
Um guia de 19 padrões mostrando o poder do AWS Serverless
Sou um grande fã de construir micro-serviços com sistemas serverless. O serverless nos dá o poder de nos concentrar apenas no código e nos nossos dados sem nos preocuparmos com a manutenção e configuração dos recursos de computação abaixo disso. Os provedores de serviços na nuvem (como a AWS) também nos fornecem um grande número de serviços gerenciados que podemos juntar para criar micro-serviços serverless incrivelmente poderosos e massivamente escaláveis.
Eu li muitos posts que mencionam micro-serviços serverless, mas eles geralmente não entram em muitos detalhes. Eu sinto que isso pode deixar as pessoas confusas e dificultar a implementação de suas próprias soluções. Como trabalho com micro-serviços serverless o tempo todo, imaginei que compilar uma lista de padrões de design e como implementá-los na AWS, seria algo interessante para a comunidade. Abaixo descrevo 19 deles, embora tenha certeza de que há muito mais!
Nesta postagem, veremos todos os 19 em detalhes, para que você possa usá-los como modelos para começar a projetar seus próprios micro-serviços serverless.
Table de Conteúdo
- Padrão 01: O Serviço Web Simples
- Padrão 02: Webhook Escalável
- Padrão 03: O Porteiro
- Padrão 04: A API Interna
- Padrão 05: A Entrega Interna
- Padrão 06: O Agregador
- Padrão 07: O Notificador
- Padrão 08: O FIFOer
- Padrão 09: O “Eles dizem que eu sou um streamer” ou Fluxo Contínuo
- Padrão 10: O Estrangulador
- Padrão 11: A Máquina de Estado
- Padrão 12: O Roteador
- Padrão 13: A API Robusta
- Padrão 14: O Consumidor Simples
- Padrão 15: O Mecanismo de Relatórios de Leitura Pesada
- Padrão 16: O Fan-Out/Fan-In
- Padrão 17: O Eventualmente Consistente
- Padrão 18: A Invocação Distribuída
- Padrão 19: O Disjuntor
Uma palavra rápida sobre comunicação entre micro-serviços
Antes de entrarmos no tema, quero ter certeza de que estamos claros sobre a importante distinção entre comunicação síncrona e assíncrona . Eu escrevi um post sobre Misturando funções Lambda VPC e Não-VPC para Micro-Serviços de Alto Desempenho que entra em mais detalhes sobre os tipos de comunicação, consistência eventual e outros tópicos de micro-serviços. Pode valer a pena ler se você não estiver familiarizado com essas coisas. Aqui está uma rápida recapitulação dos tipos de comunicação:
Comunicação Síncrona
Serviços de Comunicação Síncrona podem ser invocados por outros serviços e devem aguardar uma resposta. Isso é considerado uma solicitação de bloqueio, porque o serviço de chamada não pode concluir a execução até que uma resposta seja recebida.
Comunicação Assíncrona
Esta é uma solicitação sem bloqueio. Um serviço pode invocar (ou acionar) outro serviço diretamente ou pode usar outro tipo de canal de comunicação para enfileirar informações. Normalmente, o serviço só precisa aguardar a confirmação (ack) de que a solicitação foi enviada.
Ótimo! Agora que estamos claros sobre isso, vamos direto aos padrões!
Padrões de Micro-Serviço Serverless
Os 19 padrões a seguir representam vários designs comuns de micro-serviço que estão sendo usados pelos desenvolvedores na AWS. A grande maioria, eu usei na produção, mas todos eles são formas válidas (na minha opinião) para construir micro-serviços serverless. Alguns deles têm nomes legítimos que as pessoas cunharam ao longo dos anos. Se o padrão era altamente familiar e eu sabia o nome, usei o nome real. Em muitos desses casos, no entanto, eu tive que me divertir um pouco inventar alguns!
Para maior clareza e consistência, os diagramas de todos abaixo usam os mesmos símbolos para representar a comunicação entre os componentes:
- Uma grande seta preta representa uma solicitação assíncrona.
- As duas setas pretas menores representam uma solicitação síncrona.
- Setas vermelhas indicam erros.
Faça bom proveito! 😁
01: O Serviço Web Simples
Esse é o mais básico dos padrões que você provavelmente verá em aplicativos serverless. O Serviço Web Simples é o front de uma função Lambda com um API Gateway. Mostrei o DynamoDB como o banco de dados aqui porque ele se adapta bem aos recursos de alta simultaneidade das Lambdas.

