
Hey everyone, in this blog, I am going to talk about banking-related failures and how we can overcome them using LitmusChaos.
Have you ever come across a banking failure?
Today due to mobile banking apps, for instance, allow you to deposit checks from the comfort of anywhere. At the same time, you can check your balance, transfer funds, and set up a notification to alert you if you overdraft your account without a need to visit a branch. It is a real time-saver!
But at the same time, if the bank’s server is down or the connection is slow, you would not be able to access your accounts, and it would be difficult to know if your transaction went through.
We will be going through the following topics one by one:
-
Bank Of Anthosand its relation with LitmusChaos - Bank-Of-Anthos-Resiliency Workflow
- Getting Started with Litmus
- Injecting Chaos and observing results.
- Conclusion, References, and Links.
About Bank Of Anthos and its relation with LitmusChaos
Bank of Anthos is a sample HTTP-based web app that simulates a bank's payment processing network, allowing users to create artificial bank accounts and complete transactions.
Google uses this application to demonstrate how developers can modernize enterprise applications using GCP products.
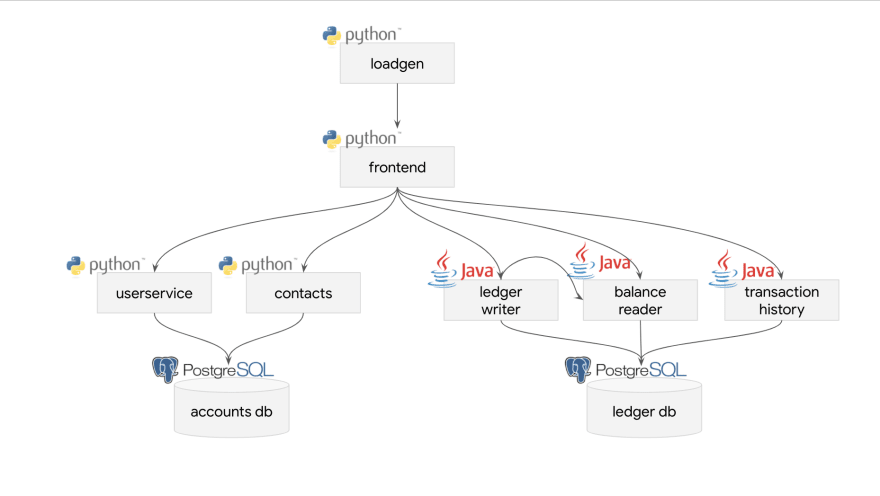 The architecture of Bank Of Anthos
The architecture of Bank Of Anthos
In LitmusChaos, we have been working and testing our experiments on Bank Of Anthos applications. Chaos Experiments contain the actual chaos details.
We have two scenarios: weak and resilient. Based on that, we will perform our experiment workloads and try to find an effect on the cause.
This workflow allows the execution of the same chaos experiment against two versions of the bank-of-anthos deployment: the weak ones are expected to fail while the resilient ones succeed, essentially highlighting the need for deployment best-practice.
Getting Started with Litmus
Litmus is an open-source Chaos Engineering platform that enables teams to identify weaknesses & potential outages in infrastructures by inducing chaos tests in a controlled way.
Developers & SREs can execute Chaos Engineering with Litmus as it is easy to use, based on modern chaos engineering practices & community collaboration. Litmus is 100% open source & CNCF-hosted.
Litmus takes a cloud-native approach to create, manage and monitor chaos.
Chaos is orchestrated using the following Kubernetes Custom
Resource Definitions (CRDs):
- ChaosEngine: A resource to link a Kubernetes application or Kubernetes node to a ChaosExperiment. ChaosEngine is watched by the Chaos-Operator that invokes Chaos-Experiments.
- ChaosExperiment: A resource to group the configuration parameters of a chaos experiment. ChaosExperiment CRs are created by the operator when experiments are invoked by ChaosEngine.
- ChaosResult: A resource to hold the results of a chaos experiment. The Chaos-exporter reads the results and exports the metrics into a configured Prometheus server.
Chaos experiments are hosted on hub.litmuschaos.io. It is the central hub, where the application developers, vendors share their chaos experiments so that their users can use them to increase the resilience of the applications in production.
Injecting Chaos and observing results:
Pod-network-loss injects chaos to disrupt network connectivity to balancereader & transactionhistory Kubernetes pods.
The application pod should be healthy once the workflow run is complete. Service requests should be served, despite the chaos. This experiment causes loss of access to application replica by injecting packet loss using litmus.
Network loss is done on a balancereader or transactionhistory pod that reads from ledger DB and runs as a single replica deployment and not as a multi-replica in weak scenarios. Due to loss, balancereader and transactionhistory are inaccessible (or Read-Only), resulting in failed requests.
In a single replica deployment, the user is not able to - see the details, add the details or get information. Whereas in two deployments it is possible to add details. The balancereader or transactionhistory details can be added and retrieved via provided APIs.
Checking using the Probe:
The HTTP probe allows developers to specify a URL that the experiment uses to gauge health/service availability (or other custom conditions) as part of the entry/exit criteria. The received status code is then mapped against an expected status. It can be defined at .spec.experiments[].spec.probe, the path inside ChaosEngine.
We have been using HTTP probe again front end URL http://frontend.bank.svc.cluster.local:80 with the probe poll interval of 1 second.
We have been using HTTP probe again front end URL “http://frontend.bank.svc.cluster.local:80” with probe poll interval 1 sec.
- name: "check-frontend-access-url"
type: "httpProbe"
httpProbe/inputs:
url: "http://frontend.bank.svc.cluster.local:80"
insecureSkipVerify: false
method:
get:
criteria: "=="
responseCode: "200"
mode: "Continuous"
runProperties:
probeTimeout: 2
interval: 1
retry: 2
probePollingInterval: 1
In a weak scenario, only one replica of the pod is present. After chaos injection, it will be down, and therefore accessibility will not be there, and eventually, it will fail due to frontend access.
In a resilient scenario, two replicas of pods are present. After chaos injection, one will be down. Therefore, one pod is still up for accessibility and will still be there to pass due to frontend access.
The probe will retry for timeout duration for accessibility change. If the termination time exceeds the timeout without accessibility, it will fail.
Litmus Portal
Litmus-Portal provides console and UI experience for managing, monitoring, and events around chaos workflows. Chaos workflows consist of a sequence of experiments run together to achieve the objective of introducing fault into an application or the Kubernetes platform.
Applying k8s manifest
kubectl apply -f https://raw.githubusercontent.com/litmuschaos/litmus/2.0.0-Beta9/docs/2.0.0-Beta/litmus-2.0.0-Beta.yaml
After installation is complete, you can explore every part of the Chaos control plane and predefined workflows.
You will find a similar screen like this.
Open
Bank of Anthospredefined workflow to get the details.

