
In today's world, we rarely come across completely isolated Salesforce CRM implementations. In most cases, the fact that Salesforce will become the heart of the enterprise's business transformation process means that it has to be connected with dozens of other applications. Integration cost is sometimes overlooked or underestimated, despite the various studies that point out that around 25-35% of the total project cost will likely be spent on integration. The Salesforce Architect is expected to be able to design a secure and scalable integrated solution.
In this article, we will review key architectural principles, concepts, and options for Salesforce integration, and indeed for integration more generally.
Integration in the enterprise
The digital enterprise landscape is becoming ever more sophisticated. Today's enterprises have hundreds, if not thousands, of different, in addition to all the legacy systems that still survive the axe. Nowadays, it is very common to find that an enterprise has dozens of websites, multiple instances of ERP systems, and many other departmental applications, in addition to several data warehouses or lakes.
One of the reasons why enterprises end up in such situations is because of the complexity associated with building business applications. Building a single application that runs all business processes is nearly impossible. Spreading business functions into smaller chunks of applications provides the business with enough flexibility and agility to move at the pace they need, rather than being bound by the technical boundaries of a bigger all-in-one solution. Moreover, it gives the business the opportunity to pick and choose the best suite of applications that best serve their needs – the best customer relationship management (CRM) system, the best order management system (OMS), and the best enterprise resource planning (ERP) solution.
In the past 20 or so years, we've seen vendors offering applications focusing on specific core functions. We’ve also noticed the continuous addition of functionalities to applications, causing functionality spillover. For example, we have seen customer care software getting extensions to include a limited billing functionality, due to the difficulty in drawing clear functional separations between systems. (If a customer raises a dispute for a bill, will that be considered something to be handled by customer care or the billing applications?)
On the other hand, users do not really care about these boundaries or the systems that are involved behind the scenes. They just expect a business function to be executed, regardless of the system or systems involved in delivering it. For example, when a customer places an order online, this will likely require coordination between several systems to deliver several functionalities, such as checking the history or credit score of the customer, checking inventory, computing tax, creating the order, fulfilling the order, handling shipment, etc. These processes can span across multiple systems, but from the customer's perspective, it was a single transaction. To support such distributed functionalities, which are expected to work as a coherent business process, applications need to be integrated in an efficient, secure, scalable, and reliable fashion.
Typical enterprise integration needs are as follows:
- Get the right information: Get precise knowledge of a particular piece of information created by different systems and enterprise business processes, structured in a consumable way that can support other business needs.
- Get that information to the right place: This requires mechanisms to handle information transactions across heterogeneous environments.
- Get that information at the right time: Ideally, this requires distributing the information in real-time to reflect the actual state of a particular data entity.
- Flexibility and change-readiness: To adapt to external factors, such as market demand, a shift in customer behavior, new legislation, or a shift in social philosophy.
- Coordinate business processes: This is a challenging operation that may require modeling the enterprise business's processes, how they are interlinked, and what kind of information they exchange. This may require a deep understanding of the business.
Good integration architecture depends on understanding and applying a number of design principles and concepts. Let’s now look at those.
Integration architecture design principles
As with any complex technical architectural topic, there are various considerations and consequences that you need to keep in mind while designing the target integration strategy and architecture.
The main decision points are usually as follows:
- Native integration: If you can develop a single standalone application that can fulfill all business needs on its own then you can avoid a lot of complexity driven by integration requirements. However, in reality, this is not something you can normally achieve. Many attempts to extend an application so that it includes other functionalities can end up creating a complex system that is hard to manage and maintain or develop to meet new business requirements. This problem exists in the Salesforce world as well, although in a more limited way. Many Salesforce products are natively integrated, with many considered the best in the market. For example, Salesforce Communities provides a native solution to exposing a customer portal that is natively integrated with your CRM. Salesforce Communities offer a very good sharing model and an easy way to control the look and feel of the community itself. It makes sense to favor that over a solution where you need to build a custom-made customer portal over some technology, then figure out a way to integrate it with Salesforce in a secure and compliant way. Moreover, using the native integration keeps the doors open for using other natively integrated features in the future.