Padrão 01: O Serviço Web Simples
02: Webhook Escalável
Se você estiver criando um webhook, o tráfego pode ser imprevisível. Isso é bom para o Lambda, mas se você estiver usando um back-end "menos escalável" como o RDS, você pode se deparar com alguns gargalos. Existem maneiras de gerenciar isso, mas agora que o Lambda suporta invocações SQS, podemos limitar nossas cargas de trabalho enfileirando as solicitações e, em seguida, usando uma função Lambda limitada (throttled) e de baixa concorrência para trabalhar em nossa fila. Na maioria das situações, sua taxa de transferência deve estar próxima do tempo real. Se houver alguma carga pesada por um período de tempo, você poderá experimentar alguns pequenos atrasos, pois a Lambda limitada (throttled) levará um tempo maior para processar as mensagens. As invocações do SQS para as funções da Lambda agora funcionam corretamente com a limitação (throttled), portanto, não é mais necessário gerenciar sua própria política de redrive (mais sobre redrive policy no AWS SQS).

Padrão 02: Webhook Escalável
03: O Porteiro
Esta é uma variação do padrão O Serviço Web Simples. Usando as "Lambda Autorizadoras" (Lambda Authorizers) do API Gateway, você pode conectar uma função do Lambda que processa o cabeçalho Authorization e retorna uma política do IAM. O API Gateway usa essa política para determinar se ela é válida para o recurso e encaminha a solicitação ou a rejeita. O API Gateway armazena em cache a política do IAM, portanto você também pode classificá-la como o padrão "Chave de Valet". Como eu indico no diagrama abaixo, as "Lambda Autorizadoras" são micro-serviços independentes. Seu "Serviço de Autorização" pode ter várias interfaces para adicionar/remover usuários, atualizar permissões e assim por diante.
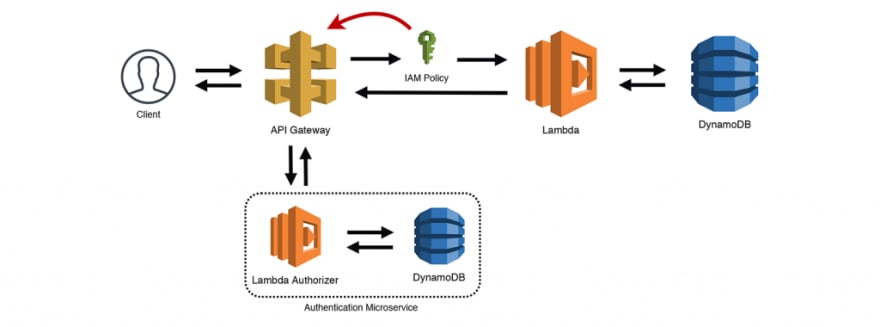
Padrão 03: Autorizador/Chave de Valet
04: A API Interna
O padrão A API Interna é essencialmente um serviço da web sem um frontend no API Gateway. Se você estiver criando um micro-serviço que só precisa ser acessado a partir de sua infraestrutura da AWS, é possível usar o AWS SDK e acessar diretamente a API HTTP da Lambda. Se você usar um InvocationType do RequestResponse, irá realizar uma requisição de invocação síncrona para a função Lambda de destino, chamando seu script (ou função) e aguardando por uma resposta. Algumas pessoas dizem que funções chamando outras funções é um anti-padrão, mas eu discordo. Chamadas HTTP de dentro de micro-serviços são uma prática padrão (e frequentemente necessária). Independentemente de você estar chamando o DynamoDB (baseado em http), uma API externa (baseada em http) ou outro micro-serviço interno (baseado em http), seu serviço provavelmente terá de aguardar que os dados de resposta HTTP sejam resolvidos.

