

In this dynamic environment, gathering time-sensitive public data only once is useless as it quickly becomes obsolete. To be competitive, you must keep your data fresh and run your web scraping scripts repeatedly and regularly.
The easiest way is to run a script in the background. In other words, run it as a service. Fortunately, no matter the operating system in use – Linux or Windows – you have great tools at your disposal. This guide will detail the process in a few simple steps.
Preparing a Python script for Linux
In this article, information from a list of book URLs will be scraped. When the process reaches the end of the list, it loops over and refreshes the data again and again.
First, make a request and retrieve the HTML content of a page. Use the Requests module to do so:
|
urls = [ 'https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html', 'https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html', 'https://books.toscrape.com/catalogue/sharp-objects_997/index.html', ]
index = 0 while True: url = urls[index % len(urls)] index += 1
print('Scraping url', url) response = requests.get(url) |
Once the content is retrieved, parse it using the Beautiful Soup library:
|
soup = BeautifulSoup(response.content, 'html.parser') book_name = soup.select_one('.product_main').h1.text rows = soup.select('.table.table-striped tr') product_info = {row.th.text: row.td.text for row in rows} |
Make sure your data directory-to-be already exists, and then save book information there in JSON format.
Protip: use the pathlib module to automatically convert Python path separators into a format compatible with both Windows and Linux systems.
|
data_folder = Path('./data') data_folder.mkdir(parents=True, exist_ok=True)
json_file_name = re.sub('[: ]', '-', book_name) json_file_path = data_folder / f'{json_file_name}.json' with open(json_file_path, 'w') as book_file: json.dump(product_info, book_file) |
Since this script is long-running and never exits, you must also handle any requests from the operating system attempting to shut down the script. This way, you can finish the current iteration before exiting. To do so, you can define a class that handles the operating system signals:
|
class SignalHandler: shutdown_requested = False
def init(self): signal.signal(signal.SIGINT, self.request_shutdown) signal.signal(signal.SIGTERM, self.request_shutdown)
def request_shutdown(self, args): print('Request to shutdown received, stopping') self.shutdown_requested = True
def can_run(self): return not self.shutdown_requested |
Instead of having a loop condition that never changes (while True), you can ask the newly built SignalHandler whether any shutdown signals have been received:
|
signal_handler = SignalHandler()
# ...
while signal_handler.can_run(): # run the code only if you don't need to exit |
Here’s the code so far:
|
import json import re import signal from pathlib import Path
import requests from bs4 import BeautifulSoup
class SignalHandler: shutdown_requested = False
def init(self): signal.signal(signal.SIGINT, self.request_shutdown) signal.signal(signal.SIGTERM, self.request_shutdown)
def request_shutdown(self, args): print('Request to shutdown received, stopping') self.shutdown_requested = True
def can_run(self): return not self.shutdown_requested
signal_handler = SignalHandler() urls = [ 'https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html', 'https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html', 'https://books.toscrape.com/catalogue/sharp-objects_997/index.html', ]
index = 0 while signal_handler.can_run(): url = urls[index % len(urls)] index += 1
print('Scraping url', url) response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser') book_name = soup.select_one('.product_main').h1.text rows = soup.select('.table.table-striped tr') product_info = {row.th.text: row.td.text for row in rows}
data_folder = Path('./data') data_folder.mkdir(parents=True, exist_ok=True)
json_file_name = re.sub('[': ]', '-', book_name) json_file_path = data_folder / f'{json_file_name}.json' with open(json_file_path, 'w') as book_file: json.dump(product_info, book_file) |
The script will refresh JSON files with newly collected book information.
Running a Linux daemon
If you’re wondering how to run a Python script in Linux, there are multiple ways to do it on startup. Many distributions have built-in GUI tools for such purposes.
Let’s use one of the most popular distributions, Linux Mint, as an example. It uses a desktop environment called Cinnamon that provides a startup application utility.

It allows you to add your script and specify a startup delay.


