
Sometimes you need an automated function to repeat the same job on an interval. Begin has scheduled functions just for this task. In this tutorial, we will be building a GitHub issue scraper that will store information once a day.
To start, let's make a new OpenJS Architect project from the command line along with a couple of dependencies.
npm init @architect ./my-issue-tracker
cd my-issue-tracker
npm install @begin/data tiny-json-http
Open up the folder in your code editor of choice and modify the app.arc file to the following:
# app.arc
@app
my-issue-tracker
@http
get /
@scheduled
issues rate(1 day)
@tables
data
scopeID *String
dataID **String
ttl TTL
The app.arc file is your infrastructure-as-code manifest. It tells Architect where your source code is and what to deploy.
Now you can run arc init to scaffold out our scheduled function.
Next, we can modify our scheduled function at src/scheduled/issues/index.js
let tiny = require('tiny-json-http')
let data = require('@begin/data')
exports.handler = async function scheduled (event) {
console.log(JSON.stringify(event, null, 2))
let date = new Date().toLocaleDateString()
let url = 'https://api.github.com/repositories/137939671/issues'
const issues = await tiny.get({ url })
let numberOfIssues = issues.body.length
//save the number of issues per day
await data.set({
table: 'issues',
number: numberOfIssues,
date: date
})
return
}
Finally, we can push this up to GitHub and associate it with a new Begin app.
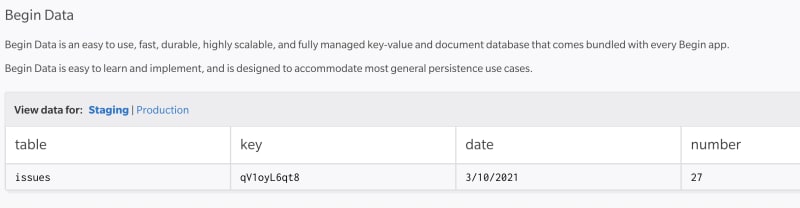
After deployment, the function will invoke itself for the first time. This is when you can verify that it worked by checking the logs. You can also look in the Begin Data console and see that it saved a number with today's date.
You can find the full example code here: https://github.com/pchinjr/my-issue-tracker

Top comments (0)