
I’ve talked briefly before about developers suffering from “it works on my machine mentality. The result is bugs that don’t appear on a developer’s machine, but do appear for users. There is a worse class of bugs though that affects everyone at a company: “it works in my office when I’m trying it”
How is this different? Things can get pretty complex in a live web application. The vast number of variables involved mean it is perfectly possible for users to see bugs that no one at the company can reproduce. Not the developer. Not the UX designer. Not customer support. Not management.
Since no one at a company can reproduce the issue, it becomes easy to assume that the problem is with the user and can not be solved.
This can have huge implications for a company. When there are a small number of users, only a handful of bug reports will come in, if any. These are the easiest bugs to write off as user error. However, a large percentage of users could be seeing this issue and choosing not to file the bug reports. They just choose not to use the product instead and tell their friends not to use it.
For a company with a larger number of users, lots of bug reports will come in for something no one at the company can see. This is harder to write off as user error because so many people are encountering the same bug. Yet without the ability to reproduce it, it can be extremely frustrating trying to figure out the issue.
So what are some of these issues and how can they be resolved?
One is called replication delay. Let’s assume your product is using a SQL database. While growing the product, the system only needed a single database server, otherwise known as the master database.

After a certain number of users, this single server starts to see some strain. Fortunately this isn’t too difficult to manage for most applications that have more reads than writes.
An example of this is a Facebook post. A person writes a post in their newsfeed, which results in 1 write to a database. 100 people read that post which results in 100 reads to a database.
In this situation we can easily offload the work our SQL database needs to do using something called “read slaves”. These are other database servers whose only purpose is to copy (replicate) data from the master database.
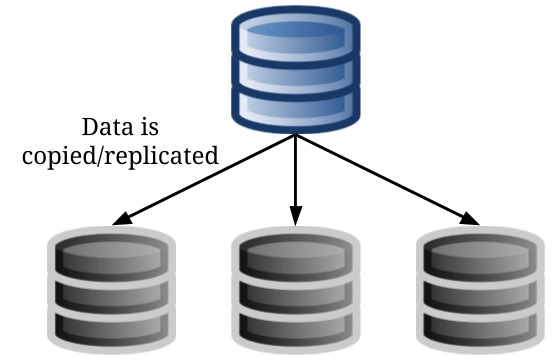
Whenever someone needs to read that data, such as reading the post, we can go to a read slave to get the data instead of the master database. If we have 100 reads for every write like in the above example, this can significantly reduce the amount of work our master database has to do.
Easy right?
Here is where things get frustrating. The replication from a master database to a read slave takes time. Usually this is a few milliseconds and barely noticeable. So a user can make a post, which makes a write to the master database, and then we can let them view it with a read to the read slave.
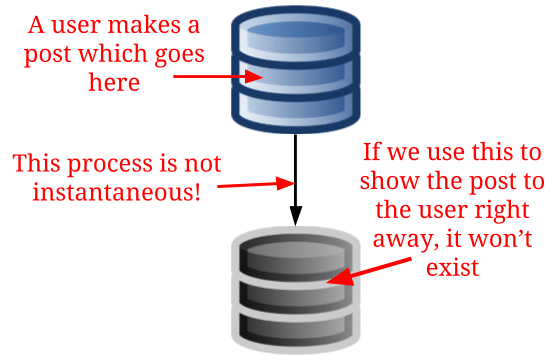
The problem is when a large number of writes start to happen, the time to replicate data to a read slave increases. So let’s say a really big event is happening and hundreds of thousands of people are making posts in a very short period of time. Depending on a number of factors such as the quality of the hardware, the time to replicate data from a master database to a read slave may now take a few seconds or more.
If you make a post on Facebook, how long does it take for you to see it? Less than a second? What happens if the data isn’t on the read slave?
Developers who aren’t aware that this can happen wouldn’t have put in any safeguards for it. The result is that in certain periods of time, a user can make a post and not see it. This can be a frustrating experience because they may think it wasn’t posted successfully so they may post it again and have lots of duplicate posts.

Or the application can crash, which is never great for a user.
So you get all these bug reports. How long does it take for a developer to start investigating? An hour? A day? The event could be over by the time someone starts investigating. Replication delay is back to a few milliseconds. Anyone at the company who tries to reproduce the issue will be unable to. You’re now waiting for a developer to have a “eureka! moment or for a big event to happen serendipitously at the same time as a developer starts looking at the issue. Yuck!
This bug is in a category of bugs called “race conditions”. It’s called that because there are two actions running independently: one runner is writing data to a database while another runner is reading data to deliver it to the user. If one runner wins, our application works great. If the other runner wins, we have a bug. 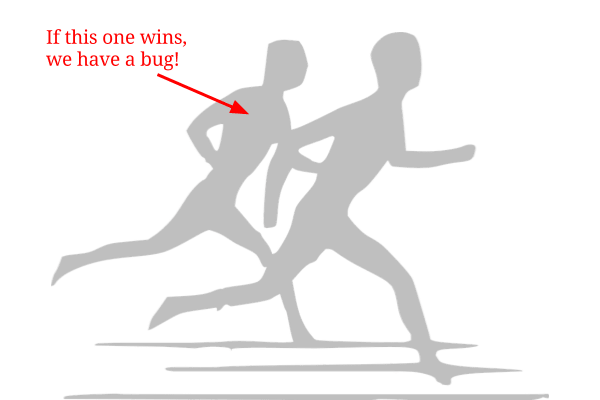
It would be nice if this race was fixed and one runner always won. That would prevent the bugs we are seeing. Unfortunately our runners are a little too ethical. Jerks.
There are other examples of race conditions. What if one person tries to comment on a post at the same time the original author deletes it?
What happens when one person tries to change something in Google Docs at the same time as another person?
Or what if a seller on an e-commerce site changes the price of an item right between a buyer going from their shopping cart to the checkout page? Do you change the price on the buyer? Do you tell the seller there will be a delay in the price change?
We have the potential for negative user experiences in all of these situations. It doesn’t help that the user doesn’t know there is another action taking place at the same time as theirs. Things are just broken from their perspective.
For example, if a price changes between the shopping cart and checkout, the bug report is not going to say “looks like the price changed while I was checking out my shopping cart at the same time the seller changed prices.”
The bug report is more likely to say:
“YOU ******* LIED TO ME ABOUT THE PRICE OF THIS THING!!! I’M NEVER SHOPPING WITH YOU AGAIN.”
Is that going to be an informative description of the issue? Will anyone be able to take that and go “I know what’s happening! Probably not unless they have encountered a very similar issue before.
I haven’t mentioned any solutions about how to fix or prevent these issues. That’s because in most cases any solution will impact how the product functions and have UX implications. Changing prices in an e-commerce site is the perfect example of that.
That makes these more than just development issues. They are product issues and the entire team needs to be involved in resolving them. Every product is unique and will need its own tailored solutions.
This post was originally published on blog.professorbeekums.com

Top comments (1)
...besides mosquitos.