Padrão 04: A API Interna
05: A Entrega Interna
Assim como A API Interna, o padrão A Entrega Interna usa o SDK da AWS para acessar a API HTTP da Lambda. No entanto, neste cenário, estamos usando um InvocationType do tipo Event, que desconecta o publicador assim que receber um ack indicando que o pedido foi enviado com sucesso. A função Lambda agora está recebendo um evento assíncrono, portanto, utilizará automaticamente o mecanismo de repetição integrado (política de *redrive*). Isso significa duas coisas:
1 - É possível que o evento seja processado mais de uma vez, então devemos ter certeza de que nossos eventos são idempotentes.
2 - Já que nos desconectamos de nossa função de chamada, precisamos ter certeza de capturar falhas para que possamos analisá-las e potencialmente reproduzi-las.
Anexar uma Fila de Devoluções Mortas (Dead Letter Queue) (DLQ) a funções Lambda assíncronas é sempre uma boa ideia. Eu gosto de usar uma fila SQS e monitorar o tamanho da fila com o CloudWatch Metrics. Dessa forma, posso obter um alerta se a fila de falhas atingir um determinado limite.

Padrão 05: A Entrega Interna
06: O Agregador
Falando de chamadas API internas, O Agregador é outro padrão comum de micro-serviço. A função Lambda no diagrama abaixo faz três chamadas síncronas para três micro-serviços separados. Supomos que cada micro-serviço usa algo como o padrão A API Interna e retornaria dados ao chamador. Os micro-serviços abaixo também podem ser serviços externos , como APIs de terceiros. A função Lambda agrega todas as respostas e retorna uma resposta combinada ao cliente no outro lado do API Gateway.

Padrão 06: O Agregador
07: O Notificador
Eu tive esse debate com muitas pessoas, mas eu considero um tópico do SNS (Simple Notification Service) como seu próprio padrão de micro-serviço. Um atributo importante dos micro-serviços é ter uma "API bem definida" para que outros serviços e sistemas se comuniquem com eles. O SNS (e também o SQS e o Kinesis) têm APIs padronizadas acessíveis por meio do AWS SDK. Se o micro-serviço for para uso interno, um tópico autônomo do SNS contribui para um micro-serviço extremamente útil. Por exemplo, se você tiver vários serviços de faturamento (um para produtos, um para assinaturas e outro para serviços), é altamente provável que vários serviços precisem ser notificados quando um novo registro de faturamento for gerado. Os serviços mencionados acima podem postar um evento no serviço "Notificador de Faturamento" que distribui o evento aos serviços assinados. Queremos manter nossos micro-serviços desacoplados, portanto, os serviços dependentes (como um serviço de faturamento, um serviço de processamento de pagamentos etc.) são responsáveis por assinar o serviço "Faturamento Notificador" por conta própria. À medida que são adicionados novos serviços que precisam desses dados, eles também podem se inscrever.

Padrão 07: O Notificador
08: O FIFOer
Vamos aumentar um pouco a complexidade. O suporte para invocações do SQS para Lambdas é incrível, mas infelizmente não funciona com filas SQS FIFO (first in, first out, o primeiro que entra, é o primeiro que sai). Isso faz sentido, uma vez que as invocações são destinadas a processar mensagens em paralelo, não uma de cada vez. No entanto, podemos construir um consumidor FIFO serverless com uma pequena ajuda das Regras do CloudWatch e das configurações de simultaneidade do Lambda. No diagrama abaixo, temos um cliente que está enviando mensagens para uma fila FIFO. Como não podemos acionar nosso consumidor automaticamente, adicionamos uma regra CloudWatch (também conhecida como crontab) que invoca nossa função (de forma assíncrona) em minutos. Nós definimos a simultaneidade da nossa função Lambda para 1, de modo que não estamos tentando executar solicitações concorrentes em paralelo. A função pesquisa a fila para (até 10) mensagens ordenadas e faz o processamento necessário, por exemplo, gravar os dados em uma tabela do DynamoDB.
Depois de concluirmos nosso processamento, a função remove as mensagens da fila e, em seguida, invoca a si mesma novamente (de forma assíncrona) usando o SDK da AWS para acessar a API HTTP do Lambda com o tipo de chamada Event. Esse processo será repetido até que todos os itens tenham sido removidos da fila. Sim, isso tem um efeito cascata, e eu não sou um grande fã de usar isso para qualquer outra finalidade, mas funciona muito bem nesse cenário. Se a função Lambda estiver ocupada processando um conjunto de mensagens, a regra do CloudWatch falhará devido à configuração de simultaneidade do Lambda. Se a auto-invocação for bloqueada por qualquer motivo, a nova tentativa continuará a cascata. Na pior das hipóteses, o processamento é interrompido e, em seguida, é iniciado novamente pela regra CloudWatch.
Se a mensagem estiver com defeito ou causar um erro de processamento, lembre-se de colocá-las em uma fila de devoluções (DLQ) para uma inspeção mais detalhada com a capacidade de reproduzi-las.