However, this approach doesn’t provide more control over the script. For example, what happens when you need to restart it?
This is where systemd comes in. Systemd is a service manager that allows you to manage user processes using easy-to-read configuration files.
To use systemd, let’s first create a file in the /etc/systemd/system directory:
|
cd /etc/systemd/system touch book-scraper.service |
Add the following content to the book-scraper.service file using your favorite editor:
|
[Unit] Description=A script for scraping the book information After=syslog.target network.target
[Service] WorkingDirectory=/home/oxylabs/Scraper ExecStart=/home/oxylabs/Scraper/venv/bin/python3 scrape.py
Restart=always RestartSec=120
[Install] WantedBy=multi-user.target |
Here’s the basic rundown of the parameters used in the configuration file:
- After – ensures you only start your Python script once the network is up.
- RestartSec – sleep time before restarting the service.
- Restart – describes what to do if a service exits, is killed, or a timeout is reached.
- WorkingDirectory – current working directory of the script.
- ExecStart – the command to execute.
Now, it’s time to tell systemd about the newly created daemon. Run the daemon-reload command:
systemctl daemon-reload |
Then, start your service:
systemctl start book-scraper |
And finally, check whether your service is running:
|
$ systemctl status book-scraper book-scraper.service - A script for scraping the book information Loaded: loaded (/etc/systemd/system/book-scraper.service; disabled; vendor preset: enabled) Active: active (running) since Thu 2022-09-08 15:01:27 EEST; 16min ago Main PID: 60803 (python3) Tasks: 1 (limit: 18637) Memory: 21.3M CGroup: /system.slice/book-scraper.service 60803 /home/oxylabs/Scraper/venv/bin/python3 scrape.py
Sep 08 15:17:55 laptop python3[60803]: Scraping url https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html Sep 08 15:17:55 laptop python3[60803]: Scraping url https://books.toscrape.com/catalogue/sharp-objects_997/index.html Sep 08 15:17:55 laptop python3[60803]: Scraping url https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html |
Protip: use journalctl -S today -u book-scraper.service to monitor your logs in real-time.
Congrats! Now you can control your service via systemd.
Running a Python script as a Windows service
Running a Python script as a Windows service is not as straightforward as one might expect. Let’s start with the script changes.
To begin, change how the script is executed based on the number of arguments it receives from the command line.
If the script receives a single argument, assume that Windows Service Manager is attempting to start it. It means that you have to run an initialization code. If zero arguments are passed, print some helpful information by using win32serviceutil.HandleCommandLine:
|
if name == 'main': if len(sys.argv) == 1: servicemanager.Initialize() servicemanager.PrepareToHostSingle(BookScraperService) servicemanager.StartServiceCtrlDispatcher() else: win32serviceutil.HandleCommandLine(BookScraperService) |
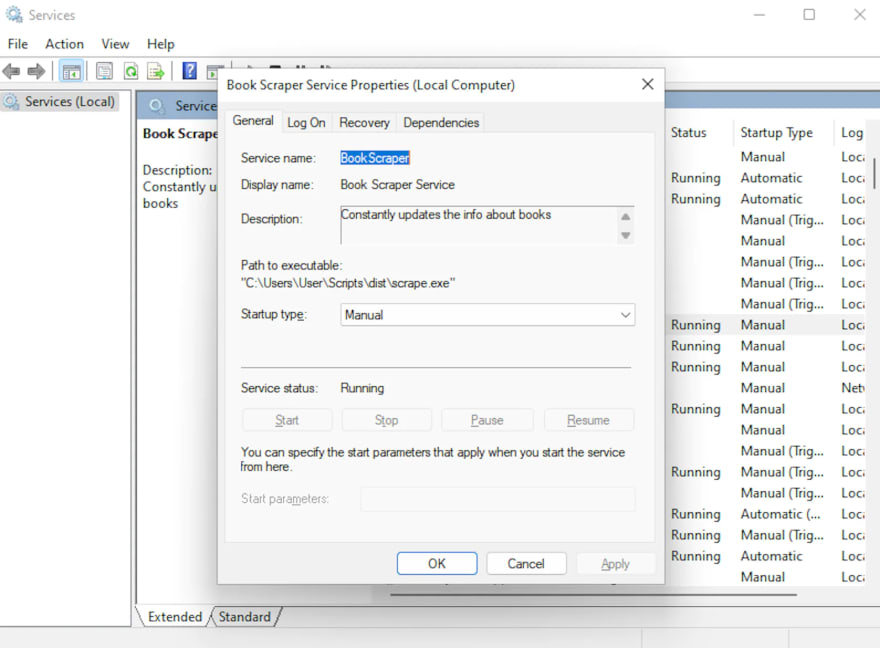
Next, extend the special utility class and set some properties. The service name, display name, and description will all be visible in the Windows services utility (services.msc) once your service is up and running.
|
class BookScraperService(win32serviceutil.ServiceFramework): svc_name = 'BookScraperService' svc_display_name = 'BookScraperService' svc_description = 'Constantly updates the info about books' |
Finally, implement the SvcDoRun and SvcStop methods to start and stop the service. Here’s the script so far:
|
import sys import servicemanager import win32event import win32service import win32serviceutil import json import re from pathlib import Path
import requests from bs4 import BeautifulSoup
class BookScraperService(win32serviceutil.ServiceFramework): svc_name = 'BookScraperService' svc_display_name = 'BookScraperService' svc_description = 'Constantly updates the info about books'
def init(self, args): win32serviceutil.ServiceFramework.init(self, args) self.event = win32event.CreateEvent(None, 0, 0, None)
def GetAcceptedControls(self): result = win32serviceutil.ServiceFramework.GetAcceptedControls(self) result |= win32service.SERVICE_ACCEPT_PRESHUTDOWN return result
def SvcDoRun(self): urls = [ 'https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html', 'https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html', 'https://books.toscrape.com/catalogue/sharp-objects_997/index.html', ]
index = 0
while True: result = win32event.WaitForSingleObject(self.event, 5000) if result == win32event.WAIT_OBJECT_0: break
url = urls[index % len(urls)] index += 1
print('Scraping url', url) response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser') book_name = soup.select_one('.product_main').h1.text rows = soup.select('.table.table-striped tr') product_info = {row.th.text: row.td.text for row in rows}
data_folder = Path('C:\Users\User\Scraper\dist\scrape\data') data_folder.mkdir(parents=True, exist_ok=True)
json_file_name = re.sub('[': ]', '-', book_name) json_file_path = data_folder / f'{json_file_name}.json' with open(json_file_path, 'w') as book_file: json.dump(product_info, book_file)
def SvcStop(self): self.ReportServiceStatus(win32service.SERVICE_STOP_PENDING) win32event.SetEvent(self.event)
if name == 'main': if len(sys.argv) == 1: servicemanager.Initialize() servicemanager.PrepareToHostSingle(BookScraperService) servicemanager.StartServiceCtrlDispatcher() else: win32serviceutil.HandleCommandLine(BookScraperService) |
Now that you have the script, open a Windows terminal of your preference.
Protip: if you’re using Powershell, make sure to include a .exe extension when running binaries to avoid unexpected errors.

