
⚠️ Nota: La idea original de este proyecto surgió gracias al canal Soumil Shah, por lo que doy crédito y recomiendo ver su serie de vídeos sobre Elastic Search Aquí.
El repositorio con el resultado final puede ser consultado en Github.
Índice
- Post 1 - Introducción: Aquí
- Post 2 - Recolección de los datos: Aquí
- Post 3 - Limpieza y almacenamiento de los datos: Aquí
- Post 4 - Desarrollo de la API (🚧 Trabajando en ello...)
- Post 5 - Desarrollo del cliente Web (🚧 Trabajando en ello...)
Requisitos
- Python (3.10.6 Opcional) y conocimientos básicos de Python.
- Jupyter Notebook
- Docker / Conocimientos sobre Docker y Docker Compose.
"Instalación" de Open Search con Docker
Luego de realizar una limpieza sencilla de los datos, estos serán almacenados en Open Search, por lo que comenzaremos utilizando Docker para inicializar el servicio de Open Search.
Para esto, dentro de la carpeta backend/ crearemos el archivo docker-compose.yml con el siguiente contenido (Leer los comentarios del código) (Más información):
version: "3"
services:
# Este es el servicio principal de Open Search, que nos
# permitirá almacenar datos y realizar búsquedas.
se-opensearch:
# Imagen de docker oficial de open search
image: opensearchproject/opensearch:1.3.6
container_name: se-opensearch
# Nombre del host dentro de la red de docker
hostname: se-opensearch
restart: on-failure
ports:
- "9200:9200"
# Performance analyzer, no lo usaremos, pero
# en la documentacion oficial lo utilizan
- "9600:9600"
expose:
- "9200"
- "9600"
environment:
- discovery.type=single-node
# Deshabilitamos el plugin de seguridad para poder
# conectarnos sin certificados SSL (no recomendado
# para producción)
- DISABLE_SECURITY_PLUGIN=true
volumes:
# Creamos un volúmen para que los datos no se pierdan
# al momento de detener el contenedor de docker.
- opensearch-data-1:/usr/share/opensearch/data
networks:
# Red interna de docker.
- se-opensearch-net
# Este servicio es opcional, solamente añade un dashboard
# web para poder visualizar nuestros datos.
se-opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:1.3.6
container_name: se-opensearch-dashboards
hostname: se-opensearch-dashboards
depends_on:
- se-opensearch
restart: always
ports:
- "5601:5601"
expose:
- "5601"
environment:
- OPENSEARCH_HOSTS="http://se-opensearch:9200"
- DISABLE_SECURITY_DASHBOARDS_PLUGIN=true
networks:
- se-opensearch-net
# Creamos el volúmen
volumes:
opensearch-data-1:
# Creamos la red
networks:
se-opensearch-net:
Una vez creado y guardado el archivo docker-compose.yml, dentro de la carpeta database/ ejecutamos el comando docker-compose up para iniciar el / los servicios:
docker-compose up
Limpieza de los datos
Para comenzar con este apartado, dentro de la carpeta data/cleansing/ crearemos un archivo de Jupyter Notebook, pero antes, de manera opcional, crearemos un entorno virtual de Python (Más información):
Dentro de la carpeta cleansing/:
virtualenv -p python3 environment
Para activar el entorno virtual desde Linux:
source environment/bin/activate
Para activar el entorno virtual desde Windows:
./environment/Scripts/activate
Independientemente de si hemos creado o no el entorno virtual, ahora realizaremos la instalación de Jupyter Notebook, para esto, ejecutamos en la consola:
pip install notebook
Luego de instalarlo, lo ejecutamos con:
jupyter notebook
Dentro de la interfaz web de Jupyter Notebook, creamos un nuevo "cuaderno":

Dentro del nuevo cuaderno, instalaremos los paquetes necesarios:
!pip install pandas
# Paquete para conectarnos a open search
!pip install opensearch-py
# "Paquete" para convertir los textos a vectores
!pip install sentence-transformers
import pandas as pd
import json
import re # Expresiones regulares
# Estos dos paquetes los usaremos para generar un numero
# aleatorio mas adelante
import time
import math
# Coneccion a Open Search
from opensearchpy import OpenSearch
# Helpers para insertar todos los datos de manera rápida
from opensearchpy import helpers
from sentence_transformers import SentenceTransformer
# Descargamos el modelo para transformar los textos
# (Esto puede demorar un poco)
transformer_model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
Luego de instalar los paquetes, "leemos" el archivo data.json generado con el web scraping y lo convertimos a un DataFrame de pandas:
# Leer el archivo
file = open('../scraping/data.json')
data = json.load(file)
# Convertir a un DataFrame de pandas
df = pd.DataFrame(data)
# Mostar el DataFrame
df
Si todo fue correcto, deberíamos ver una tabla como la siguiente:

