then becomes of paramount importance. This meant that the microservice from where the request originated, had to now take responsibility of being able to do something intelligent. This applied to every other microservice in the system, and even before we knew it, it became a viscous cycle. In order to handle such cases, every team ended up solving a lot of common problems. Such problems of shared infrastructure once again lead to the same issues which we were facing in monoliths.

Making changes is risky
As a microservice may not always know about the other microservices that communicate with it since they only communicate with each other using RESTful APIs, it may become hard to determine which microservices may end up breaking if introduce some changes to our microservice. Even with good API contracts such as OpenAPI, it is not an easy job. A lot of validation is required for all the microservices that are involved.
Evolution
Now that we've seen the challenges that we initially faced with microservice, or rather the distributed monoliths pattern that we used the first few years since the introduction of microservice as an architectural pattern, we can now have a better understanding of the problems that we aimed at solving, one-by-one, thereby evolving the microservice architecture in general.
API Gateways
Clients know a bit too much? Microservices end up having unavoidable redundancies in order to address common problems? Enter API Gateways. As simple as it sounds, but the introduction of a simple API gateway, really does end up solving a lot of problems. For starters, it frees all microservices from having to worry about authentication, encryption, routing etc. The client does not have to worry about changes that happen in the microservice land as it only communicates with the API gateway. This hugely simplifies things at the client as well as at the server side of things.

Responsibilities of an API gateway:
- Authentication: Microservices don't have to worry about the overhead of authenticating the request again and again as the API Gateway will only let through authenticated requests
- Routing: Since the client only knows about the API Gateway, it doesn't need to know about IPs or domains of all the microservices involved in the system. This also enables microservices to change freely as they don't have to worry about letting the client know about the internal changes as they are virtually transparent to the client
- Rate limiting: One of the important advantages of having an API gateway is it's ability to rate-limit incoming requests. This hugely helps in spam prevention and also avoiding DOS attacks.
- Logging and analytics: Since all the requests go through a single entity, important analytics, such as, who is accessing, what is being accessed, which is the most used endpoint, etc. can be easily obtained and a lot of meaningful insights can be derived from it
But wait a minute. Let us take a step back and analyse. Doesn't such a pattern resemble to one of the most basic problems that any good architecture aims to solve? No points for guessing the right answer: Single Point of Failures (SPOF). This API gateway now suddenly becomes a big bottleneck. It becomes a big engineering dependency.
Service mesh
Service mesh has been around from more than a couple of years now. In simple terms, a service mesh can be imagined as a distributed internal API gateway. An API gateway basically handles what we call as the North-South traffic. North-south traffic is basically the traffic that flows from host to servers. It is like the traffic that flows from top-down, or vertically. In order to remove the SPOF introduced due to a single API gateway, we want to take this north-south traffic and apply it as the east-west traffic within our cluster. Similar to north-south, east-west traffic is the traffic that flows within the servers. This can be imagined as the traffic that flows horizontally within the individual microservices.
Service mesh uses what we call as the sidecar pattern in architecture. The sidecar pattern is a single-node pattern made up of two containers. The first is the application container. It contains the core logic for the application. Without this container, the application would not exist. In addition to the application container, there is a sidecar container. The role of the sidecar is to augment and improve the application container, often without the application container’s knowledge. In its simplest form, a sidecar container can be used to add functionality to a container that might otherwise be difficult to improve.
This sidecar is usually language-agnostic. There could be sidecars for collecting logs, side-cars for monitoring, etc. To address the centralized problem caused by using a single API gateway, we can use sidecars as proxies attached to services. These proxies can have appropriate intelligence to carry out the function of routing to other microservices. It can also have service discovery. So in case if any microservice's IP changes, it automatically knows about it. Other features such as rate limiting can also be possible because of side-cars. For example, retries can be dropped so that the other services doesn't face a DOS attack and prevent it from drowning in case of unfortunate blips.

