
In Playtomic we are currently handling thousands and thousands of money transactions per month. Therefore, we also have to handle hundreds (or thousands) of refunds per day. And I can assure you that what people care about the most is always their money, so you really want to have a robust refund system or you'll start hearing complaints soon.
To let you understand better how it worked, previously what we were doing was just trying to refund when asked by the users. If it failed? Bad luck, let's wait for the complaints. We needed to build a more resilient refund system. The question was then... how?
Going async
We came to the conclusion that if we wanted a system like that, we cannot be considering the refund process a synchronous one.
We're going to use Apache Kafka to help us. Why? Well, in order to avoid making the entire article about the virtues of Kafka, I'll be brief. Its excellent performance as a publish/subscribe messaging system made it the perfect candidate. Easy to configure for us thanks to Spring Cloud Stream, scalable, fault-tolerant... We just had to configure the topic (Kafka's term for the several channels you use to group events), and then create our producer - the one that will be sending the refund events - and the listener - the one that will be consuming them -.
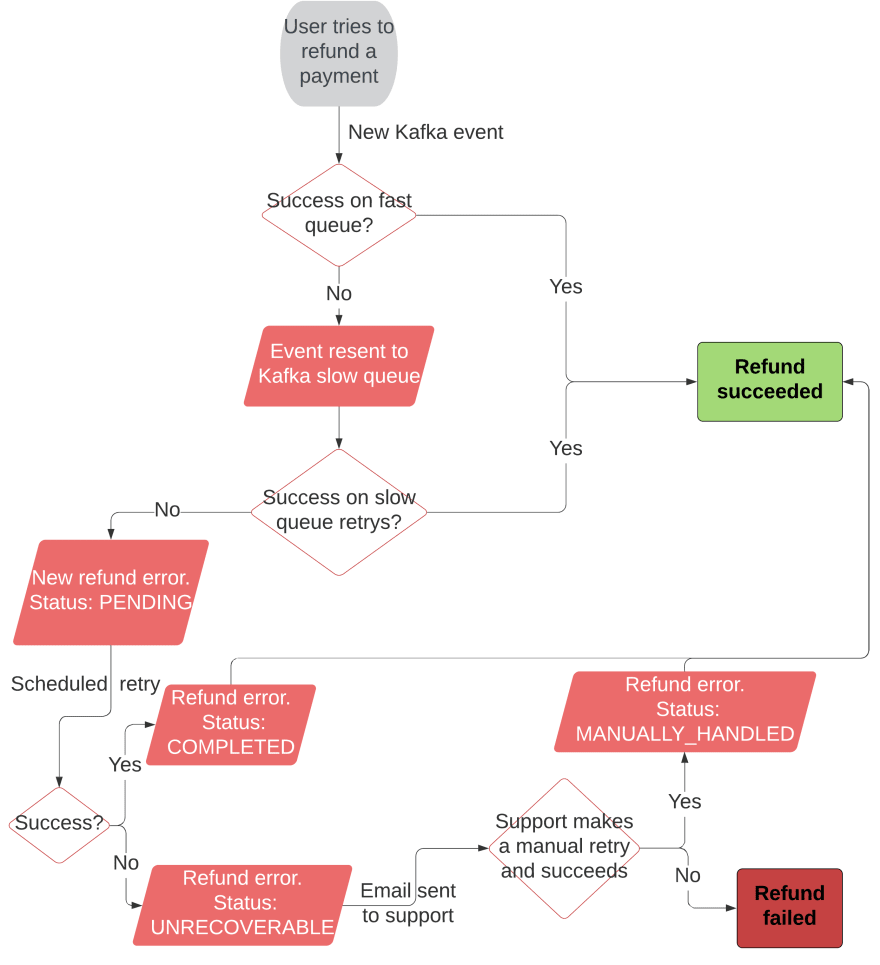
Every refund intent will be converted into a Kafka event that will be processed and will store the id of the payment to be repaid. We'll use two queues since we don't want refunds that will almost certainly fail to cause a kind of traffic jam in our Kafka listener. The first one will be a fast queue, meaning that events will be only processed once. If they succeed, the event will be discarded and no further actions will be required. If they fail, the event will be forwarded to the slow queue and discarded on the fast.
The slower queue will retry to consume the event n number of times with an exponential backoff (Kafka will do all the magic with a simple configuration). Once we reach the maximum number of attempts, we will finally discard the event and store the refund error in our database with its cause, the amount...
Scheduling one last attempt
The Kafka queues can help us to process rapidly the refunds that should work fine, and also to do quick retries in case we encounter a punctual problem. However, this does not address the primary issue. What if, for example, one of our payment methods provider (f.e. Swish) is unavailable for 30 minutes and we attempt to refund a Swish payment on that moment? We must retry again!
In this scenario we're going to use a periodical task, that will execute once a day a reconciliator. It will retry the refunds one more time. If they fail, our support team will be notified and the refund error will be stored to maintain track of it. Support team will be able to retry this refund again manually via an endpoint.
We'll be able to accomplish that using the same error entity by managing its status, as you can see in the following diagram:
What we have accomplished
To summarize, we can see that we have built a refund system much more resilient, as it can work through temporary failures, which are the most frequent ones, without hurting our performance or losing information on the process.
We're also providing to our internal analytics a great way of analysing the causes of the errors in the refunds, and also for the developers to see if we can improve our code by taking a look at the errors stored in our database and studying the frequency, the main causes...
Finally, we have improved the process for the support team. On the one hand, we notify them each time a refund fails, so they can easily keep track of those errors. On the other hand, if customers complain before our process ends, they can simply advise them to wait for a while, they can retry it manually or simply take a look at the error and tell the user the cause.
Room for improvement
As in any process, there's always space for improvement in this process. Some changes are already being considered, such as creating more slow queues specific for payment methods or increasing the frequency of the task that initiates the reconciliation process. We will be analyzing the data we begin to collect in detail in the near future in order to optimize the flow.
Cover photo by rupixen.com on Unsplash

Top comments (0)