- Simplicity: This goes beyond the integration architecture. Avoid complicated solutions as much as possible and always keep the golden 80-20 rule in mind. Fulfilling 80% of use cases using a simplified architecture should be preferred over targeting a solution that covers 100% of the use cases using an over-complicated architecture. Keep your integration code simple and tidy.
- Application dependencies: Integrated applications should have minimal dependencies on each other. This allows solutions to evolve independently, and also allows us to replace an application completely without it impacting the other integrated systems. Tightly coupled applications rely on many assumptions regarding how each of them works. When an application is modified, the assumptions could change, which would, in turn, break the integration. In a loosely coupled integration, the integration interface is specific enough to deliver a particular functionality but generic enough to allow for change if needed.
- Timing: Ideally, the integration architecture should aim to minimize the duration between the moment an application is sending data and another application is receiving it. The aim should be to share small chunks of data as frequently as possible, rather than wait to exchange a huge block of data that may not necessarily be related. Data sharing latency should be taken into consideration while designing the architecture. The longer a data exchange process takes, the more likely it will become prone to other challenges, such as a change in the data's state. Bulk data exchanges can still be used for the right use cases, such as archiving operational data.
- Synchronous versus asynchronous: In a synchronous process, a procedure waits until all its sub-procedures finish executing. However, in an integrated environment, where the integrated applications might be on different networks or might not necessarily be available at the same time, you may find more use cases where the procedure doesn't have to wait for all of its sub-procedures to conclude. It simply invokes the sub-procedure and then lets it execute asynchronously in the background, making use of the multi-threading ability of many of today's applications.
- Integration technology: Selecting the right technology is essential. Depending on the integration techniques available, there might be higher dependencies on specific skillsets, hardware, or software, which could impact the speed and agility of your project.
- Data formats: Data exchanged between different applications must follow a pre-agreed format. In the enterprise world, this is unlikely, so the integration process must have an intermediate step where the data is translated from one format into another. Another related challenge is the natural evolution of data formats. Flexibility to accommodate the changes to a data format is a key aspect of the overall flexibility of an integration architecture.
- Data versus functionality: Integration is not necessarily about sharing data. The integrated applications could be looking to share functionality. Think of the use case where one application needs to invoke a particular functionality in another system, such as checking for a particular customer's credit score. There will likely be a set of parameters that is sent to satisfy the logic of the remote process. Invoking remote functionalities can be difficult and may have a significant impact on how reliable the integration is. As a Salesforce architect, you need to be aware of specific integration patterns, and you need to understand the limitations of the platform.
Having considered some important general principles and issues, let's now have a look at modern integration approaches and the kinds of middleware tool that are available so that as an architect you can select the right options for your particular project.
Modern integration tools
Extract, transform, and load (ETL)
In this method of data integration, the data is copied from one or more data sources into destination data store that does not necessarily share the same structure as the data source(s):
- Data extraction involves accessing one or more data sources and extracting data from them.
- Data transformation includes all the data processing that takes place before the data is delivered to its final destination, including data cleansing, data formatting, data enrichment, data validation, and data augmentation.
- Data loading includes the processes required to access and load the data into the final target data store.
ETL tools may stage the data into a staging area or staging data store to run complex transformations on it, such as de-duplication, custom logic, or data enrichment by looking up external reference data. Normally, the staging data store would co-exist with the ETL tool on the same server to provide the quickest possible response times. The three ETL processes take time, so it is common to have them scheduled or running in an asynchronous fashion. Most of the modern ETL tools can be scheduled to run a particular job every few minutes. Some ETL tools can also expose a triggerable endpoint, which is simply an HTTP listener that can receive a message from specific authorized senders in order to trigger one or more ETL jobs. For example, a listener can be exposed to receive a specific type of outbound message from a particular Salesforce instance. Once that outbound message is received, the listener triggers one or more ETL jobs to retrieve or update data in Salesforce, as well as other systems.
Most of today's ETL tools come with built-in connectors for different types of application databases, such as Salesforce, Microsoft Azure, Amazon Redshift, Amazon S3, SAP, and many others. In addition, they come with adapters to generic database APIs, such as Open Database Connectivity (ODBC) and Java Database Connectivity (JDBC).