Padrão 08: O FIFOer
09: O "Eles dizem que eu sou um streamer" ou Fluxo Contínuo
Outro padrão um tanto complexo é o processador de fluxo contínuo. Isso é muito útil para capturar fluxos de cliques, dados da IoT, etc. No cenário abaixo, estou usando o API Gateway como um proxy do Kinesis. Isso usa o tipo de integração "AWS Service" fornecido pelo API Gateway (saiba mais aqui). Você poderia usar qualquer número de serviços para enviar dados para um fluxo do Kinesis, então este é apenas um exemplo. O Kinesis distribuirá dados para os shards que configurarmos e, em seguida, podemos usar o Kinesis Firehose para agregar os dados ao S3 e carregá-los em massa no Redshift. Existem outras maneiras de conseguir isso, mas, surpreendentemente, isso vai acabar sendo mais barato quando você chegar a níveis mais altos de escala (vs SNS, por exemplo).

Padrão 09: O "Eles dizem que eu sou um streamer" ou Fluxo Contínuo
10: O Estrangulador
O Estrangulador é outro padrão popular que permite incrementalmente substituir partes de um aplicativo por serviços novos ou atualizados. Normalmente, você criaria uma espécie de "Estrangulador de Fachada" para rotear suas solicitações, mas o API Gateway pode realmente fazer isso para nós usando os tipos de integração "AWS Service" e "HTTP". Por exemplo, uma API existente (com um Elastic Load Balancer) pode ser roteada através do API Gateway usando uma integração "HTTP". Você pode ter todas as solicitações padrão para sua API legada e direcionar rotas específicas para o novo serviço serverless à medida que você quiser.

Padrão 10: O Estrangulador
11: A Máquina de Estado
Geralmente, as arquiteturas serverless precisarão fornecer algum tipo de orquestração. O AWS Step Functions é, sem dúvida, a melhor maneira de lidar com a orquestração em seus aplicativos AWS Serverless. Se você não estiver familiarizado com as Step Functions, confira esses dois projetos de exemplos na documentação da AWS. As State Machines são ótimas para coordenar várias tarefas e garantir que sejam concluídas adequadamente, implementando novas tentativas (retry), delay e esperas e rollbacks. No entanto, elas são exclusivamente assíncronas, o que significa que você não pode esperar pelo resultado de uma Step Function e responder a uma solicitação síncrona.
A AWS defende o uso de Step Functions para orquestrar fluxos de trabalho inteiros, ou seja, coordenar vários micro-serviços. Eu acho que isso funciona para certos padrões assíncronos, mas definitivamente não funcionará para serviços que precisam fornecer uma resposta síncrona aos clientes. Pessoalmente, gosto de encapsular funções de etapa dentro de um micro-serviços, reduzindo a complexidade do código e adicionando resiliência, mas ainda mantendo meus serviços desacoplados.

