
There is a very old issue regarding "encoding detection" in a text file that has been partially resolved by a program like Chardet.
Nowadays, one could argue that this issue is not actually one. Indeed, most standards are providing a way to declare the encoding, like in HTTP specifications.
But the reality is different, a huge part of the internet still have content with an unknown encoding. One could point out subrip subtitle (SRT) for instance.

This is why a popular package like Requests list Chardet as a requirement to guess apparent encoding on remote resources.
But there is a catch. First of all, libraries like Chardet are unreliable, unmaintained and sometime even disliked publicly by their owner.
Nearly all popular libraries are using the same idea, for each code page or encoding they want to detect they create a specific probe. They are trying to identify originating encoding.
The first thing I did not like is the idea of single prober per encoding table that could lead to hard coding specifications. Secondly, I am convinced that we should not care about the originating encoding, that because two different tables can produce two identical files.
This is where I came with an alternative. A crazy one : Using brute-force to get sense out of a given content. For each encoding there is.
- Exclude encoding that does not fit content at all
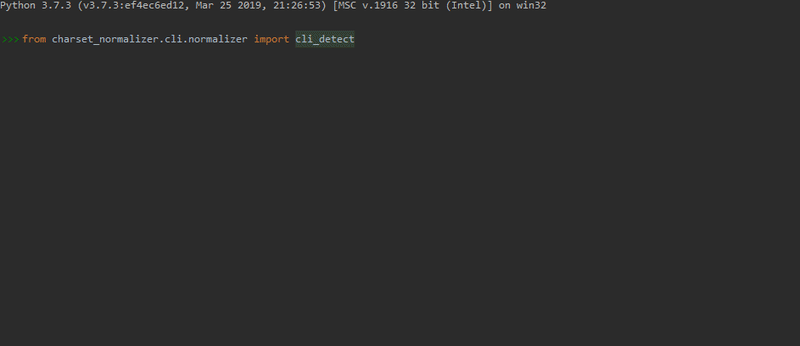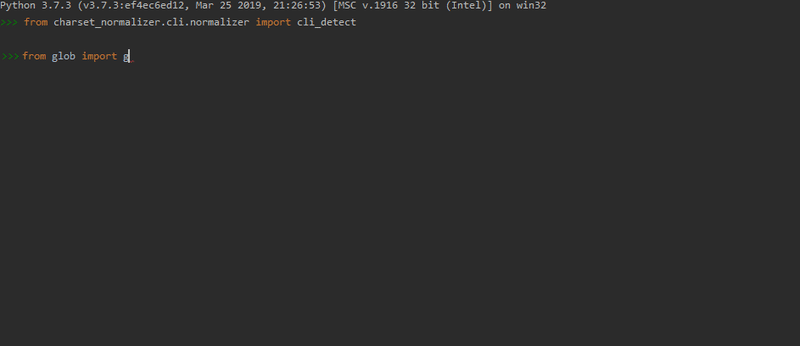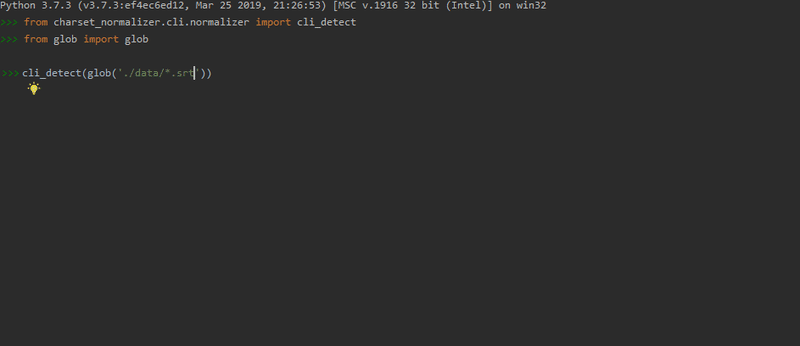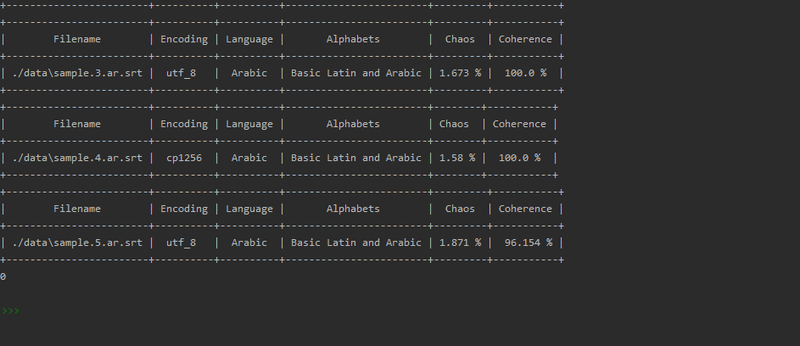
- Measure observable chaos once opened, identify things like "жГЪСЭ Ян"
- Measure coherence by letter appearances frequencies
By not creating specific probe per encoding I was able to provide detection for around 90 encodings ! That's more than twice compared to Chardet and it is actually more reliable.

So I present to you Charset Normalizer. The real first universal charset detector. Or if currently busy or whatnot, try it online via this url

Top comments (0)