
Apple introduced CoreML in WWDC 2017, and it is a great deal.
CoreML is a machine learning framework used in many Apple products, like Siri, Camera, Keyboard Dictation, etc.
It’s the foundation for Vision and Natural language processing. The cool stuff about CoreML is that it can use a pre-trained model to work offline. Apple has provided lots of pre-trained models like MobileNet, SqueezeNet, Inception v3, VGG16 to help us with image recognition tasks, especially detecting dominant objects in a scene.
The job of CoreML is simply predicting data based on the models. If the provided trained models do not suit our needs, we can train the model with our own dataset. There are frameworks like Keras, TensorFlow, Caffe or the simplified turicreate, but those requires understanding of machine learning and computer power to train the models. An easy (and costly approach) is to use cloud services, like Google Cloud Vision, IBM Watson, Microsoft Azure Cognitive Service, Amazon Rekognition, … to simplify the tasks. These services usually host the full models, and retrain them, so we just need to make HTTP requests to get information about classified objects. Some offer the ability to extend the models by allowing us to upload our data set and define classifiers.
In this guide, we will explore IBM Watson Service, especially its Visual Recognition feature to help us train a custom dataset of superheroes images, then consume the trained model in our iOS app via CoreML.
IBM Watson Service
Just recently Apple has announced partnership with IBM Watson that makes it easier to get started with machine learning.
You can build apps that leverage Watson models on iPhone and iPad, even when offline. Your apps can quickly analyze images, accurately classify visual content, and easily train models using Watson Services
So let’s try it first to see how it goes. The film Avengers Infinity War is popular on the cinema now and the superheroes still bumping around our heads. Maybe some of your friends won’t recognise those lots of superheroes in the movie. So let’s have a fun time by building an app that can help recognise superheroes.
Playing with cloud services is straightforward. We pay some money for the service, upload superheroes pictures, train on the cloud, get the trained model to the app and enjoy the magic 😎.
I’ve been reading some articles and trying IBM Cloud but somehow I still find it confusing. Mostly because it offers many services, terminology changes, deprecated beta tools, paths that lead to the same location, interchange use of services and resources, apps and projects. In this post, I will try to clear things up based on my understanding. Feedback are welcome.
**Bluemix vs IBM Cloud
**Bluemix is a cloud platform as a service which helps to build and run applications on the cloud. As of October 2017, Bluemix is IBM Cloud, although we still need to work with this domain https://console.bluemix.net. IBM Cloud offers many products, for security, analytics, storage, AI, …
IBM’s one-stop cloud computing shop provides all the cloud solutions and IBM cloud tools you need.

**Data Science and Watson Studio
**One of many products running on IBM Cloud is IBM Watson for natural language processing, visual recognition and machine learning. We will use Watson Studio to “build, train, deploy and manage AI models, and prepare and analyze data, in a single, integrated environment.” It is initially called Data Science. Think of it like a front-end web page with lots of tools for interacting with Watson services. Let’s get started!
Watson Studio is a free workspace where you can seamlessly create, evaluate, and manage your custom models.

Step 1: Sign up for IBM Cloud
Go to IBM Cloud and click on the button Sign up for IBM Cloud.

After you successfully sign up, head over to Watson Studio and click Sign in.

It will take you to https://dataplatform.ibm.com/home. I think for historical reason, the domain name and the product name doesn’t match 🙄.

Step 2: Create new project for Visual Recognition
Click New project and select the tool Visual Recognition, which is what we need to do classification on superheroes pictures.
Quickly and accurately tag, classify and train visual content using machine learning.

A project is said to contain a set of tools and services. Let’s name it Avengers. It comes with a storage.

Step 3: Create service
For me, after creating new project, it goes to the page Default Custom Model and says the project needs to associate with a service. I think the project should create a service and associate with it by default 🙄

Go back to the front page, select your Avengers project from Projects menu, and go to Settings tab.

Scroll down to Associated services **section and click Watson. In the next screen we can see there are lots of services for many purposes: Text to Speech, Speech to Text, Language Translator, Tone Analyzer, etc. In our case, we need **Visual Recognition service. For Lite plan, we can have only 1 instance of each service, if you try to add more, you will get the following warning.
Service broker error: You can only have one instance of a Lite plan per service. To create a new instance, either delete your existing Lite plan instance or select a paid plan.