Some even provide connectors for the File Transfer Protocol (FTP) and SSH File Transfer Protocol (SFTP). These connectors allow us to access a particular application database in an optimized fashion. For example, the Salesforce connector could be built to automatically switch between using the Salesforce's standard REST API, the Salesforce SOAP API, or the Salesforce BULK API, depending on the operation that's been executed and the amount of data being dealt with.
Today, several ETL products are provided in a SaaS fashion. In this case, you need to understand how the ETL tools can connect to a database behind a firewall. The enterprise's hosted applications and database would normally reside behind the enterprise firewall. Most enterprises have strict regulations that prevent such resources from being exposed. These are known as demilitarized zones (DMZs). A DMZ is a physical or logical subnetwork that is used by the enterprise to expose external-facing materials and contents – mainly to the public, who are untrusted users. Resources in these DMZs can be accessed by cloud-based applications. However, this is not how cloud-based ETL tools get access to the enterprise's locally hosted applications. One of the most popular ways to achieve this is by installing a client application on the enterprise's local network. This is a trusted application provided by the ETL tool product provider, and its main duty is to facilitate communication between the enterprise's local applications and databases and the cloud-based ETL tool. The security team will still need to configure the firewall to allow the client to communicate back and forth with the cloud-based ETL tool.
ETL tools are very suitable for data replication operations. They are designed and built to provide a robust and scalable service since they can deal with millions – even billions – of records. ETL tools are also ideal for data replications that require a lot of time, such as replicating media files. They are very flexible and easy to work with.
As a Salesforce architect, you need to know about some of the popular ETLs that are used today. You also need to understand the limitations of out-of-the-box tools such as Salesforce Data Loader, which is too simple to be categorized as an ETL tool. Some of the most popular ETL tools that are used with Salesforce today are Informatica PowerCenter, Informatica Cloud, Talend, Jitterbit, and MuleSoft.
Enterprise Service Bus
Enterprise Service Bus (ESB) is a name given to a particular method of data integration where the different applications are integrated via a communication bus. Each different application communicates with the bus only. This decouples the applications and reduces dependencies; systems can communicate without knowing the details of how other systems operate. ESB tools support different architectural concepts such as microservices, API-led connectivity, and event-driven architectures. We will cover all these concepts later on in this article.
ESBs support both synchronous and asynchronous types of communication, which makes it ideal for integrations operating on the business logic layer, where RPI is a key capability to look for. ESBs also utilize built-in connectors to connect to different types of applications and data stores, similar to ETL tools. The connector here would also transform the data from the source system format into the bus format. Considering that ESBs are usually stateless, the state of each message in the bus is included as part of the message itself. While the data is traveling through the bus, it is considered to be in a canonical data format. A canonical data format is simply a model of the data that supersets all the other models of the same data in the landscape. This canonical data is normally translated into target data models. The Cloud Information Model (CIM) is a good example of a canonical data model. Describing CIM is beyond the scope of this article, but becoming familiar with it is strongly recommended.
ESBs can handle complex orchestrations. For example, an application A might send customer details to the ESB, which, in turn, would communicate with multiple external applications to do a real-time credit check, followed by an invocation to the CRM system, to start a customer onboarding journey. The customer onboarding journey then generates a unique customer ID that is returned to application A with a success message. ESBs can handle complex orchestrations and can use a supporting database as a temporary storage or as a cache for some data. The database would normally co-exist with the ESB tool on the same server to provide the quickest possible response time.
The ESB also handles any kind of required data cleansing, data formatting, data enrichment, data validation, and data augmentation, as well as translations from/to different data formats. For example, you can imagine an application A sending data in the Intermediate Document (IDoc) format to the ESB, which receives it, augments it with other data coming from a lookup/reference data source, and then translates that into the formats expected by the recipients, such as XML, CSV, JSON, and others.
ESBs can also provide multiple interfaces for the same component, which is particularly useful for providing backward compatibility, especially for web services. ESBs are normally designed to be very scalable and capable of handling a very high load of traffic, and several modern ESBs are offered today in a SaaS fashion with an option to host them locally. Due to their stateless nature, ESBs are not considered ideal for long-running operations such as replicating a massive amount of data between systems or moving large media files.
