Many of you are working in the Data Warehouse area, mostly when start modelling, may ask yourself shall I model this way or could I use some other better approach?If you google about this theme (star schema or snowflake one) you will find a lot of information about them, the comparisons, the pros and cons, the space each of the techniques requires, etc. For example, here is a wiki page collecting several resources on the star schema vs snowflake debate.
In this article I will try to provide some technical insights and my personal view of some details mostly due to the problems I faced in real world solutions. First of all, one must consider, when a company decides to build a decision support system space cannot (or should not...) be an issue, although I understand financial constraints are always present. Project sponsors must be aware information occupies space so one of the main decisions will be:
Shall I look for performance or save on hard-drives and random access memory?
This said, I must also mention my thoughts are mostly directed to huge databases (several million rows or even billion rows sized data sets). So, if required space will be presented as a constraint, your modelling technique will be conditioned by it immediately. Snowflake approach will arise as the way to go as once normalization exists in all or most of the analysis dimensions (if you have big ones) you will save space just by using it.
First of all I think it is important for me to present a brief description of each of the approaches and some relevant concepts
(please consider for more detailed information you can also visit the Teradata home page or LearnDataModelling home page)
In typical Data Warehouse modelling the central model table is called Fact table. In there, you will store your business process main data, the data that will be later used to compute every kind of metrics your CEO or CFO may remember about. It is very important you define your information grain level (its deeper detail). What I mean is if you need to store data at Second level, then consider that detail and aggregate it later if you need to. On the other hand, if you store information at Hour level and four months from now you realize it does not have enough detail, your entire project will be in jeopardize, believe me.
So, based on this very brief introduction, your information will be useless if you cannot group, slice and filter it by important and relevant attributes like time, geography, and many others one can remember of or even generate (like junk dimensions, more on this on future articles). Everyone looking for reports will appreciate seeing information per month, store and type of client or to understand which is the age group where people buy more toilet paper (someone will need this for sure over there).
To be able to present such useful reports you should enrich your Facts with “pointers” to those attributes otherwise they would be data floating around with anything else to do. This is where Analysis Dimensions come to life around our main central table.
So in the end and putting it simple, Star Schema and Snowflake will allow the developer to migrate and assign to each Fact table record a proper identifier regarding that specific analysis attribute. The main difference between them is indeed data normalization versus data redundancy.
Let’s consider a typical time dimension used in 99,8% of Data Warehouse models (the remaining 0.02% are not well modelled for sure :)...). This can be observed more easily if you consider the image bellow.
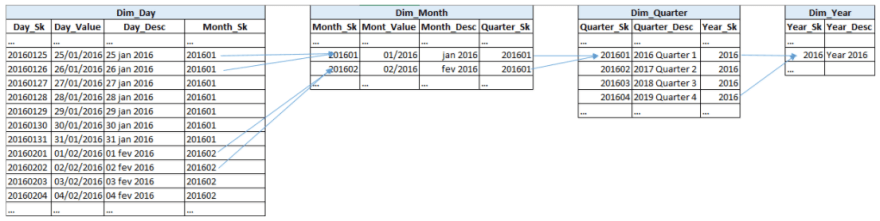
It corresponds to a Snowflake approach once all information is divided into proper grouping levels, it is normalized. The days are the smaller time grain that will present in the fact table. I used a number (as date) that corresponds to the surrogate key (but I could have used a numerical sequence as well). The next image could correspond to the main Dimensional model where the time dimension was pulled from. You can see two normalized dimensions, Time and Geography.
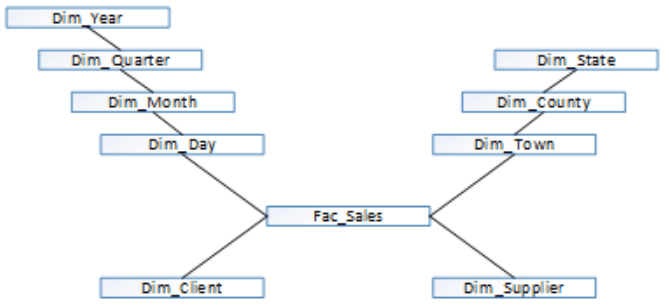
Snowflake approach seems logic and it works very well. Now imagine you have a Day dimension with 100.000 records. Each time you need to pull or analyze data grouped by year the database engine will need to link all four tables together so the proper Year can be found for each fact table grain record. This can or cannot be a problem, it will mostly depend on the database and features being used, if one uses memory resident tables, indexes, indexes or table clustrers, underlying materialized views, data compression, etc. There are techniques that will speed up data grouping a lot, as a possible example, consider migrating Year_Sk to the fact record as well. That logic can make sense if the exploring tool takes advantage of it, it must be able to define and save grouping paths and use the most convenient ones depending on user selections (grouping contexts or data grouping paths).