El primer paso que realizaremos para limpiar los datos es eliminar las entradas duplicadas, para esto, ejecutamos el siguiente código:
print('Length before dropping duplicates: {}'.format(df.shape))
# Eliminamos entradas duplicadas a partir de la url ya que
# esta deber ser única.
df.drop_duplicates(subset=['url'], keep='first', inplace=True, ignore_index=False)
print('Length after dropping duplicates: {}'.format(df.shape))
Luego de eliminar los datos duplicados, podemos eliminar los caracteres indeseados, que en este caso serían:
- Enlaces en las descripciones de los videos
- Saltos de línea.
- Caracteres no alfanuméricos (Incluídos los emojis)
- Espacios en blanco redundantes.
Lo anterior lo haremos mediante expresiones regulares ejecutando el siguiente código:
# Realizamos una copia del dataframe para no afectar el
# original en caso de que algo salga mal
df_bk = df.copy()
# Iteramos cada fila del DataFrame
for index in df_bk.index:
title = df_bk['title'][index]
description = df_bk['description'][index]
tags = df_bk['tags'][index]
new_tags = []
# Remove urls
title = re.sub(r'(http|https|www)\S+', '', title)
description = re.sub(r'(http|https|www)\S+', '', description)
# Remove \n texts
title = title.replace('\n', ' ')
description = description.replace('\n', ' ')
# Remove non-alphanumeric chars
# title = re.sub(r'[^a-zA-Z0-9\']', ' ', title)
description = re.sub(r'[^a-zA-Z0-9]', ' ', description)
# Iteramos cada tag ya que los tags son un array de strings
for tag in tags:
new_tag = re.sub(r'[^a-zA-Z0-9]', '', tag)
new_tag = re.sub(' +', ' ', new_tag)
new_tags.append(new_tag.)
# Remove redundant spaces
title = re.sub(' +', ' ', title)
description = re.sub(' +', ' ', description)
# Set new value
df_bk['title'][index] = title
df_bk['description'][index] = description
df_bk['tags'][index] = tags
# Mostramos el DataFrame resultante al final
df_bk
Si el paso anterior se ejecutó correctamente, deberíamos ver una tabla similar a la que se mostró unos cuantos pasos atrás.
Almacenamiento en Open Search
Teniendo los datos, el paso restante es almacenarlos en Open Search, para lo cual, primero generamos una conexión:
# Connection variables
host = 'localhost'
port = '9200'
# Usuario y contraseñas por defecto
auth = ('admin', 'admin')
# Connect
client = OpenSearch(
timeout = 300,
hosts = [{'host': host, 'port': port}],
http_compress = True,
http_auth = auth,
use_ssl = False,
verify_cers = False,
)
client.ping()
Si ejecutamos la celda anterios, debería mostrarse un True, caso contrario, comprobar que el docker-compose esté siendo ejecutado o revisar la documentación oficial:

Antes de almacenar los datos en Open Search, crearemos una nueva columna para almacenar el vector que representa cada uno de los vídeos (Más información):
# Creamos una columna vacía
df_bk = df_bk.assign(vector="")
Ahora, insertaremos en la nueva columna el vector del vídeo correspondiente (Más información):
# Iteramos cada fila / vídeo
for index in df_bk.index:
title = df_bk['title'][index]
description = df_bk['description'][index]
tags = df_bk['tags'][index]
# Creamos un solo string que contenga los textos importantes del vídeo
bundle = title + ' ' + description
for tag in tags:
bundle += ' ' + tag
# Transformarmos el string único a un vector con el
# modelo descargado previamente
vector = transformer_model.encode(bundle)
# Asignamos el vector a la columna vacía
df_bk['vector'][index] = vector
# Mostramos el DataFrame final
df_bk
Si todo se ejecutó correctamente, deberíamos ver una tabla como la siguiente:

