
Hello, this article is an attempt to explain message queue without particular tool, but rather a big picture of what they offer without entering details of each message queue technologies like kafka, rabbitMQ, nats
What is Queue

A queue also known as FIFO ( First In First Out ) , it's a data structure that allows to operate the data in the order they have been inserted.
Example: we have 3 persons A, B and C that are waiting the store to open. First A will enter the queue so now we have person A in the queue
------------
| A
------------
then after couple of minutes person B have arrived, so now we have in the Queue two persons A and B
------------
| B A
------------
each one of them waiting for their turn, now the store opens,
the store will start taking orders of person A first because they entered first. So now we only have B in queue
------------
| B
------------
The person C have arrived and entered the queue, so the person C will wait person B to finish.
------------
| C B
------------
and so on.
With same concept in computation we can imagine the persons are tasks, or giving data we need to process in order.
This is the queue in it's simplest form, we have many queues types, like a priority queue, where each person have a priority and they are served based on their priorities.
And we have Concurrent Queues that works with multiple threads, and so on.
What is message queue
A message queue is also a concurrent data structure that hold messages, those messages can be any kind of data in addition to metadata that can help the messages system to manage the messages, like it's source and it's destination, how long the message will live and so on...
Why we need a message queue
Let's take a study case, where we have a service A that collect some articles from internet and it send them to service B, and let's assume that time of processing the article is slower than collecting it. If A keeps sending many articles to service B while service B is already processing an article, the article will be lost, so we need a kind of data persistence were we can get the article
that process this data.
A message channel acts as a temporary buffer for the receiver. Unlike the direct request-response communication style, messaging is inherently asynchronous, as sending a message doesn’t require the receiving service to be online.
Pattern of message queues
1- Point to point

Point to point is simplest form of message queuing where there is a single producer ( the service that emit the message ) and single consumer ( the service that receive the message )
2- Competing Consumers

Where there is one producer and multiple consumers, how ever only one consumer will receive the message.
3- Publish-Subscribe

the Publish-Subscribe Channel delivers a copy of the message to each consumer.
Those are not the only patterns, but it gives a brief idea on how we can use multiple queues and link them together.
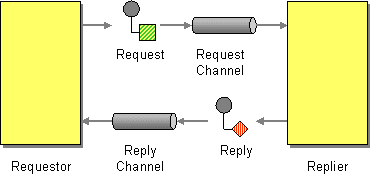
Like we can use the request-reply pattern, where producer sends the message in a channel A and the consumer reply to the consumer with another channel B.
Guaranty
Message brokers are designed to be scale horizontally, that means they are meant to be distributed.
And like any distributed system it comes with it's own challenges, and each broker take different implementation with it's tradeoffs.
For message delivery guaranty many message brokers support:
1- At-most-once delivery. This means that a message will never be delivered more than once but messages might be lost.
2- At-least-once delivery. This means that we'll never lose a message but a message might end up being delivered to a consumer more than once.
3- Exactly-once delivery. The holy grail of messaging. All messages will be delivered exactly one time.
it's impossible to achieve exactly once, because the consumer instance has to delete a message from the channel once it’s done processing it so that another instance won’t read it. If the consumer instance deletes the message before processing it, there is a risk it could crash after deleting the message but before processing it, causing the message to be lost for good. On the other hand, if the consumer instance deletes the message only after processing it, there is a risk that it crashes after processing the message but before deleting it, causing the same message to be read again later on.
Because of that, there is no such thing as exactly-once message delivery. So the best a consumer can do is to simulate exactly-once message processing by requiring messages to be idempotent and deleting them from the channel only after they have been processed.
Failures
When a consumer instance fails to process a message, the visibility timeout triggers, and the message is eventually delivered to another instance. What happens if processing a specific message consistently fails with an error, though? To guard against the message being picked up again, we need to limit the maximum number of times the same message can be read from the channel.
To enforce a maximum number of retries, the broker can stamp messages with a counter that keeps track of the number of times the message has been delivered to a consumer. If the broker doesn’t support this functionality, the consumer can implement it.
Once we have a way to count the number of times a message has been retried, we still have to decide what to do when the maximum is reached. A consumer shouldn’t delete a message without processing it, as that would cause data loss. But what it can do is remove the message from the channel after writing it to a dead letter channel — a channel that buffers messages that have been retried too many times.
This way, messages that consistently fail are not lost forever but merely put on the side so that they don’t pollute the main channel, wasting the consumer’s resources. A human can then inspect these messages to debug the failure, and once the root cause has been identified and fixed, move them back to the main channel to be reprocessed.
Backlogs
One of the main advantages of using a message broker is that it makes the system more robust to outages. This is because the producer can continue writing messages to a channel even if the consumer is temporarily unavailable. As long as the arrival rate of messages is lower than or equal to their deletion rate, everything is great. However, when that is no longer true and the consumer can’t keep up with the producer, a backlog builds up.
A messaging channel introduces a bimodal behavior in the system. In one mode, there is no backlog, and everything works as expected. In the other, a backlog builds up, and the system enters a degraded state. The issue with a backlog is that the longer it builds up, the more resources and/or time it will take.
There are several reasons for backlogs, for example:
- more producer instances come online, and/or their throughput increases, and the consumer can’t keep up with the arrival rate
- the consumers performance has degraded and messages take longer to be processed, decreasing the deletion rate
- the consumer fails to process a fraction of the messages, which are picked up again until they eventually end up in the dead letter channel. This wastes the consumer’s resources and delays the processing of healthy messages.
To detect and monitor backlogs, we can measure the average time a message waits in the channel to be read for the first time. Typically, brokers attach a timestamp of when the message was first written to it. The consumer can use that timestamp to compute how long the message has been waiting in the channel by comparing it to the timestamp taken when the message was read. Although the two timestamps have been generated by two physical clocks that aren’t perfectly synchronized, this measure generally provides a good warning sign of backlogs.
Fault isolation
A single producer instance that emits poisonous messages ( message that repeatedly fail to be processed ) can degrade the consumer and potentially create a backlog because these messages are processed multiple times before they end up in the dead-letter channel. Therefore, it’s important to find ways to deal with poisonous messages before that happens.
If messages are decorated with an identifier of the source that generated them, the consumer can treat them differently. For example, suppose messages from a specific user fail consistently. In that case, the consumer could decide to write these messages to an alternate low-priority channel and remove them from the main channel without processing them. The consumer reads from the slow channel but does so less frequently than the main channel, isolating the damage a single bad user can inflict to the others.




Top comments (0)