Uma métrica chave para medir o quão bem você lida com as interrupções do sistema é o tempo médio de recuperação ou MTTR (Mean Time To Recovery). É basicamente o tempo que você leva para restaurar as condições de funcionamento do sistema. Quanto mais curto o MTTR, mais rápido os problemas são resolvidos e menos impacto os usuários experimentariam e, com sorte, é mais provável que continuem a usar seu produto!
E o primeiro passo para resolver qualquer problema é saber que você tem um problema. O Tempo Médio de Descoberta (MTTD - The Mean Time to Discovery) mede a rapidez com que você detecta problemas, e você precisa de alertas para isso - muitos alertas.
Exatamente quais alertas que você precisa depende do seu aplicativo e das métricas que você está coletando. Serviços gerenciados como Lambda, SNS e SQS relatam importantes métricas do sistema para o CloudWatch por padrão. Portanto, dependendo dos serviços que você utiliza em sua arquitetura, existem alguns alertas comuns que você deve ter. E aqui estão alguns alertas que sempre procuro ter.
AWS Lambda (Alertas Regionais)
Você deve ter notado as métricas regionais (eu sei, o painel diz Account-level, embora sua própria descrição diga que está “na região AWS”) na página do painel Lambda.

Alerta regional de Concorrência
A métrica regional ConcurrentExecutions, é uma métrica importante para ter um alerta. Defina o limite de alerta para ~80% do seu limite de concorrência regional atual (que começa em 1000 para a maioria das regiões).