Now to schedule a workflow using a control plane, select the option.
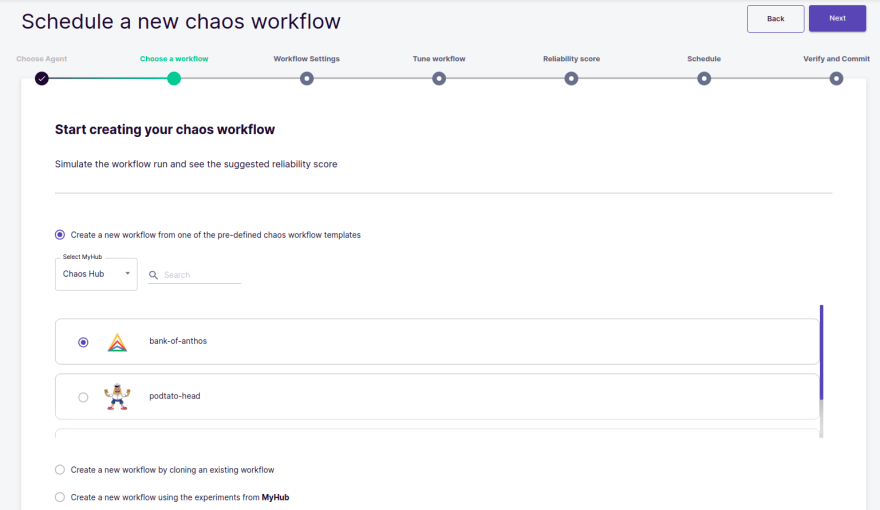
You can edit YAML and see the app deployer:
- name: install-application
container:
image: litmuschaos/litmus-app-deployer:latest
args:
- -namespace=bank
- -typeName=resilient
- -operation=apply
- -timeout=400
- -app=bank-of-anthos
- -scope=cluster
Here, in the application installation step for weak, you can change -typeName=weak that results in a single replica.
Note: Make sure you have passed the correct docker path in the ChaosEngine.
Default:
-
name: SOCKET_PATH
value: /var/run/docker.sock