Padrão 11: A Máquina de Estado
12: O Roteador
O padrão A Máquina de Estado é poderoso porque nos fornece ferramentas simples para gerenciar a complexidade, o paralelismo, o tratamento de erros e muito mais. No entanto, as Step Functions não são gratuitas e você provavelmente acumulará algumas contas enormes se usá-las para tudo. Para orquestrações menos complexas em que estamos menos preocupados com as transições de estado, podemos manipulá-las usando o padrão O Roteador.
No exemplo abaixo, uma chamada assíncrona para uma função Lambda está determinando qual tipo de tarefa deve ser usado para processar a solicitação. Esse é essencialmente uma declaração switch glorificada, mas também poderia acrescentar algum contexto adicional e enriquecimento de dados, se necessário. Observe que a função principal do Lambda está apenas invocando uma das três tarefas possíveis aqui. Como mencionei antes, Lambdas assíncronas deveria ter uma DLQ para armazenar as chamadas que falharam, possibilitando replays, incluindo as três Lambdas de "Tipo de Tarefa" abaixo. As tarefas, então, realizam seus trabalhos (o que quer que seja). Aqui estamos simplesmente escrevendo para tabelas do DynamoDB.

Padrão 12: O Roteador
13: A API Robusta
O padrão O Roteador funciona muito bem quando os clientes não sabem dividir as solicitações em endpoints separados. No entanto, muitas vezes o cliente saberá como fazer isso, como no caso de uma API REST. Usando o API Gateway e sua capacidade de rotear solicitações com base em métodos e endpoints, podemos permitir que o cliente decida com qual serviço de "back-end" ele deseja interagir. O exemplo abaixo usa uma solicitação síncrona de um cliente, mas isso seria tão eficiente quanto as solicitações assíncronas.
Embora isso seja um pouco semelhante ao padrão O Serviço Web Simples, considero esse padrão como A API Robusta, já que estamos adicionando mais complexidade ao interagir com serviços adicionais em nosso aplicativo no geral. É possível, conforme ilustrado abaixo, que várias funções possam compartilhar a mesma origem de dados, funções poderiam fazer chamadas assíncronas para outros serviços e funções poderiam fazer chamadas síncronas para outros serviços ou APIs externas e exigir uma resposta. Também é importante observar que, se criarmos serviços usando o padrão A API Interna, poderemos expô-los ao público usando o API Gateway.
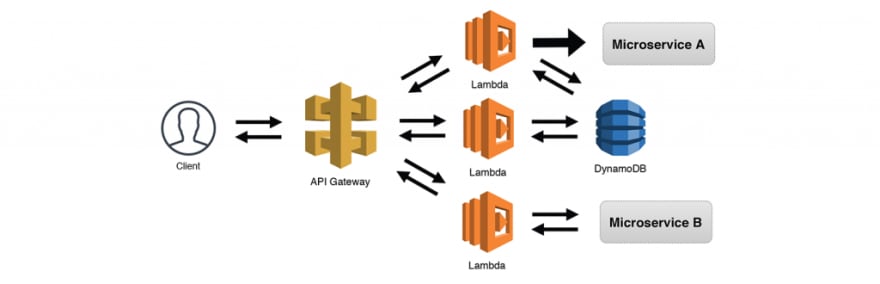
Padrão 13: A API Robusta
14: O Consumidor Simples
Já mencionamos os SQS Triggers e como eles nos permitem filtrar solicitações para serviços "menos escaláveis" como o RDS. O Consumidor Simples é essencialmente o padrão Webhook Escalável sem o API Gateway e o pré-processamento da função Lambda. Eu considero isso um padrão separado, uma vez que poderia existir como um serviço autônomo. Assim como com o SNS, o SQS tem uma API bem definida, acessível por meio do AWS SDK. Vários serviços podem postar mensagens diretamente na fila e fazer com que a função Lambda processe suas solicitações. As invocações do SQS para as funções Lambda agora funcionam corretamente com a limitação (throttled), portanto, não é mais necessário gerenciar sua própria política de redrive (mais sobre redrive policy no AWS SQS).