As a Salesforce architect, you need to know some of the popular ESBs that are in use today. You also need to understand when and why to propose utilizing an ESB. ESBs and ETLs are very common in Salesforce solutions, so make sure you fully understand the differences between ESBs and ETLs, and which is good for what. Also, make sure you understand why, in most cases, enterprises should utilize middleware of some sort instead of P2P connections. And, make sure you understand the ideal use cases for ESBs in order to recognize whether they are utilized optimally in a given implementation or not. Some of the popular ESB tools that are used with Salesforce today are MuleSoft webMethods Integration Server, IBM Integration Bus, TIBCO ActiveMatrix Service Bus, and WSO2 Enterprise Integrator.
Reverse proxies
A reverse proxy is the opposite of a forward proxy: while a forward proxy is used as an intermediary the client uses to connect to a server, a reverse proxy is something the server (or servers) would put between itself and potential clients. For the end client, any retrieved resources, in this case, would appear as if they were originated by the proxy server itself, rather than the server or servers that sit behind it. A reverse proxy is often used to provide a more secure interface to deal with untrusted clients (such as unauthorized internet users), as well as shield the other applications behind it that might lack the ability to handle excessive load or be unable to provide the required security measures (such as an inability to support HTTPS). A reverse proxy can provide capabilities such as transforming HTTPS requests into HTTP, handling cookies and session data, transforming one request into multiple requests behind the scenes, and then combining the responses and buffering incoming requests to protect the shielded servers from excessive load. Some of the providers of reverse proxy products are VMware, Citrix Systems, and F5 Networks.
API gateways
API gateways are historically used to protect your internal web services (or APIs – remember that we are using the two terms interchangeably in the web context as most modern APIs are offered as web services). The enterprise's internal APIs might not be designed to handle issues such as authentication and scalability, and an API gateway can provide a layer on top to protect the APIs, as well as enable other functionalities, such as monetizing the APIs, providing real-time analytics, and protecting against denial of service (DoS) attacks.
API gateways are very similar in concept to reverse proxies. In fact you can think of an API gateway as a special type of reverse proxy. On some occasions, you might have both of them in your landscape, with the API gateway sitting behind the reverse proxy, which handles load balancing. API gateways can normally be configured via an API or UI. On the other hand, reverse proxies are normally configured via a config file and require a restart so that they can use a new set of configurations. API gateways also provide advanced API functionalities such as rate limiting, quotas, and service discovery. As a Salesforce architect, you need to know about some of the popular API gateways in use today. Some of the most popular ones used with Salesforce today are MuleSoft, Microsoft's Azure API Management, Google (Apigee), and IBM API Management.
Stream-processing platforms
Stream-processing platforms are systems designed to make the most out of parallel processing, to fully utilize the computational capabilities of their server. Ideally, they are utilized in event-driven integrations. We will cover event-driven integration shortly.
Stream-processing platforms can handle huge amounts of incoming data since they are designed to make use of elastic scaling. They are also normally easy to encapsulate in containers, which makes them easy to deploy on different platforms, including Cloud, on-premises, or hybrid environments. Stream-processing platforms are often ideal when there is a need for a massively scalable messaging platform, such as an IoT server. Some of the most popular stream-processing tools in use today are Apache Kafka, Amazon Kinesis, Redis, and RabbitQ. Salesforce Heroku supports some of these technologies, such as Kafka.
With that, we have covered the different middleware options, with different values-driven out of each. We will now outline some of the main modern approaches to application integration, such as service-oriented architecture, microservices, API-led connectivity, and event-driven architectures.
Exploring modern integration approaches
As a Salesforce architect, you are dealing with modern and changing tools and technologies every day. It is very important to align the knowledge we covered earlier with today's modern integration approaches. Some of these approaches are becoming less popular, but their concepts are still the basis of other more modern approaches. To fully understand modern integration approaches and be able to lead discussions with your client, enterprise architects, and integration architects about the most appropriate integration strategy, you need to have a wide knowledge of modern integration approaches, in addition to a solid understanding of their basis. In my experience, technology enthusiasts can sometimes get carried away with new concepts and terminologies. While staying up to date with the latest and greatest market trends is very important, it is your duty as a senior architect to understand which of these approaches are most suitable for your client.