- Now let's continue and schedule a workflow.
After the completion of the workflow run, we can see that there is a failure at network loss, that is probe failure due to weak application.
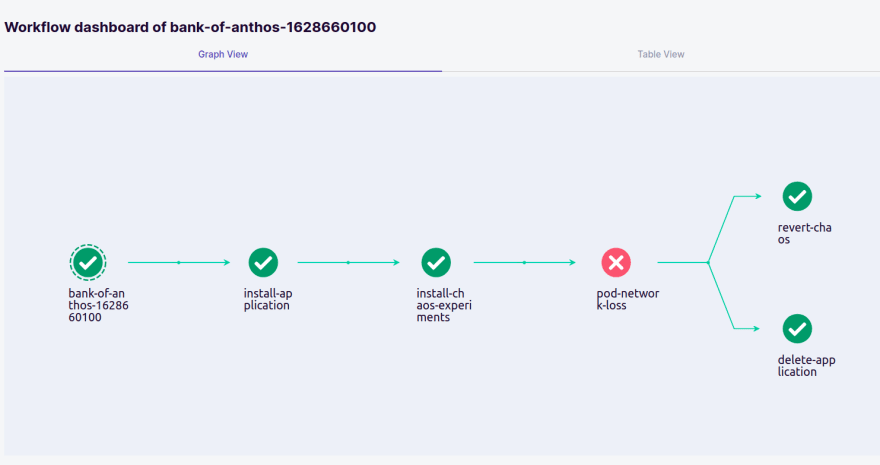
It can be cross-checked by using the UI. http://<frontend-host>:portNo
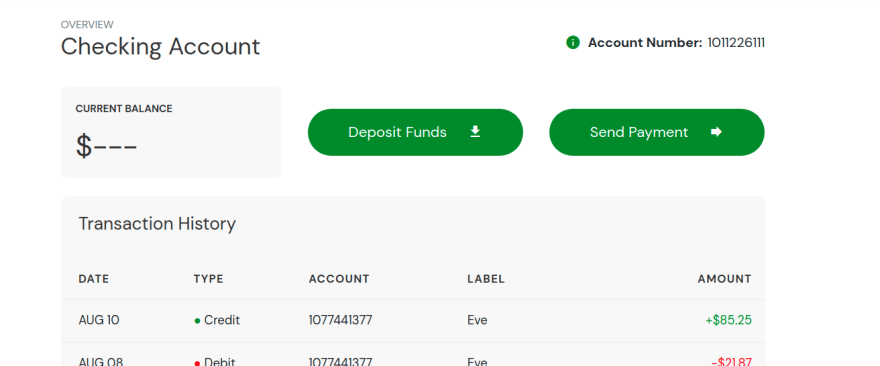
- We can see this in real-world scenarios also where we are unable to check our balance.
Now, let us schedule the workflow again using -typeName=resilient

We can see that the application has passed even after network loss. Due to the high availability of replicas, the probe has passed.

Yes, the balance is there, and you can see the logs andChaos Resultsbelow it.

You can see logs and Chaos Results below it.

Conclusion
We have briefly discussed the Bank Of Anthos resilience predefined workflow where the Bank Of Anthos application resiliency and its relationship with LitmusChaos has shown.
The workflow has been discussed in the Introduction Bank Of Anthos Resiliency Workflow. In LitmusChaos, we are continuously working and testing our experiments applications.
Among the different predefined workflows and kubernetes workflows implemented, our 3rd predefined workflow is Bank Of Anthos-Resiliency-Check, which has been elaborated with scenario effects and its causes.
Thank you for reading it till the end. I hope you had a productive time learning about LitmusChaos. Are you an SRE or a Kubernetes enthusiast? Does Chaos Engineering excite you?
Join the LitmusChaos Community Slack channel by joining the #litmus channel on the Kubernetes (https://slack.k8s.io/) Slack!
References and Links
Slack
LitmusChaos
Litmus ChaosHub
Github Repo Litmus
Connect with us on Slack
chaos-charts
Litmus Chaos YouTube Channel
Submit a pull request if you identify any necessary changes.
Do not forget to share these resources with someone you think might need help to learn/explore more about Chaos Engineering.

Top comments (1)
Opening a Swiss bank account has long been associated with financial security and discretion. If you’re considering one, Swiss bank account provides a comprehensive knowledge base on the process, benefits, and requirements. Swiss banks are known for their stability, and they offer excellent privacy protections along with multi-currency accounts. Whether you need a personal or business account, understanding compliance regulations is essential. The website breaks everything down clearly, making it much easier to navigate the complexities of Swiss banking.