The association between Watson projects, tools and services is confusing, probably because there are tons of features we haven’t used yet. Think of project as a bag of tool and service. We can only use 1 instance of each service for Lite plan, and tool is the front end we use to interact with the service.
Step 4: Remove existing service if any
To delete existing service, go back to home page, select Watson Services from Services menu. Here we can launch the tool for this service or delete it.
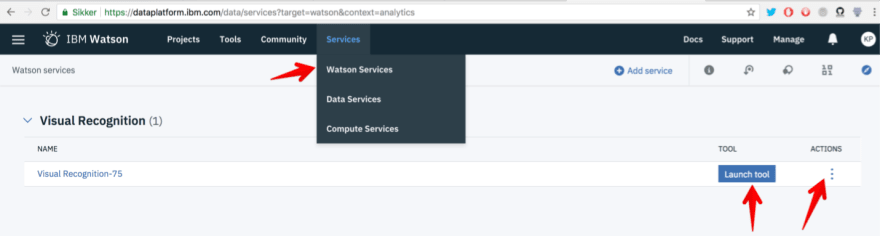
After deleting existing service, go back to step 3 to configure new instance for service Visual Recognition for this project Avengers.
Step 5: Create Visual recognition models
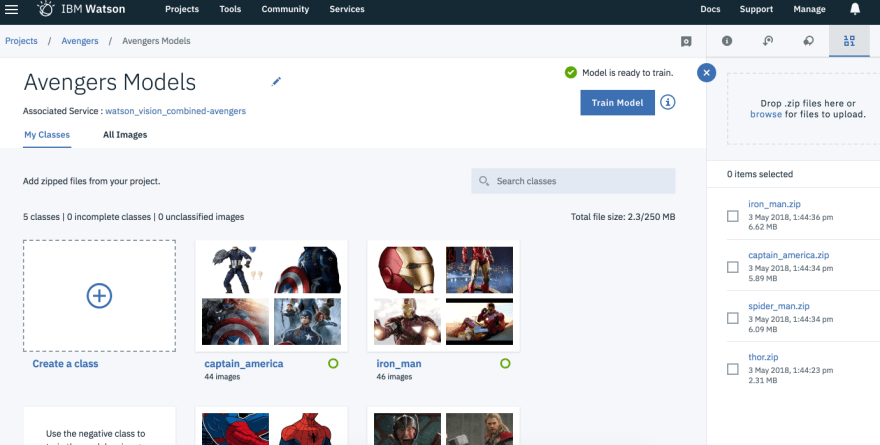
Go to your Avengers project, click Assets tab and head over to section Visual recognition models. **For the fun part of this tutorial, I will name our custom model **Avengers Models 🤘.

We can create class for each hero, or upload a zip file containing images for each hero. Note that the name of the zip file corresponds to the name of the class. The negative class is for images that do not fall into any expected classes. For this tutorial we will deal with Iron Man, Spider-Man, Captain America and Thor, because they are my favourites 😅.
The more images we upload, the more correct the model is. Also, you should use more variations of the characters, in different angles, lights. Note that we should put correct images in each folder, because garbage in is garbage out.
Select the button Find and add images on the top right to add images.
Step 6: Data set
We can download some free images from Google to use as our data set. You can get the data set on my GitHub repo, or you can prepare the data set yourself. Downloading images manually is not fun, let’s use a script. I don’t know of any good tools, but a search from Google shows this tool google-images-download. We’re lazy, let’s save time.
50 images for each hero should be good in this post. Let’s zip them and upload to Watson. After uploading finishes, add those assets to model.