Padrão 14: O Consumidor Simples
15: O Mecanismo de Relatórios de Leitura Pesada
Assim como existem limitações RECEBENDO dados em um serviço "menos-escalável" como RDS, pode haver limitações para a SAÍDA de dados também. A Amazon fez algumas coisas incríveis nesse espaço com o Aurora Read Replicas e o Aurora Serverless, mas, infelizmente, atingir o limite max_connections ainda é muito possível, especialmente com aplicativos com requisitos pesados de LEITURA. O cache é uma estratégia testada e verdadeira para atenuar as LEITURAS, que pode ser implementado como parte de vários padrões que descrevi neste artigo. O exemplo abaixo lança um cluster Elasticache (que pode manipular dezenas de milhares de conexões) na frente do nosso cluster RDS. Os principais pontos aqui são para garantir que os TTLs (time-to-live) sejam definidos adequadamente, a invalidação de cache é incluída (talvez como uma assinatura de outro serviço) e as novas conexões RDS são feitas somente se os dados não forem armazenados em cache.
Nota: O Elasticache não fala diretamente com o RDS, eu estava simplesmente tentando deixar a camada de cache clara. Tecnicamente, uma função Lambda precisaria se comunicar com os dois serviços.

Padrão 15: 15: O Mecanismo de Relatórios de Leitura Pesada
16: O Fan-Out/Fan-In
Este é outro ótimo padrão, especialmente para trabalhos em lote. As funções do Lambda são limitadas a 15 minutos do tempo total de execução, portanto, grandes tarefas de ETL (extract, transform and load) e outros processos que consomem muito tempo podem facilmente exceder essa limitação. Para contornar isso, podemos usar uma única função Lambda para dividir nosso grande trabalho em uma série de tarefas menores. Isso pode ser feito chamando um "Trabalhador" (Worker) Lambda para cada trabalho menor usando o tipo Event para desconectar a função de chamada. Isso é conhecido como "fan-out", já que estamos distribuindo a carga de trabalho.
Em alguns casos, espalhar nosso trabalho pode ser tudo o que precisamos fazer. No entanto, às vezes precisamos agregar os resultados desses trabalhos menores. Uma vez que as Lambdas Trabalhadoras são todas desligadas da nossa invocação original, nós teremos que "fan-in" nossos resultados para um local comum. Isso é realmente mais fácil do que parece. Cada trabalhador simplesmente precisa gravar em uma tabela do DynamoDB com o identificador principal da tarefa, seu identificador de sub-tarefa e os resultados de seu trabalho. Como alternativa, cada trabalho poderia gravar na mesma pasta no S3 e os dados poderiam ser agregados a partir daí. Não esqueça seus DLQs das Lambdas, para pegar as invocações que falharam.

