Git is a wonderful tool for version control and working on exciting projects, together. Its basic commands are easy to remember and most of the times, git doesn't get in our way.
We check out a new branch, start coding, and from time to time we commit. Then we push to origin, just in case something happens over the night and go home, or because we want to use our CI pipeline to get test feedback while we go and grab a coffee.
Most likely $ git log on our branch (locally and remote, we pushed a few times) now looks something like this:
commit 1e678f20f1c936b1398d685d797317e8e3d18985 (HEAD -> feature/more-hawks, origin/feature/more-hawks)
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 10:00:12 2019 +0200
Fixed code style
commit 36bbc0835bffa35a92312704e7b15793800379a5
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 09:53:57 2019 +0200
Fixed a non-stable test
commit 526f5706d2a993f305cda6653053c4e55f311569
Author: Oliver Jumpertz <you@me.com>
Date: Mon Sep 2 15:54:59 2019 +0200
Implemented a new API for hawks
commit 9221365b8db4b7338dbb5dad4d313e70d2bd491a (origin/master, master)
Author: Oliver Jumpertz <you@me.com>
Date: Mon Sep 2 13:22:10 2019 +0200
Previous master commit
At some point, whatever we worked on is finished, and it's time for the code review. We open our tool of choice and create a pull request (GitHub, Bitbucket, GitLab, etc.) or a review (in tools like Crucible) and then devote to other tasks.
After some time, our reviewers finished and provided us with a lot of useful feedback. There are some corner cases we haven't tested for, so we add in a few tests for them and adjust the implementation accordingly. We also fix some issues with the documentation and a few minor code style annoyances. When done, we commit, give it some descriptive message, and push once again.
Our workflow until now
We used git how it is supposed to be used. We're most likely working with some kind of feature branch workflow.
Whenever work on a task starts (be it a bugfix or a feature or whatever else we might call it) we create a new branch.
It's just
$ git checkout -b feature/my-feature
and we're good to go.
From time to time, we
$ git add <files-we-changed-and-added>
$ git commit
and once in a while we
$ git push
Branching is a way to isolate our own development from the development of others. In doing so, we prevent changes other people make to parts of the code base, to affect us during our development. And we do this to protect our master branch, as well. In an optimal way master always works, and can be built and deployed on demand. And other developers can branch away from it to begin work on their tasks without any trouble.
The merge
When it comes to the merge, however, we get the chance to bring all of our changes together and give them some context.
A quick reminder
A commit in git is a set of changes to a repository. Ideally, all the changes in a single commit make up exactly one bug fix or feature. And if we take it that way, a bug fix or feature should ideally be solved within a single commit. That way, everything that was done to accomplish a certain goal is linked to that one commit and described with a meaningful message, explaining what was done when and why.
Whenever the question arises why some portion of the code is as it is, $ git blame can help and give some context to better understand what we're seeing. It also helps us understand what portion of the code most likely belongs together.
(I already wrote something about commit context and the meaning of the commit message here - 7 min read, in case you are interested)
The problem
Git makes it so easy to work with it that we often tend to just do, without spending too much thought on the consequences of our workflow. Every commit becomes a part of the history of our repository.
Remember our workflow?
All those individual commits are contrary to keeping our changes together because they are split into several commits now.
There is no super easy and convenient way to see if two commits are somehow related. When we $ git blame a file and two lines each belong to different commits which were actually made for the very same task, we couldn't easily tell.
But our workflow is in fact better suited for the way we work. It's difficult to remember everything and mistakes happen. Sometimes we just forget to do something or we do not get everything right the first time. We fix it, we commit and we're good to go.
If we just merged now, all commits would find their way onto the master branch. $ git blame on a certain file, touched during development, would show each line changed still being annotated with the individual commit the change was made with.
We would have lost the ability to easily tell what belongs together.
An example
Imagine we stumbled upon some code where someone inlined a complex method within a loop. When we $ git blame the file, we only get a reference to a commit which $ git show <commit-hash> shows as this:
commit 573af7670d7bcb19c77fbf323e34fbfb536037ee
Author: Emily Awesome <emily@isawesome.com>
Date: Mon Jul 15 11:12:13 2019 +0200
Fixed code style issues.
That message doesn't tell us a whole lot. Apparently, that block of code was reformatted as the last action. The commit message is right because it correctly states what was done. But it doesn't tell us why there is so much code inlined.