Service-oriented architecture
Service-oriented architecture (SOA) is an approach of software development that aims to encapsulate business logic into a service that makes the most out of reusable code. Each service contains the code and data integrations required to fulfill a particular business use case; for example, placing a shopping order or onboarding a new customer.
These services are loosely coupled and utilize an enterprise service bus to communicate with each other. This means that developers can save time by reusing existing SOA services across the enterprise.
SOA services are logical representations of particular business activities with clear specific outcomes. They are provided more or less as a black box for consumers who don't need to worry about how these services are working. Services can consist of multiple other underlying services.
SOA emerged in the late 1990s and was the base for other modern integration approaches such as microservices and event-driven architecture. Some critics of SOA mention challenges regarding its performance, maintainability, and the difficulties associated with designing it to the right level of granularity.
A simplified SOA-based architecture would look as follows:
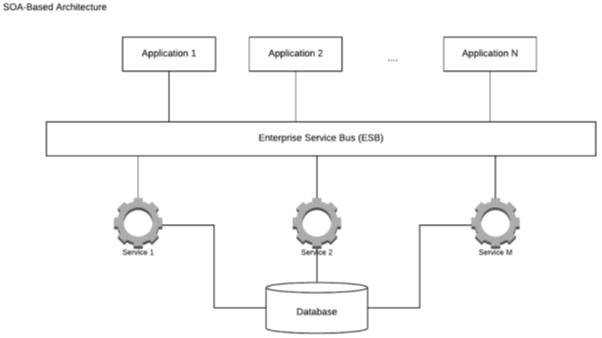
Figure 1 – An example of a SOA-based architecture
Microservices
Microservice architectures are a modern interpretation of SOA. They are also made up of loosely coupled and reusable components with clear functionality and outcome. Rather than communicating through an ESB, microservices communicate with each other directly. The services can use different technologies and protocols.
The microservices architecture is very much geared toward the Cloud. It utilizes Development and Operations (DevOps) concepts to allow small decentralized teams to take complete ownership of a particular service, deliver its functionality using their preferred technology, and rapidly release it to the enterprise using lightweight containers.
Microservices are typically used as building blocks for other enterprise applications. They are finely grained services, and they have access to their own data stores that provide access to all the data they need. Microservices are never supposed to access the same data store/database as this would create a dependency between them and every other data store. The microservices principles favor encapsulation and independence over reusability; redundant code is considered an acceptable side effect.
Microservices became popular since their introduction in 2014 due to their relationship with DevOps concepts. Due to the similarity between SOA and microservices, it is good to understand some of the key differences between these particular integration approaches:
- Synchronous calls: Reusable SOA services should be available throughout the enterprise via the use of synchronous protocols such as SOAP or REST APIs. Synchronous calls are less preferred in the microservices architecture as they may create real-time dependencies, which may cause latency. An asynchronous approach is preferred, such as publish/subscribe, which would enhance the resilience and availability of the services.
- Communication: SOA services utilize the ESB to communicate, which can make ESB a performance bottleneck. Microservices are developed independently, and they communicate directly using different protocols and standards.
- Reuse: SOA is all about increasing reuse, whereas in the microservices architecture, this is less important – especially considering that achieving some reusability at runtime could create dependencies between the microservices, which reduces agility and resilience. With microservices, duplicating code by copying and pasting it is considered an accepted side effect of avoiding dependencies.
- Data duplication: In SOA, the services can directly access and change data in a particular data source or application. This means that multiple SOA services would likely be accessing the same data store. Microservices always aim to reduce dependencies. A microservice should ideally have local access to all the data it needs to deliver its expected functionality. This means that there might be a need to duplicate some data, and also that the data could be out of sync between the different services. Data duplication adds a considerable amount of complexity to the design and potential usage of microservices, which has to be balanced against the expected gains from the microservice's independence.
- Granularity: Microservices are designed to do one specific task; they are very specialized and therefore finely grained. On the other hand, SOA services reflect business services, so they can range from small to bigger enterprise-wide services.