Once the terminal is open, change the directory to the location of your script with a virtual environment, for example:
cd C:\Users\User\Scraper |
Next, install the experimental Python Windows extensions module, pypiwin32. You’ll also need to run the post-install script:
|
.\venv\Scripts\pip install pypiwin32 .\venv\Scripts\pywin32_postinstall.py -install |
Unfortunately, if you attempt to install your Python script as a Windows service with the current setup, you’ll get the following error:
|
* WARNING * The executable at "C:\Users\User\Scraper\venv\lib\site-packages\win32\PythonService.exe" is being used as a service.
This executable doesn't have pythonXX.dll and/or pywintypesXX.dll in the same directory, and they can't be found in the System directory. This is likely to fail when used in the context of a service.
The exact environment needed will depend on which user runs the service and where Python is installed. If the service fails to run, this will be why.
NOTE: You should consider copying this executable to the directory where these DLLs live - "C:\Users\User\Scraper\venv\lib\site-packages\win32" might be a good place. |
However, if you follow the instructions of the error output, you’ll be met with a new issue when trying to launch your script:
Error starting service: The service did not respond to the start or control request in a timely fashion |
To solve this issue, you can add the Python libraries and interpreter to the Windows path. Alternatively, bundle your script and all its dependencies into an executable by using pyinstaller:
venv\Scripts\pyinstaller --hiddenimport win32timezone -F scrape.py |
The --hiddenimport win32timezone option is critical as the win32timezone module is not explicitly imported but is still needed for the script to run.
Finally, let’s install the script as a service and run it by invoking the executable you’ve built previously:
|
PS C:\Users\User\Scraper> .\dist\scrape.exe install Installing service BookScraper Changing service configuration Service updated
PS C:\Users\User\Scraper> .\dist\scrape.exe start Starting service BookScraper PS C:\Users\User\Scraper> |
And that’s it. Now, you can open the Windows services utility and see your new service running.
Protip: you can read more about specific Windows API functions here
 .
.

Making your life easier by using NSSM on Windows
As evident, you can use win32serviceutil to develop a Windows service. But the process is definitely not that simple – you could even say it sucks! Well, this is where the NSSM (Non-Sucking Service Manager) comes into play.
Let’s simplify the script by only keeping the code that performs web scraping:
|
import json import re from pathlib import Path
import requests from bs4 import BeautifulSoup
urls = ['https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html', 'https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html', 'https://books.toscrape.com/catalogue/sharp-objects_997/index.html', ]
index = 0
while True: url = urls[index % len(urls)] index += 1
print('Scraping url', url) response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser') book_name = soup.select_one('.product_main').h1.text rows = soup.select('.table.table-striped tr') product_info = {row.th.text: row.td.text for row in rows}
data_folder = Path('C:\Users\User\Scraper\data') data_folder.mkdir(parents=True, exist_ok=True)
json_file_name = re.sub('[': ]', '-', book_name) json_file_path = data_folder / f'{json_file_name}.json' with open(json_file_path, 'w') as book_file: json.dump(product_info, book_file) |
Next, build a binary using pyinstaller:
venv\Scripts\pyinstaller -F simple_scrape.py |
Now that you have a binary, it’s time to install NSSM by visiting the official website. Extract it to a folder of your choice and add the folder to your PATH environment variable for convenience.

Then, run the terminal as an admin.

Once the terminal is open, change the directory to your script location:
cd C:\Users\User\Scraper |
Finally, install the script using NSSM and start the service:
|
nssm.exe install SimpleScrape C:\Users\User\Scraper\dist\simple_scrape.exe nssm.exe start SimpleScrape |
Protip: if you have issues, redirect the standard error output of your service to a file to see what went wrong:
nssm set SimpleScrape AppStderr C:\Users\User\Scraper\service-error.log |
NSSM ensures that a service is running in the background, and if it doesn’t, you at least get to know why.
Conclusion
Regardless of the operating system, you have various options for setting up Python scripts for recurring web scraping tasks. Whether you need the configurability of systemd, the flexibility of Windows services, or the simplicity of NSSM, be sure to follow this tried & true guide as you navigate their features.
If you have any questions about this tutorial or any other web scraping topics, don't hesitate to comment on this post, we'll answer you right away.

Top comments (0)