What we missed is that Emily, our co-worker, actually worked on a task where she analyzed a performance degradation. What she found out was that the JIT of our runtime wasn't able to inline some parts of our code and thus she carefully fixed those parts. She made four commits in total and only her merge carries the most relevant commit message of all. That message actually states why there is code inlined and what problem it fixed how.
Note:
Most modern IDEs and editors offer to follow the git history of a file and would have enabled us to find out where those lines originated from. But it takes more time than it should.
Squash commit && merge
If we really want all our changes to be identifiable with a single commit, so that we have more information at hand, in case we need it, and without the need to ask if two lines or blocks of code actually were changed for the same feature or bugfix, we could now go for a squash commit.
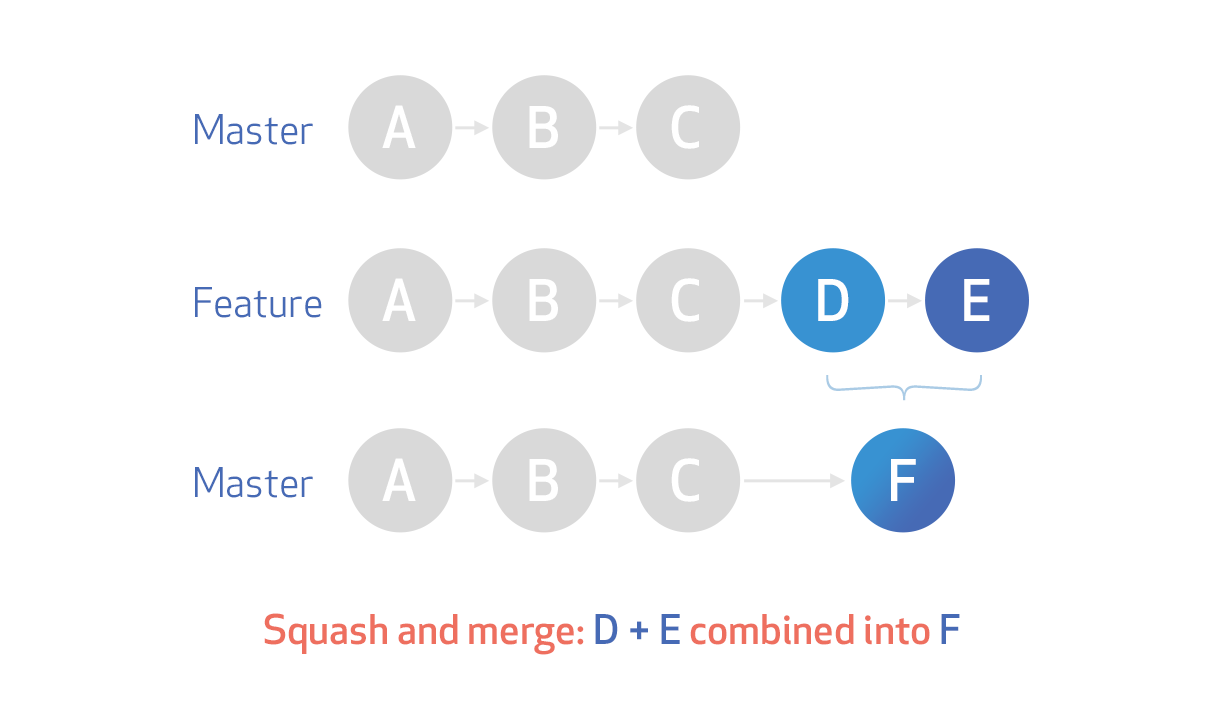
A squash commit will basically lead to all the individual commits we made being combined into one commit. That one new commit is then merged into our base branch while the commits we squashed disappear from our git history.

This image by GitHub illustrates how squash + merge works.
Pros
- From now on, all lines we touched during the development of one feature or fix are identifiable by the same commit and have the same commit message
- No need to write five or more very detailed messages for each commit just to give information, when all we want is to say what we did overall
- Our history stays clear of commits like
- "WIP commit"
- "Fixed a non-stable test"
- "Worked in review remarks"
- etc.
- Unlike
$ git commit --amend, which only works with the last commit, squashing gives more control
Cons
- We loose information about the individual commits
- And we sometimes actually want to keep that information
- Many CI tools, like Jenkins e.g., can be triggered by changes in the repository
- Builds that were triggered by commits that we later squash can not be tracked back to the specific change anymore.
- Other tools we use might be sensitive about the git history
How to squash
GitHub, Bitbucket, GitLab
Each one of these allows for the configuration of the merge strategy.
