
Eu me tornei um grande defensor do DynamoDB nos últimos anos. O DynamoDB oferece muitos benefícios que outros bancos de dados não oferecem, como um modelo de preço flexível, um modelo de conexão sem estado que funciona perfeitamente com computação serverless e tempo de resposta consistente, mesmo quando o banco de dados aumenta para um tamanho enorme.
No entanto, a modelagem de dados com o DynamoDB é complicada para aqueles acostumados aos bancos de dados relacionais que dominaram nossa área nas últimas décadas. Existem várias peculiaridades em torno da modelagem de dados com o DynamoDB, mas a maior delas é a recomendação da AWS de usar uma única tabela para todos os seus registros.
Neste post, aprofundaremos os conceitos por trás do design de tabela única. Você vai aprender:
- O que é design de tabela única
- Por que o design de tabela única é necessário
- As desvantagens do design de tabela única
- As duas vezes em que as desvantagens do design de tabela única superam os benefícios
Recentemente, fiz um debate ao vivo sobre esse assunto no Twitch com Rick Houlihan e Edin Zulich. Confira a gravação aqui. Rick é mais firme no campo de tabela única, por isso não deixe de assistir também.
Vamos começar!
O que é design de tabela única
Antes de irmos longe demais, vamos definir o conceito de design de tabela única. Para isso, faremos uma rápida viagem pelo histórico dos bancos de dados. Examinaremos algumas modelagens básicas em bancos de dados relacionais e depois veremos por que você precisa modelar de forma diferente no DynamoDB. Com isso, veremos o principal motivo do uso do design de tabela única.
No final desta seção, também examinaremos rapidamente alguns outros benefícios menores do design de tabela única.
Informações básicas sobre modelagem e junções SQL
Vamos começar com o nosso bom amigo, o banco de dados relacional.
Com bancos de dados relacionais, você normalmente normaliza seus dados criando uma tabela para cada tipo de entidade em seu aplicativo. Por exemplo, se você estiver criando um aplicativo de comércio eletrônico, terá uma tabela para Clientes e uma tabela para Pedidos.

Cada pedido pertence a um determinado cliente e você usa chaves estrangeiras para se referir a um registro em uma tabela a um registro em outra. Essas chaves estrangeiras atuam como ponteiros - se eu precisar de mais informações sobre um Cliente que fez um pedido específico, posso seguir a referência de chave estrangeira para recuperar itens sobre o Cliente.

Para seguir esses ponteiros, a linguagem SQL, para consultar banco de dados relacionais, tem o conceito de junções (JOIN). As junções permitem combinar registros de duas ou mais tabelas no tempo de leitura.
O problema de falta de junções no DynamoDB
Embora conveniente, as junções SQL também são caras. Elas exigem a varredura de grandes porções de várias tabelas no banco de dados relacional, a comparação de valores diferentes e o retorno de um conjunto de resultados.
O DynamoDB foi desenvolvido para casos de uso enormes e de alta velocidade, como o carrinho de compras da Amazon.com. Esses casos de uso não podem tolerar a inconsistência e o desempenho lento das junções à medida que um conjunto de dados é escalado.
O DynamoDB se guarda muito bem de operações que não irão escalar e não há uma ótima maneira de escalar junções relacionais. Ao invés de trabalhar para melhorar a escala das junções, o DynamoDB evita o problema, removendo a capacidade de usar junções.
Mas como desenvolvedor de aplicativos, você ainda precisa de alguns dos benefícios das junções relacionais. E um dos grandes benefícios das junções é a capacidade de obter vários itens heterogêneos do seu banco de dados em uma única solicitação.
No exemplo acima, queremos obter um registro do cliente e todos os pedidos do cliente. Muitos desenvolvedores aplicam padrões de design relacional com o DynamoDB, mesmo que eles não tenham as ferramentas relacionais, como a operação de junção. Isso significa que eles colocam seus itens em tabelas diferentes, de acordo com o tipo. No entanto, como não há junções no DynamoDB, eles precisam fazer várias solicitações em série para buscar os registros Pedidos e Cliente.