Padrão 16: O Fan-Out/Fan-In
17: O Eventualmente Consistente
Micro-serviços dependem do conceito de "consistência eventual" para replicar dados em outros serviços. O pequeno atraso é geralmente imperceptível para os usuários finais, já que a replicação geralmente acontece rapidamente. Pense em quando você altera sua foto do perfil do Twitter e leva alguns segundos para que ela seja atualizada no cabeçalho. Os dados precisam ser replicados e o cache precisa ser limpo. Usar os mesmos dados para diferentes propósitos em micro-serviços muitas vezes significa que temos que armazenar os mesmos dados mais de uma vez.
No exemplo abaixo, estamos persistindo dados para uma tabela do DynamoDB chamando algum endpoint roteado para uma função Lambda por nosso API Gateway. Para nossos propósitos de API frontend, uma solução NoSQL funciona bem. No entanto, também queremos usar uma cópia desses dados em nosso sistema de relatórios e precisaremos fazer algumas junções, tornando o banco de dados relacional a melhor escolha. Podemos configurar outra função Lambda que assina o Stream da tabela do DynamoDB, que acionará eventos sempre que os dados forem adicionados ou alterados.
Os fluxos do DynamoDB funcionam como o Kinesis, portanto os lotes serão repetidos várias vezes (e ficarão em ordem). Isso significa que podemos limitar nossa função Lambda para garantir que não sobrecarregaremos nossa instância do RDS. Certifique-se de gerenciar seu próprio DLQ para armazenar atualizações inválidas e inclua um campo last_updated com todas as alterações de registro. Você pode usar isso para limitar sua consulta SQL e garantir que você tenha a versão mais recente.
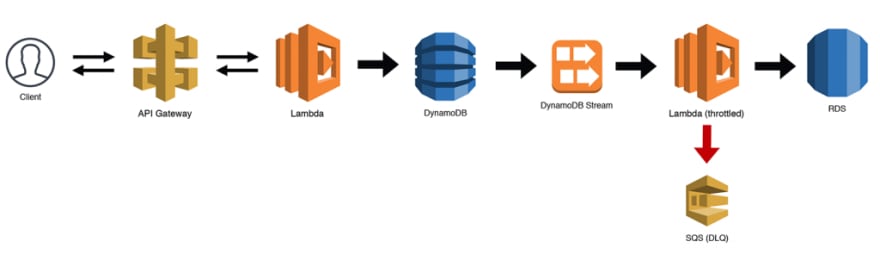
Padrão 17: O Eventualmente Consistente
18: A Invocação Distribuída
O tópico autônomo do SNS (também conhecido como o padrão O Notificador) que eu mencionei antes é extremamente poderoso, dada a sua capacidade de servir vários mestres. No entanto, o acoplamento de um tópico do SNS diretamente a um micro-serviço também tem seus benefícios. Se o tópico realmente tiver uma única finalidade e precisar receber apenas mensagens de seu próprio micro-serviço, o padrão A Invocação Distribuída descrito abaixo funcionará muito bem.
Estamos usando o CloudWatch Logs como exemplo aqui, mas tecnicamente poderia usar qualquer tipo de evento que fosse suportado. Os eventos acionam nossa função Lambda (que tem nossa DLQ anexada) e, em seguida, envia o evento para um tópico do SNS. No diagrama abaixo, mostro três micro-serviços com buffers SQS sendo notificados. No entanto, as assinaturas do tópico do SNS seriam de responsabilidade individuais dos micro-serviços.
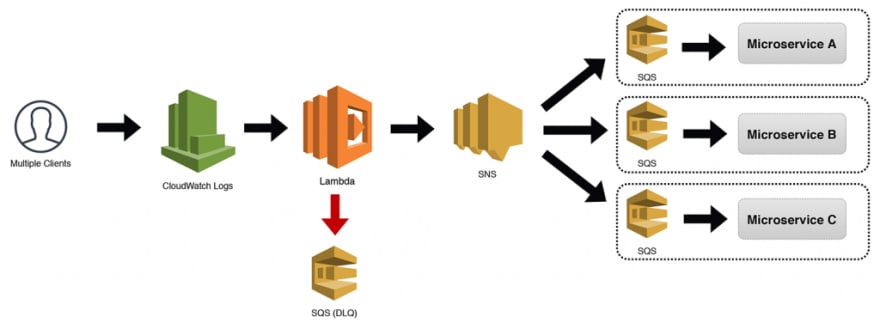
Padrão 18: A Invocação Distribuída
19: O Disjuntor
Eu guardei o melhor pro final! Esse é um dos meus padrões favoritos, pois estou usando muitas APIs de terceiros em meus aplicativos serverless. O padrão O Disjuntor controla o número de chamadas de API com falha (ou lentidão) feitas usando algum tipo de máquina de estado. Para nossos propósitos, estamos usando um cluster Elasticache para persistir as informações (mas o DynamoDB também pode ser usado se você quiser evitar VPCs).
Veja como isso funciona. Quando o número de falhas atinge um certo limite, "abrimos" o circuito e enviamos imediatamente erros de volta ao cliente que o chamou, sem sequer tentar chamar a API. Após um curto tempo de espera, nós "abrimos parcialmente" o circuito, enviando apenas algumas solicitações para ver se a API está finalmente respondendo corretamente. Todas as outras solicitações recebem um erro. Se as solicitações de amostra forem bem-sucedidas, "fechamos" o circuito e começamos a liberar todo o tráfego. No entanto, se algumas ou todas essas solicitações falharem, o circuito será aberto novamente e o processo será repetido com algum algoritmo para aumentar o tempo limite entre as tentativas de repetição "semi-abertas".