Github:
You first have to allow for squash commits
then you can actually squash and merge
Bitbucket:
You can configure and do it this way
GitLab:
Have a look here
Drawbacks
Depending on the platform used, the quality of the actual commit message after squashing may vary.
Bitbucket, for example, takes all individual commit messages and appends them to the squash commit message.
When we worked on a feature branch feature/more-hawks and now merge our branch with squash commit, the outcome looks something like what we see below:
commit 0e661e25416ff54933a5f8a6f91e800f0a98ed69 (HEAD -> master, origin/master)
Author: Oliver Jumpertz <you@me.com>
Date: Wed Sep 4 11:21:13 2019 +0200
Merge pull request #1337 in awesome-comp/awesome-api from feature/more-hawks to master
PROJ-1234: Implemented a new API for hawks.
Implemented new RESTful API - /hawks.
We should quickly establish monitoring of the new metrics, introduced with the API.
Squashed commit of the following:
commit c47010de3dd381df99c97a2c5bf4cd396e3e7fe2 (HEAD -> feature/more-hawks, origin/feature/more-hawks)
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 16:55:19 2019 +0200
Worked in review remarks
commit 1e678f20f1c936b1398d685d797317e8e3d18985
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 10:00:12 2019 +0200
Fixed code style
commit 36bbc0835bffa35a92312704e7b15793800379a5
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 09:53:57 2019 +0200
Fixed a non-stable test
commit 526f5706d2a993f305cda6653053c4e55f311569
Author: Oliver Jumpertz <you@me.com>
Date: Mon Sep 2 15:54:59 2019 +0200
Implemented a new API for hawks
Readability will suffer a little but it works and keeps our $ git log clear.
Doing it manually
If we don't like the results of the squash or if we want more control over the actual outcome, we can still squash by ourselves.
How to squash
$ git rebase --interactive (or -i) <commit-hash> enables us to squash a set of commits and get the result we desire.
<commit-hash> is the hash of the commit that is the direct predecessor of the first commit we want to include in our squash.
When we take another look at our $ git log, this is what it most likely looks like:
commit c47010de3dd381df99c97a2c5bf4cd396e3e7fe2 (HEAD -> feature/more-hawks, origin/feature/more-hawks)
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 16:55:19 2019 +0200
Worked in review remarks
commit 1e678f20f1c936b1398d685d797317e8e3d18985
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 10:00:12 2019 +0200
Fixed code style
commit 36bbc0835bffa35a92312704e7b15793800379a5
Author: Oliver Jumpertz <you@me.com>
Date: Tue Sep 3 09:53:57 2019 +0200
Fixed a non-stable test
commit 526f5706d2a993f305cda6653053c4e55f311569 (<<< here is where we want to start the squash)
Author: Oliver Jumpertz <you@me.com>
Date: Mon Sep 2 15:54:59 2019 +0200
Implemented a new API for hawks
commit 9221365b8db4b7338dbb5dad4d313e70d2bd491a (origin/master, master) (<<< this is the predecessor we want to find)
Author: Oliver Jumpertz <you@me.com>
Date: Mon Sep 2 13:22:10 2019 +0200
Previous master commit
We could also try to use tools like gitg or gitk to identify the predecessor visually, because sometimes it's difficult with $ git log.
No matter how we found the predecessor, we now provide the commit hash to $ git rebase like this:
git rebase -i 9221365b8db4b7338dbb5dad4d313e70d2bd491a
Git will then open its configured editor and provide us with a page where we can configure our squash:
pick 526f570 Implemented a new API for hawks
pick 36bbc08 Fixed a non-stable test
pick 1e678f2 Fixed code style
pick c47010d Worked in review remarks
# Rebase 9221365..c47010d onto 9221365 (4 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
# x, exec <command> = run command (the rest of the line) using shell
# b, break = stop here (continue rebase later with 'git rebase --continue')
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
# t, reset <label> = reset HEAD to a label
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# . create a merge commit using the original merge commit's
# . message (or the oneline, if no original merge commit was
# . specified). Use -c <commit> to reword the commit message.
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
We have to pick a commit that will act as a base for the squash, and then define all other commits we want to be squashed. We could also choose not to squash all commits, but this time, we want them all:
pick 526f570 Implemented a new API for hawks
squash 36bbc08 Fixed a non-stable test
squash 1e678f2 Fixed code style
squash c47010d Worked in review remarks
[omitted for readability]
We save and close the editor and have successfully made our first squash commit!