Dessa forma, você será alertado quando o uso do Lambda estiver se aproximando do limite atual para que possa solicitar um aumento de limite antes que as funções sejam throttled.
Alerta regional de throttling
Você também pode adicionar alertas regionais a métricas Throttles. Mas isso depende se você está usando ou não Reserved Concurrency. Reserved Concurrency é a quantidade de concorrência que uma função pode usar e o excesso de invocações mostra que throttling está fazendo seu trabalho. Mas esses throttlings também podem acionar seu alerta com falsos positivos.
AWS Lambda (Alertas por função)
(Observação: dependendo do acionador da função, alguns desses alertas podem não ser aplicáveis.)
Alerta de taxa de erro
Use a métrica matemática do CloudWatch para calcular a taxa de erro de uma função - ou seja 100 * Errors / MAX([Errors, Invocations]). Alinhe o limite de alerta com seus acordos de nível de serviço (SLAs). Por exemplo, se seu SLA afirma que 99% das solicitações devem ser bem-sucedidas, defina o alerta de taxa de erro para 1%.
Alerta de throttle
A menos que você esteja usando Reserved Concurrency, provavelmente não deve esperar que as invocações de funções sejam throttled. Portanto, você deve ter um alerta contra a métrica Throttles.
Alerta DeadLetterErrors
Para funções assíncronas com uma fila de devoluções (DLQ - dead letter queue), você deve configurar um alerta em relação a métrica DeadLetterErrors. Isso informa quando o serviço Lambda não é capaz de encaminhar eventos com falha para o DLQ configurado.
Alerta DestinationDeliveryFailures
Semelhante ao anterior, para funções com Destinos Lambda (Lambda Destinations), você deve configurar um alerta em relação a métrica DestinationDeliveryFailures. Isso informa quando o serviço Lambda não pode encaminhar eventos para o destino configurado.
Alerta IteratorAge
Para funções acionadas por streams do Kinesis ou DynamoDB, a métrica IteratorAge informa a idade das mensagens que eles recebem. Quando essa métrica começa a aumentar, é um indicador de que a função não está acompanhando a taxa de novas mensagens e está ficando para trás. O pior cenário é que você terá perda de dados, já que os dados nos fluxos são mantidos por apenas 24 horas por padrão. É por isso que você deve configurar um alerta em relação à IteratorAgemétrica para que possa detectar e retificar a situação antes que piore.
Como Lumigo pode ajudar
Mesmo que você saiba quais alertas você deve ter, ainda assim é necessário muito esforço para configurá-los. É aqui que ferramentas de terceiros, como o Lumigo, também podem agregar muito valor. Por exemplo, o Lumigo permite uma série de alertas integrados (usando padrões sensíveis e reconhecidos pelo setor) para funções rastreadas automaticamente para que você não precise configurá-las manualmente. Mas você ainda tem a opção de desabilitar alertas para funções individuais, caso deseje.
Aqui estão alguns dos alertas que a Lumigo oferece:
- Predições (Predictions) - quando as funções Lambda estão perigosamente perto dos seus limites de recursos (memória / duração / simultaneidade, etc.)
- Atividade anormal detectada - invocações (aumento / diminuição), erros, custo, etc. Veja abaixo um exemplo.
- Relatório sob demanda de recursos configurados incorretamente (DLQs ausentes, modo de taxa de transferência do DynamoDB incorreto, etc.)
- Limite excedido - memória, erros, inicializações a frio, etc.
- Falha de tempo de execução do Lambda
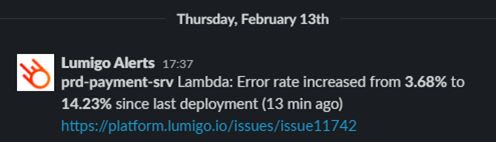
Além disso, a Lumigo se integra a várias plataformas de mensagens populares para que você seja alertado por meio do seu canal favorito.
Ah, e a Lumigo não cobra extra para alertas . Você paga apenas pelos rastreamentos que é enviado para o Lumigo, e ela tem um nível gratuito para até 150.000 invocações rastreadas por mês. Você pode se inscrever para uma conta Lumigo gratuita aqui .
API Gateway
Por padrão, o API Gateway agrega métricas para todos os seus endereços. Por exemplo, você terá uma métrica 5xxError para toda a API, portanto, quando houver um pico nos erros 5xx, você não terá ideia de qual endereço era o problema.
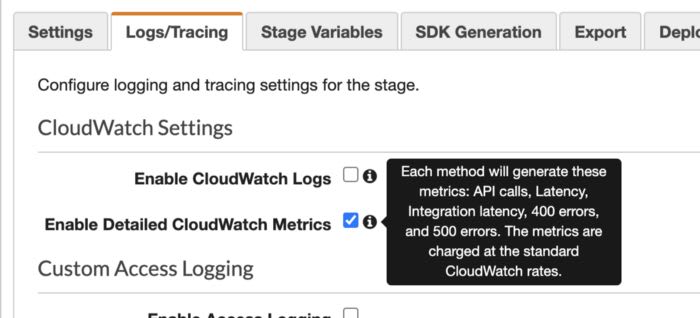
Você precisa configurar Enable Detailed CloudWatch Metrics nas configurações de estágio (stages) de suas APIs para dizer ao API Gateway para gerar métricas ao nível de métodos. Isso aumenta o custo do CloudWatch, mas sem eles, você terá dificuldade em depurar problemas que acontecem em produção.
Depois de ter as métricas definidas por método à mão, você pode configurar alertas para métodos individuais.
Alerta de latência p90 / p95 / p99
Quando se trata de monitorar a latência, nunca use a Média. “Média” é apenas um valor estatístico, por si só, é quase sem sentido . Até que plotemos a distribuição de latência, não entenderemos realmente como nossos usuários estão experimentando nosso sistema. Por exemplo, todos esses gráficos produzem a mesma média, mas têm uma distribuição muito diferente de como nossos usuários experimentaram o sistema.
Sério, sempre use percentis (percentiles).
Portanto, ao configurar alertas de latência para métodos individuais, tenha duas coisas em mente:
- Use a métrica
Latencyao invés deIntegrationLatency.IntegrationLatencymede o tempo de resposta do alvo da integração (por exemplo, Lambda), mas não inclui nenhuma sobrecarga que o API Gateway adiciona. Ao medir a latência da API, você deve medir a latência o mais próximo possível do cliente. - Use o 90º, 95º ou 99º percentils. Ou talvez use todos os 3, mas defina níveis de limite diferentes para eles. Por exemplo, latência p90 em 1 segundo, latência p95 em 2 segundos e latência p99 em 5 segundos.
Alertas de taxa 4xx / 5xx
Ao usar a estatística média para as métrica API Gateway 4XXError e 5XXError, você obtém a taxa de erro correspondente. Configure alertas nessas métricas para alertá-lo de errors inesperados.
SQS
Ao trabalhar com SQS, você deve configurar alertas na métrica ApproximateAgeOfOldestMessage para uma fila SQS. Ele informa a idade da mensagem mais antiga na fila. Quando essa métrica aumenta, significa que a função SQS não é capaz de acompanhar a taxa de novas mensagens.
Step Functions
Existem várias métricas sobre as quais você deve criar alertas:
-
ExecutionThrottled -
ExecutionsAborted -
ExecutionsFailed -
ExecutionsTimedOut
Eles representam as várias maneiras pelas quais as execuções da máquina de estado falhariam. E como as Step Functions costumam ser usadas para modelar fluxos de trabalho essenciais para os negócios, normalmente eu definiria o limite de alerta para 1.
Eu posso codificar tudo isso?
Sim você pode!
Aqui na Lumigo, publicamos um projeto de código aberto chamado cloudwatch-alarms-macro para fazer exatamente isso. É uma macro que permite definir os padrões da organização para alerta de limites e gerar alertas para recursos que você tem em sua stack CloudFormation.
A maneira mais rápida de começar é implantar a macro em sua conta da AWS por meio do Serverless Application Repository aqui. Depois disso, você pode seguir os exemplos para configurar seus limites padrões e substituir em sua stack.
Obtenha uma conta Lumigo gratuita e configure alertas instantaneamente: Inscreva-se no Lumigo.
Créditos
- What alerts should you have for serverless applications?, escrito originalmente por Yan Cui.

Top comments (0)