Esse é um padrão incrivelmente poderoso (e econômico) para qualquer tipo de solicitação síncrona. Você está acumulando cobranças sempre que uma função Lambda está em execução e aguardando a conclusão de outra tarefa. Permitir que seus sistemas se identifiquem automaticamente com problemas como esse, fornecendo um recuo incremental e que, em seguida, faça a auto-recuperação quando o serviço voltar a ficar on-line, fazendo com que você se sinta um super-herói!
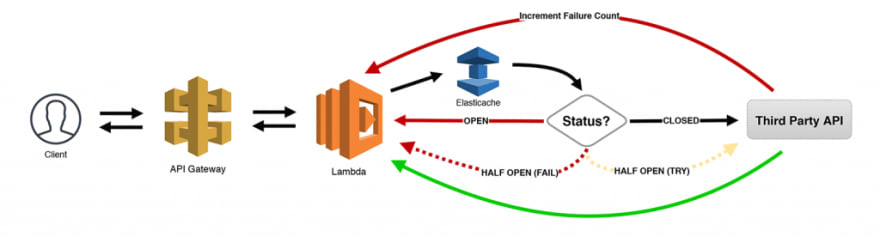
Padrão 19: O Disjuntor
Para onde vamos daqui?
Os 19 padrões que identifiquei acima devem ser um bom ponto de partida para você ao projetar seus micro-serviços serverless. O melhor conselho que posso dar é pensar muito sobre o que cada micro-serviço realmente precisa fazer, quais dados ele precisa e com quais outros serviços ele precisa interagir. É tentador construir muitos micro-serviços pequenos quando você teria ficado melhor com apenas alguns.
Assim como o termo "serverless", não há uma definição formal e acordada do que um "micro-serviço" realmente consiste. No entanto, os micro-serviços serverless devem, pelo menos, aderir aos seguintes padrões:
- Os serviços devem ter seus próprios dados privados. Se o seu micro-serviço estiver compartilhando um banco de dados com outro serviço, separe/replique os dados ou combine os serviços. Se nada disso funcionar para você, repense sua estratégia e arquitetura.
- Os serviços devem ser implantáveis independentemente. Os micro-serviços (especialmente os serverless) devem ser completamente independentes e auto-contidos. É bom que eles sejam dependentes de outros serviços ou que outros dependam deles, mas essas dependências devem ser inteiramente baseadas em canais de comunicação bem definidos entre eles.
- Utilize a consistência eventual. A replicação de dados e a desnormalização são princípios fundamentais dentro das arquiteturas de micro-serviços. Só porque o Serviço A precisa de alguns dados do Serviço B, não significa que eles devam ser combinados. Os dados podem ter interface em tempo real por meio de comunicação síncrona, se possível, ou podem ser replicados entre os serviços. Respirem fundo pessoal do banco de dados relacional, isso é ok de se fazer.
- Use cargas de trabalho assíncronas sempre que possível. AWS Lambda cobra por cada 100ms de tempo de processamento usado. Se você está esperando por outros processos para concluir, você está pagando para que suas funções esperem. Isso pode ser necessário para muitos casos de uso, mas, se possível, entregue suas tarefas e deixe-as executar em segundo plano. Para orquestrações mais complicadas, use Step Functions.
- Mantenha os serviços pequenos, mas valiosos. É possível ir muito pequeno, mas também é provável que você seja grande demais. Sua arquitetura de "micro-serviços" não deve ser uma coleção de pequenos "monolíticos" que lidam com componentes de aplicativos grandes. Não há problema em ter algumas funções, tabelas de banco de dados e filas como parte de um único micro-serviço. Se você puder limitar o tamanho, mas ainda assim fornecer valor comercial suficiente, provavelmente estará onde precisa estar.
Boa sorte e divirta-se construindo seus micro-serviços serverless. Há algum padrão que você está usando e gostaria de compartilhar? Existem nomes legítimos para alguns desses padrões em vez daqueles que acabei de inventar? Deixe um comentário ou fale comigo no Twitter para me avisar.
Créditos ⭐️
- Serverless Microservice Patterns for AWS, escrito originalmente por Jeremy Daly





Top comments (0)