The only thing that is left for us to do is to do a force push with
$ git push --force-with-lease
Yea, exactly. We'd use the more friendly variant of $ git push --force here.
$ git push --force-with-lease has one huge advantage over using plain force: If our branch on the remote location contains more commits as those we just squashed locally (in other words, our branch was seized by someone else), it will reject to work. In the other case, it will succeed and push our changes.
A regular merge will do the job now and no repository reconfiguration is needed. We created a single context for all our changes, it just wasn't as comfortable as pressing one button. It, however, allowed for more flexibility.
Automating it further
If we don't want to identify the predecessor of our first squash commit manually every time, we can use some of git's other commands to help us automate that task.
With the following git alias (~/.gitconfig)
[alias]
find-branching-point = "!bash -c 'diff --old-line-format='' --new-line-format='' <(git rev-list --first-parent "${1:-master}") <(git rev-list --first-parent "${2:-HEAD}") | head -1'"
and by then using
$ git find-branching-point
on our branch, we'd get 9221365b8db4b7338dbb5dad4d313e70d2bd491a as the commit we were looking for.
If we now combine this and $ git rebase together within this alias:
[alias]
qbase = "!sh -c 'git rebase -i $(git find-branching-point)'"
we get a $ git qbase (qbase for quick-rebase but choose whatever you like) command, which will do the same as we've done before automatically.
Still curious?
@manuelsidler wrote a great article on how to keep your git history clean here, so pay this post a visit if you'd like to learn more!
Alternatives
Sometimes we may decide (especially in a team) that we don't want to do certain things, like squashing. That's a choice that is to be respected, but it doesn't mean that there is no way to navigate through git and its history to look for ourselves if things are related.
As we explored before, multiple commits, when working with feature branches, usually lead to a merge. This merge commit is our context. The merge hopefully contains an expressive commit message that accurately describes the pull request or merge.
It's a little trickier to find out what merge a commit was a part of, but still achievable with the following two git aliases:
find-merge = "!sh -c 'commit=$0 && branch=${1:-HEAD} && (git rev-list $commit..$branch --ancestry-path | cat -n; git rev-list $commit..$branch --first-parent | cat -n) | sort -k2 -s | uniq -f1 -d | sort -n | tail -1 | cut -f2'"
show-merge = "!sh -c 'merge=$(git find-merge $0 $1) && [ -n \"$merge\" ] && git show $merge'"
$ git find-merge <commit-hash> will return the commit with which the commit <commit-hash> was merged into the current branch.
That alone is worth a lot, since we are now able to find more information by using $ git show-merge <commit-hash> and basically get a $ git show <merge-commit-hash> in return.
(Note: If we're on another branch, we can supply a branch name as the second argument to identify the branch the commit should have been merged to)
An alternative to these aliases is git-get-merge. (Python is needed here)
$ git get-merge <commit-hash> now does the same as the aliases.
As we can now identify the merge commit one particular commit was part of, we can use that to our advantage.
Two commits were most probably created in the same context if they were merged with the same merge commit and thus originated from the same branch.
If we want to know if commit A and commit B are related, $ git find-merge should output the same merge commit hash for both.
We add the following to our git aliases:
same-origin = "!sh -c 'branch=${3:-HEAD} && mergeCommitOne=$(git find-merge $1 $branch) && mergeCommitTwo=$(git find-merge $2 $branch) && (if [[ "$mergeCommitOne" == "$mergeCommitTwo" ]]; then git show ${mergeCommitOne}; else echo "Both commits do not seem to originate from the same branch"; fi)'"
and now with $ git same-origin <commit-hash-one> <commit-hash-two> (<target-branch>) we can check if both commits originate from the same branch and then get the merge commit shown.
That takes a little more time than using the annotation features of our editors or IDEs, but it gets the job done.
Note:
We don't take into account here that two other developers might have used one feature branch as their base and then developed on two individual branches which were later merged into the feature branch, which in return was merged into master and lead to the merge commit we found. The results might just not always be accurate here.
Conclusion
Squashing commits before merging is a great way to keep the git history clean and also keep as much context as possible. This will, however, not last too far into the future, as someone will surely touch only certain parts of existing code when working on other tasks. But a clear history can help a lot when we have to navigate it.
We can still use other features of our IDEs / editors like history views of files, or advanced git commands if we need to, when too much time has passed, and too much work was done. But what we ensure by keeping a change's context in the first place is, that we proactively remove some layers of git history we may have to search through until we find what we are looking for.
Sources
- git aliases

{kind=link}
Top comments (0)