Teniendo todos los datos del vídeo, podemos crear el índice de Open Search, el cual puede ser visto como el equivalente a una tabla en bases de datos relacionales, aunque no son exactamente lo mismo:
index_name = 'videos'
index_body = {
'settings': {
# Es necesario configurar esto para utilizar el plugin KNN
# EN la mayoría de campos se dejaron los valores por defecto
'index': {
'number_of_shards': 20,
'number_of_replicas': 1,
'knn': {
'algo_param': {
# Default 512: https://opensearch.org/docs/latest/search-plugins/knn/knn-index#method-definitions
# Higher values lead to more accurate but slower searches.
'ef_search': 256,
# Using during graph creation
'ef_construction': 256,
# Bidirectional links for each element
'm': 4
}
}
},
'knn': 'true'
},
# A continuación se definen las "columnas" del índice, las
# cuales son los campos de nuestros videos
'mappings': {
'properties': {
'url': {
'type': 'text'
},
'thumbnail': {
'type': 'text'
},
'title': {
'type': 'text'
},
'description': {
'type': 'text'
},
'tags': {
# Text type can be used as array
'type': 'text'
},
'vector': {
'type': 'knn_vector',
'dimension': 384
}
}
}
}
# Si el índice ya existe, lo eliminamos (Esto es solo en caso
# de ejecutar el notebook nuevamente)
if(client.indices.exists(index=index_name)):
client.indices.delete(index=index_name)
# Creamos el índice
reply = client.indices.create(index_name, index_body)
print(reply)
Lo anterior debería mostrar una respuesta como la siguiente:
{'acknowledged': True, 'shards_acknowledged': True, 'index': 'videos'}
Finalmente, podemos insertar nuestros datos; para esto, podríamos iterar cada una de las filas e insertarlas individualmente, pero utilizaremos el método bulk de Open Search que nos permite insertar grandes cantidades de datos de un manera rápida:
# Crearemos un array ya que el método bulk recibe un elemento
# iterable
data = []
# Iteramos cada fila del DataFrame
for index in df_bk.index:
# Tomamos todos los datos
url = df_bk['url'][index]
thumbnail = df_bk['thumbnail'][index]
title = df_bk['title'][index]
description = df_bk['description'][index]
tags = df_bk['tags'][index]
vector = df_bk['vector'][index]
# Formamos un diccionario con los datos y lo insertamos al array
# El campo _index es necesario para indicarle a Open Search
# el índice al que debe agregar los datos
data.append({'_index': index_name,
'url': url,
'thumbnail': thumbnail,
'title': title,
'description': description,
'tags': tags,
'vector': vector})
# Insertamos los datos
reply = helpers.bulk(client, data, max_retries=5)
Para comprobar que los datos se insertaron correctamente, podemos simular búsquedas dentro del Notebook (Ver ídea original):
# Recibir el input por teclado
query = input('Enter your query: ')
# Convertir el input a un vector (Para poder usar el plugin KNN en Open Search).
query_vector = transformer_model.encode(query)
open_search_query = {
# Tomamos 24 resultados
'size': 24,
# Campos que nos interesan de la respuesta
'_source': ['url', 'thumbnail', 'title', 'tags'],
# Filtro
"query": {
"bool": {
'must': [
# Usamos el plugin knn
{'knn': {
"vector": {
# Le pasamos nuestro vector
"vector": query_vector,
# Tomamos los 24 "vecinos más cercanos"
"k": 24
}
}}
]
}
}
}
response = client.search(
# Buscamos en nuestro índice
index = index_name,
# Limitamos a 24 resultados
size = 24,
# Cuerpo de la búsqueda
body = open_search_query,
request_timeout = 64
)
# Simplificamos el resultado ya que por defecto tiene muchos
# otros campos
videos = [x['_source'] for x in response['hits']['hits']]
# Mostramos los resultados obtenidos
videos
A continuación algunos ejemplos de búsquedas:
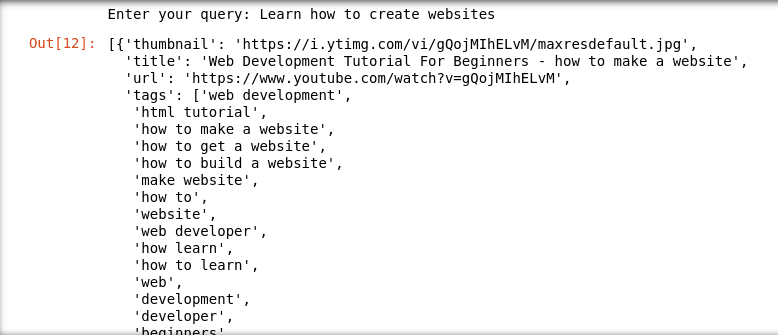

Final
Con esto se concluye esta tercera parte en la que hicimos una limpieza sencilla de nuestros datos y los almacenamos en Open Search, te invito a continuar con la siguiente en la que desarrollaremos una API de Python para permitir a nuestros usuaruios realizar búsquedas.
Referencias
Para consultar las referencias dirigirse a cada uno de los enlaces que aparencen dentro o al final de los diferentes párrafos.

Latest comments (0)