
Linting your source code is oftentimes an integral part in software development processes. Whether it is to check if you misspelled words, violate against a certain code style or recklessly used tabs over spaces (don't worry, I won't judge), linters offer a great way to automate mundane tasks to free up time and energy for other things.
As the time had arrived for me to work on my bachelor thesis, I decided on implementing a linter for source code written in Go - primarily because I wanted to learn a new language and always wondered if I could write a linting application myself.
In this post I want to explain some of the concepts I have picked up while working on the project.
Linting using an Abstract Syntax Tree (AST)
Abstract Syntax Trees decompose your source code and represent it in a tree form. This way you can traverse the resulting tree, enabling you to collect information you are interested in.
Let's look at a really small example of what I mean by "tree form":
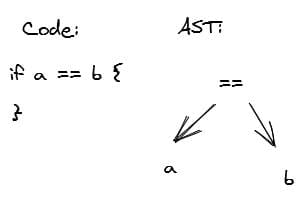
In Go, the standard package provides us with go/ast which already implements a lot of the functions you would typically need for building and traversing a tree.
In the scenario above, you would be able to inspect the components by looking at the .X (a) and .Y (b) components of .BinaryExpr (==).
For one of my use cases, I needed to check how many conditional operands a specific condition has. I then used the information to suggest decomposing the condition to smaller pieces if the count exceeds a limit.
The following code shows how a conditional statement gets evaluated to eventually obtain the total count of operands:
func (validator DecomposeConditionsValidator) evaluateConditionalExpression(stmt ast.Expr) int {
switch expression := stmt.(type) {
case *ast.BinaryExpr:
return 1 + validator.evaluateConditionalExpression(expression.X) + validator.evaluateConditionalExpression(expression.Y)
case *ast.ParenExpr:
return validator.evaluateConditionalExpression(expression.X)
default:
return 0
}
}
All the tree nodes are traversed in a recursive manner, thus providing us with the sum of operands when the recursive invocation stops.
Traversing the file system
Linting applications usually validate each file recursively, starting from a root directory. For each file, a AST is constructed which is then used as the input for the rules/validators setup by the author.
Usually you can use packages for your programming language that abstract the file system by providing methods to interact with it. I was surprised to see how neatly Go is supporting recursive traversal with path/filepath.
Here's a simplified view on how I used recursive file traversal:
err = filepath.Walk(linter.BaseDir, func(path string, info os.FileInfo, err error) error {
// construct AST tree
// initialize data structure to store results
// for each rule
// check the AST tree
// append to the results
// add results to a linting report structure
}
// return linting report
Defining the rules (validators)
Now we have established how a linter traverses the file system and how source code is represented by an abstract syntax tree. Another crucial part of the system is the implementation of validators (or whatever you want to call them).
As an example, let's say you wanted to check the length of each variable name in order to suggest more expressive names when the length is only 1 (let's discard valid reasons you might use such short names - e.g. Point.X or Point.Y coordinates). You would then express this rule as functions/methods/classes (you choose), usually defined in separate files.
As an example, you can check how ESLint organizes their rules.
For the use case above, you could for example represent "fail when the variable name length is below a limit" as follows:
for _, elem := range statement.Lhs {
switch identifier := elem.(type) {
case *ast.Ident:
if len(identifier.Name) < validator.Rule.Limit {
result = stats.Failed
identifierNames = append(identifierNames, identifier.Name)
}
}
}
Displaying the results
In order to decouple the presentation of the linting results from the creation, I defined a common report structure to store the output generated by the program. Here is a sample structure I have used for my linter:
type Report struct {
Id primitive.ObjectID `bson:"_id"`
Timestamp time.Time `bson:"timestamp"`
FileCount int `bson:"fileCount"`
ErrorCount int `bson:"errorCount"`
WarningCount int `bson:"warningCount"`
PassedCount int `bson:"passedCount"`
Files FileResultList `bson:"files"`
}
Apart from the file results themselves, some metadata is stored for later processing. While the structure above may not be the most extensible one, it was sufficient enough for me to implement the requirements of the project.
For later display, I stored the results in MongoDB and retrieved them by using a REST API that is being called by a React frontend application.
Conclusion
It is interesting to see how many components need to interact
in order to provide valuable feedback for developers. First we traverse through the file system while constructing an abstract syntax tree for each file. Then we can lint the source code with validators to eventually display the results to the users.
However, given the short time span, I wasn't able to fully implement all of the capabilities a good linter usually provides. Some of them include:
- Annotations to ignore lines or blocks of source code
- Automatically fix warnings/errors found
- Extensive configuration options
- IDE integrations
While I have laid out some of the core components of my linter, I still hope to eventually return and learn more about the inner-workings of the mechanisms outlined above.

Top comments (0)