
As most data scientists know, dimensionality is a curse; although the number of dimensions is not a curse itself but also the quality of each feature in a specific dimension. Dimensionality reduction is a set of techniques that try to transform the input space into a space with fewer dimensions while keeping the meaning and value of the features. In this post, we will journey through a greedy algorithm (greedy in the sense that it does not guarantee to find the optimal answer) that generates a selection of features that try to minimize the model's error.
Feature selection vs Feature extraction
Dimensionality reduction algorithms can be classified as feature selection methods or feature extraction methods. Feature selection methods are interested in reducing the number of initial features to the ones that give us the most information. On the other hand, feature extraction methods are interested in finding a new set of features, different from the initial ones, and with fewer dimensions.
Subset selection
Subset selection is a feature selection algorithm that can variate between a forward selection and a backward selection. Both methods consist in finding a subset of the initial features that contain the least number of dimensions that most contribute to accuracy. A naive approach would be to try all the 2^n possible subset combinations but if the number of dimensions is too big it would take forever. Instead, based on a heuristic function (error function) we add or remove features. The performance of subset selection depends highly on the model we choose and our pruning selection algorithm.
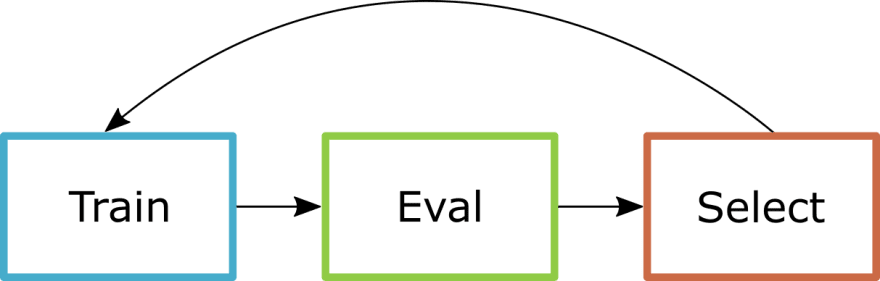
Forward selection
In forward selection we start with an empty set of features, for each feature that is not in the set we train the model with it and test its performance; we then select the feature with the least amount of error. We continue adding new features for the model to train until the error is low enough or until we have selected a proportion of the total features.
Backward selection
Backward selection works in the same way as forward but instead of starting with an empty set and adding features one by one, we start with a full set and remove features one by one. Thus we remove the features that cause the most error.




Top comments (0)