Step 7: Train the model
This step requires all your remaining power to click that Train Model to start the training process. This takes some times depending on your dataset. For our dataset in this tutorial, it should take less than 10 minutes.
The reason it takes that short amount of time is because of our very small dataset. The other reason I think is because Visual Recognition uses a technique called transfer learning
Today, you can use “transfer learning” — i.e., use an existing image recognition model and retrain it with your own dataset.
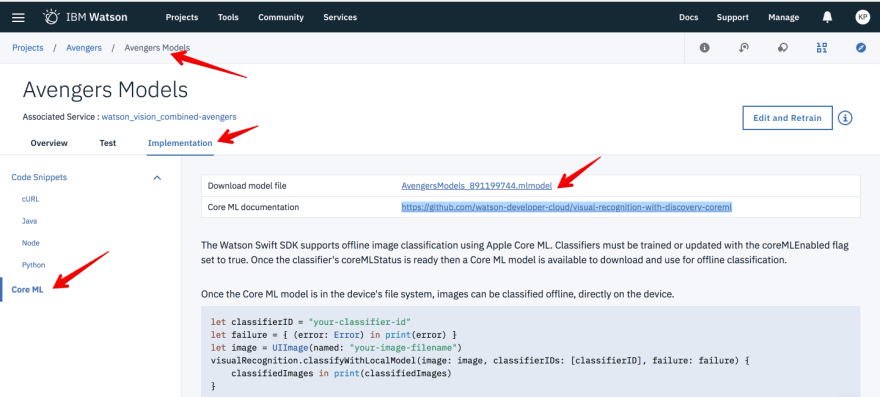
After training is complete, go to Implementation tab then select Core ML to download the CoreML compatible model. The file is 13MB.
Using CoreML model in iOS app
With the trained model from Watson, there are 2 ways to consume it in the app. The easy way is to use Watson SDK which wraps CoreML. The second way is to just use CoreML alone, and it is the approach we will show here, as it is simply to understand.
Watson SDK
If you take a closer look at the screenshot above, there’s classifierID, which is the IDof your custom model. Watson has a demo visual-recognition-coreml that shows how to use Watson SDK to ease the integration with that CoreML model. The SDK allows us to manage all downloaded models and to download updated version of the model if gets retrained with new dataset.
Just to let you know that this SDK exists, we won’t use any framework in this tutorial 😎.
Use plain CoreML model
In our guide, we just download the trained CoreML model and use it in our app. We learn the most when we don’t use any extra unnecessary frameworks. The project is on GitHub.
**Running on the simulator
**The project uses UIImagePickerController with controller.sourceType = .camera so it’s great to build on device, take some pictures and predict. You can also run it on the simulator, just remember to point sourceType to photoLibrary because there’s no camera in the simulator 😅.
Step 1: Add the model to project
The model is what we use to make prediction. We just need to drag it to the project and add it to the app target. As reading from Integrating a Core ML Model into Your App we can just use the generated class AvengersModels.
Xcode also uses information about the model’s inputs and outputs to automatically generate a custom programmatic interface to the model, which you use to interact with the model in your code.
Step 2: Vision
According to wiki:
The Vision is a fictional superhero appearing in American comic books published by Marvel Comics, an android and a member of the Avengers who first appeared in *The Avengers* #57 (October 1968)
Just kidding 😅 Vision is a framework that works with CoreML “to apply classification models to images, and to preprocess those images to make machine learning tasks easier and more reliable”.
You should definitely watch WWDC 2017 video Vision Framework: Building on Core ML to get to know some other features of this framework, like detecting faces, computing facial landmarks, tracking objects, …
With the generated AvengersModels().model we can construct Vision compatible model VNCoreMLModel and request VNCoreMLRequest, then finally send the request to VNImageRequestHandler. The code is very straightforward:
The prediction operation may take time, so it’s good habit to send it to background queue, and to update UI when we get the result.

Build and run the app. If you build it on an iPhone, take a picture of a superhero, if that is one of the 4 superheroes we have trained in this tutorial, then CoreML will be able to predict who he is based on the trained .mlmodel
Where to go from here
There are many other cool services in IBM Watson that worth exploring, like speech, text, recommendation. Below are some good links that help you get started in your machine learning journey:
Machine Learning in iOS: Azure Custom Vision and CoreML.
Machine Learning in iOS: Turi Create and CoreML.
Build unique visual recognition apps with Watson: 4 easy ways to get started: Many notes on how to utilise all the features that Visual Recognition provides.
MachineThink: Matthijs Hollemans has a lot of cool articles about CoreML and machine learning, I really enjoy it.
fantastic-machine-learning: I also curate a list of some interesting machine learning resources, preferably with Swift and CoreML.
25+ Resources for Watson Visual Recognition: contains lots of useful resources for working with Watson.
How to sharpen Watson Visual Recognition results with simple preprocessing: preparing good and accurate images is very important, this shows tips on image preprocessing.
Original post https://medium.com/flawless-app-stories/detecting-avengers-superheroes-in-your-ios-app-with-ibm-watson-and-coreml-fe38e493a4d1

Top comments (0)