- Speed: As we mentioned earlier, speed is one of the weaker sides of SOA, due to several factors. Microservices are lightweight, more specialized, and usually utilize lightweight communication protocols such as REST. They generally run faster than SOA services.
A simplified microservices-based architecture would look as follows:
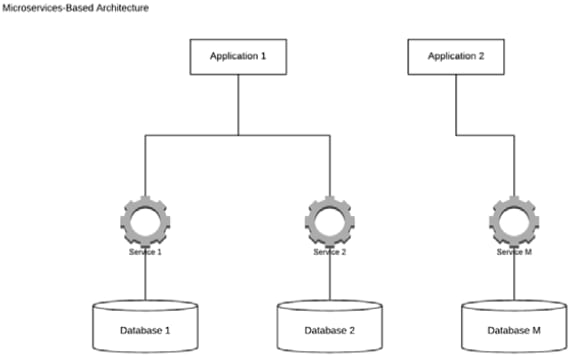
Figure 2 – An example of a microservices-based architecture
API-led architecture
The API-led architecture is a strategy where all external and internal services are exposed as managed APIs, regardless of how they were implemented (microservices, SOA services, web services driven out of a monolithic application, or based on other architectures). Managed APIs in today's terms do more than just provide governance capabilities such as security policies, throttling, versioning, and automatic service discovery. The principle has extended beyond that to include developer portals where developers can experiment with APIs before using them, productivity tools, and a mechanism to register and pay for API usage. In this approach, APIs are usually organized on three different layers:
- System APIs are meant to access core systems and services. They provide a simplified insulating layer between the service consumer and the underlying system or service.
- Process APIs are meant to interact, transform, and shape the data coming from the underlying system APIs or from other process APIs, effectively breaking down data silos. They have no dependency on the source systems where the data came from, nor on the target systems where the data will be delivered. Both system APIs and process APIs can be used to connect to existing microservices, as well as other enterprise services, depending on the use case.
- Experience APIs are meant to allow easy access and data consumption for the end user or application. They typically communicate with one or more process APIs to deliver a specific functionality.
Microservices are known to create many endpoints, which are normally difficult to control and monetize. The API-led architecture aims to create an API strategy that governs the way the different enterprise services interact between each other, as well as with external consumers, by utilizing the capabilities of lightweight standards such as REST and combining them with modern API gateway capabilities.
Previously, we mentioned that microservices are typically consumed by applications. The API-led architecture aims to turn these applications into a smaller and lighter set of APIs. This can help enterprises take steps toward the API economy. For example, an enterprise could create a set of APIs on top of their rich set of services, which are built with different technologies and based on different architectures, and then utilize an API manager to expose these services externally and internally with different applicable policies and subscription mechanisms. Moreover, this approach is seen as an enabler for rapid application development, since you can reuse APIs that are built on top of different business processes. MuleSoft Anypoint Platform is a tool that enables enterprises to deliver API-led integration architecture.
Event-driven architecture
Event-driven architecture is an approach of software development that utilizes events to communicate and trigger actions in integrated and decoupled applications. An event is simply a change in status of a particular object. For example, a change in the customer status value could fire a customer status change event that would, in turn, trigger a set of actions in integrated systems, such as starting a particular marketing journey.
The event-driven architecture inherits some principles from the messaging integration style, as we mentioned earlier. The event-driven architecture has three main components: event producers, event routers, and event consumers. The producers publish events to the router, the routers handle filtering and pushing the events to the subscribed consumers, and the consumers receive the event, parse it and transform it into a format suitable for their needs, and then use it, typically to update their own version of the data or to fire subsequent logic. Stream-processing platforms, modern ESBs, or event routing buses such as CometD are usually used as routers.
Summary
That concludes our overview of modern application integration. Hopefully, the understanding you have acquired of some of the main integration architecture principles and tools will stand you in good stead when, in your capacity as a technical architect, you come to your next big integration project.
This article is part of Tameem Bahri's book Becoming a Salesforce Certified Technical Architect. Tameem condenses his Salesforce wisdom into an easy-to-follow guide to help you get started on your journey as a CTA. Check it out to discover how the book will help you develop architectural knowledge and the soft skills required to create end-to-end solution presentations.


Top comments (0)