Event driven
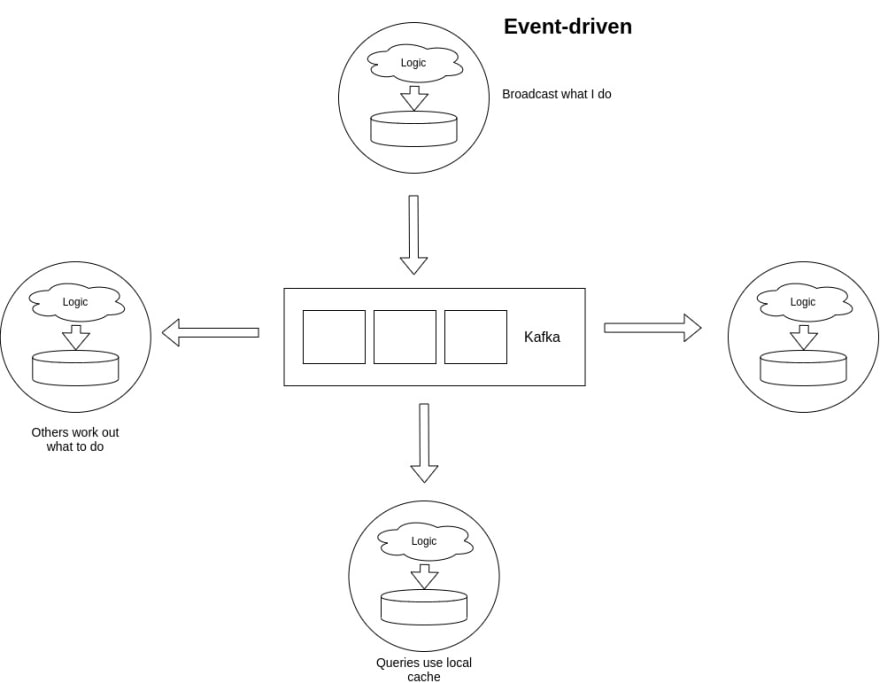
To solve many of the issues which stemmed from use of RESTful APIs to communicate within microservices, we take the request-response architecture and split it in an event-driven architecture. In a request-driven architecture, microservices either tell others what to do (commands) or ask specific questions to get things done (queries), using RESTful APIs. In an event-driven architecture, microservices broadcast all events to every other microservice. You can think of events as not just facts but also triggers.
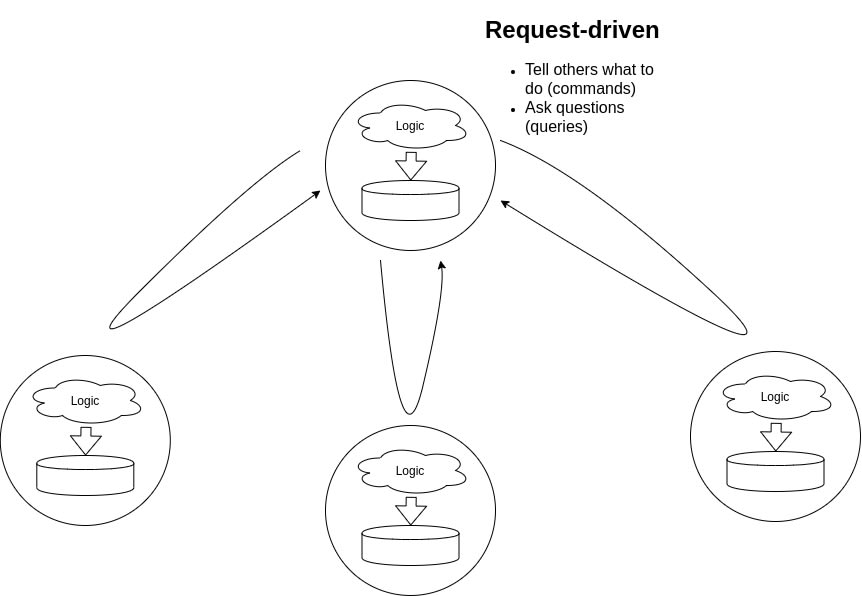
To understand the difference between both types, let us consider an example. Suppose you want to buy an item online, we can say that we have microservices that handle orders, shipping and customers. If a customer places an order, a request is made to the order service. This order service places the order, and co-ordinates with the shipping service to provision shipping of the product. The shipping service, in turn, communicates with the customer service to fetch customer details. These customer details when returned by the customer service, may contain address details of the customer to where the shipping of the item will be triggered.

However, there are some challenges that need to be solved with such an architectural pattern. What if the shipping service suddenly goes down? How long should the order service keep retrying for? Questions like these, and more, can be solved using the event-driven pattern.
In the case of event-driven architectures, when an order is received, the corresponding event, also called as fact, is written to this huge log of events. Other services, read all these events that are being written to the log, and then act on the events that are relevant to them. This happens in case of all the microservices. For example, if customer changes his address, the customer services publishes this fact in the event log. The shipping service, sensing a change in address, carries out the necessary actions.

Since the events are persisted in the log, in case if any service goes down, all that it needs to do is to read events from this stream whenever it comes back up, in order to catch up with the missed events.
It is important to note that all these events are stateful. Every microservice maintains a DB of it's own. This DB may not be a full-blown DB. It can even be something as simple as a key-value store. These DB may or may not contain redundant data. But the bottom line is that every DB will contain information that is relevant to that microservice. These DBs can also act as local caches to further reduce latency and thereby increase performance.
Serverless
Serverless is an architectural pattern where the cloud provider is responsible for executing a piece of code by dynamically allocating the resources. This eventually results in lesser number of resources used to run the code. The code is typically run inside stateless containers that can be triggered by a variety of events including HTTP requests, database events, queuing services, etc. The code that is sent to the cloud provider for execution is usually in the form of a function. Hence, serverless is also referred as Function-as-a-service (FaaS) as opposed to the traditional Backed-as-a-Service (BaaS) pattern. Since everything happens on-demand, these containers are ephemeral. They are dynamically spun up on receiving an event, and also conveniently destroyed after having served it's purpose. This hugely helps in scaling

However, there's a catch. One essential thing is missing from this pattern. States! In the case of other architectural patterns, we discussed how every microservice maintains a database of it's own, and how it helps in serving the purpose of a local cache, thereby reducing latency and increasing performance. But in case of serverless patterns, we do not maintain states for any of our containers as they themselves are ephemeral.
Future
Having seen the origins of the SOA pattern, and it's process of evolution up to the Serverless pattern, we can now see what the future holds for us. At this moment, we work around the problem of having to maintain states in our serverless functions by using a cloud store. Right now this is doing the job for us, but it is not really ideal. Maintaining a separate cloud store is expensive and introduces unnecessary overhead. We want something more traditional, where every microservice maintained a database of it's own thereby maintaining their own state. Microsoft's Azure, has Durarable Functions, which has taken a step in this direction, with the aim of solving this problem. Other problems that we still need to solve, include having triggers and data from data stores to functions. There are various uses cases which demand this requirement. A unified view of the current state, compiled from the states of all the microservices can also help us in many ways. These problems, are one of the hardest and most interesting part in serverless right now. There is a lot of active research and development going on in this field. There is no doubt that serverless will be a big part of the future.
Originally published at blog.pratikms.com





Top comments (0)