But we are talking about Dimensional modelling and, to reduce database join work, data can be denormalized so all Day attributes are present in a single table (e.g. a generic Dim_Time, check below please)
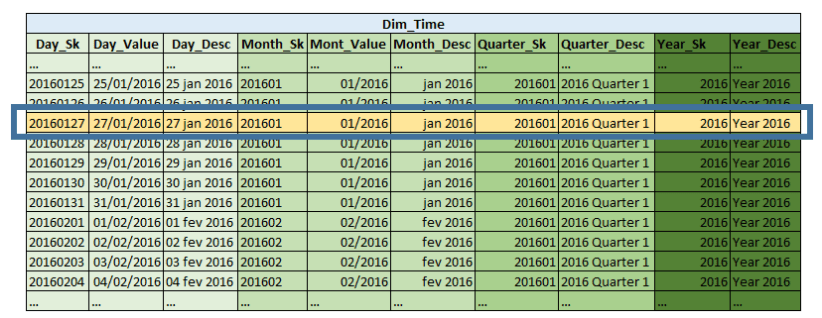
If you read data horizontally you will be able to properly describe each day, its month its quarter, year. Data put this way is not normalized, but on the other hand it was joined already so the database will not need to do it.
My personal opinion is this approach produces better performance, mostly if the columns are highly indexed and queries are selective. A typical Star Schema model approach should look like the image below, on this sample model Geography and Time dimensions could be candidates to some data normalization degree.
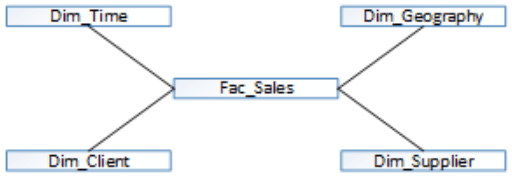
Either way this is not a dogma, nowadays machines are so powerful, memory became much cheaper and solid state drives are becoming the rule, it may even be faster to use a normalized set approach (snowflake) and make tables memory resident (SQL Server feature) as once they are in memory it may be faster to join them than to load data from a non memory resident denormalized table. If dimensions are small joining them can be really fast. You can even have both approaches at the same time, in Oracle you can have a Snowflake approach for a set of tables and, in the background, use a materialized view that joins tables. Depending on queries’ explain plan, Oracle will use the better lookup approach (joining tables or access the materialized view directly). This is why developers should properly separate the modelling logic theory from real world cases and know your tools the best you can. Some tool features can really make the difference regarding ETL or data exploring queries running times.
So, trying to resume some insights regarding Dimensional Modelling we have:
Snowflake approach allows:
- saving space;
- It mimics business logic better as you see group levels perfectly isolated;
- It may be easier to implement hierarchies (that allow drilling down into data grouping);
- It will allow individual dimension re-use along a broad Data Warehouse model (usually called a constellation one). For instance a fact table may have its data daily based while some other business process may have data monthly based. Once you have different dimensions, you can use each one of them linked to the proper and required fact tables. A single time dimension will not allow doing that. Those individual dimensions should be part of the global ETL maintenance plan;
- Snowflake approach may make your ETL lookup process more difficult and slower if more than one level attribute is required to identify the low level dimension surrogate key (the one present in the fact). It will be much slower if you need to join tables to perform a lookup than it will be if you have them joined already (the lookup process will also be conditioned by the tools being used, e.g. it will be possible to cache and load the entire lookup structure in memory so data will only be joined once, SQL Server SSIS can make use of .Net data structures like hash maps or dictionaries that will load data in memory only once, IBM Datastage uses Datasets that also load data in memory and perform parallel lookups);
Star schema is better if:
- You look for performance (but once again check database and underlying tools’ capabilities first, for instance Oracle has a lot of performance improvement features that will make Snowflake run very fast);
- You do not need to bother with space so data redundancy is not a problem (this is important if you have dimensions with let’s say … 26.621.547 million rows). Think on a national wage declaration Data Warehouse, how many persons receive monthly wages;
- Lookup performance will be faster when running ETL processes mostly if the single dimension has properly defined and well thought indexes;
- Accessing the several information aggregation levels should also be faster as all of them are stored in the same table;
Regarding SQL generation, of course generated queries will be more complex to understand in Snowflake schema model as they will join more tables (if you join several dimensions they can become big). This is important if you will be generating the queries by hand, otherwise if they are generated by the exploring tool, the problem is minimized. Star schema queries are simple to generate and to interpret.
As a rule of thumb, I suggest you to understand and think about how will the required queries be generated when your data model is queried, imagine yourself as a database engine, try understanding how it works and you will find the best approach to your model requirements (look at the explain plans). One should not consider this as dogmas, it may even be required to have highly denormalized tables that will be used in ETL lookup processes (so they run faster) and then use Snowflake normalized tables in the exploring tools (of course all these tables should be properly synchronized on the ETL process as well). As usual testing, searching and looking for opinions is always mandatory. Be creative.

Top comments (0)