Isso pode se tornar um grande problema em seu aplicativo. O I/O de rede é provavelmente a parte mais lenta do seu aplicativo e você está fazendo várias solicitações de rede em cascata, onde uma solicitação fornece dados que são usados para solicitações subsequentes. À medida que o aplicativo é escalado, esse padrão fica cada vez mais lento.
A solução: pré-junte seus dados nas coleções de itens
Então, como você obtém um desempenho rápido e consistente do DynamoDB sem fazer várias solicitações ao seu banco de dados? Pré-juntando seus dados usando coleções de itens.
Uma coleção de itens no DynamoDB refere-se a todos os itens em uma tabela ou índice que compartilham uma chave de partição. No exemplo abaixo, temos uma tabela do DynamoDB que contém atores e os filmes nos quais eles foram exibidos. A chave primária é uma chave primária composta em que a chave da partição é o nome do ator e a chave de classificação é o nome do filme.

Você pode ver que existem dois itens para Tom Hanks - Cast Away e Toy Story. Como eles têm a mesma chave de partição Tom Hanks, eles estão na mesma coleção de itens.
Você pode usar a operação Query da API do DynamoDB para ler vários itens com a mesma chave de partição. Portanto, se você precisar recuperar vários itens heterogêneos em uma única solicitação, organize esses itens para que eles estejam na mesma coleção de itens.
Vejamos um exemplo da minha palestra sobre modelagem de dados do DynamoDB na AWS re:Invent 2019. Este exemplo usa um aplicativo de comércio eletrônico como discutimos, que envolve usuários e pedidos. Temos um padrão de acesso no qual queremos buscar o registro do usuário e os registros do pedido. Para tornar isso possível em uma única solicitação, garantimos que todos os registros de pedidos estejam na mesma coleção de itens que o registro de usuário ao qual eles pertencem.

Agora, quando queremos buscar o usuário e os pedidos, podemos fazer isso em uma única solicitação sem precisar de uma operação custosa de junção:

É disso que se trata o design de tabela única - ajustando sua tabela para que seus padrões de acesso possam ser tratados com o menor número possível de solicitações ao DynamoDB, idealmente uma.
E como tudo fica melhor em citações sofisticadas, digamos mais uma vez:
O principal motivo para usar tabela única no DynamoDB é recuperar vários tipos de itens heterogêneos usando uma única solicitação.
Outros benefícios do design de tabela única
Embora a redução do número de solicitações de um padrão de acesso seja o principal motivo para o uso de um design de tabela única com o DynamoDB, também existem outros benefícios. Vou discutir isso brevemente.
Primeiro, há alguma sobrecarga operacional em cada tabela que você possui no DynamoDB. Embora o DynamoDB seja totalmente gerenciado e muito prático em comparação com um banco de dados relacional, você ainda precisa configurar alarmes, monitorar métricas etc. Se você tiver uma tabela com todos os itens ao invés de oito tabelas separadas, você reduz o número de alarmes e métricas a serem observados.
Segundo, ter uma única tabela pode economizar dinheiro em comparação a ter várias tavelas. Com cada tabela que você possui, é necessário provisionar unidades de capacidade de leitura e gravação. Freqüentemente, você fará algumas contas na ponta do lápis para ver o tráfego que você espera, aumentará em X% e os converterá em RCUs e WCUs. Se você tiver um ou dois tipos de entidade em sua tabela única que são acessados com muito mais frequência do que os outros, você poderá alocar parte da capacidade extra de itens acessados com menos frequência no buffer para os outros itens.
Embora esses dois benefícios sejam reais, eles são bastante marginais. A responsabilidade das operações no DynamoDB é bastante baixo e os preços economizarão apenas um pouco de dinheiro nas margens. Além disso, se você estiver usando o DynamoDB On-Demand, você não vai poupar dinheiro indo a um projeto multi-tabela.
Em geral, ao pensar no design de tabela única, você deve considerar o principal benefício como a melhoria do desempenho, fazendo uma única solicitação para recuperar todos os itens necessários.
Desvantagens de um design de tabela única
Embora o padrão de tabela única seja poderoso e ridiculamente escalável, ele não vem sem custos. Nesta seção, analisaremos algumas das desvantagens de um design de tabela única.
Na minha opinião, há três desvantagens do design de tabela única no DynamoDB:
- A curva de aprendizado íngreme para entender o design de tabela única;
- A inflexibilidade de adicionar novos padrões de acesso;
- A dificuldade de exportar suas tabelas para análise.
Vamos revisar cada um deles por vez.
A curva de aprendizado íngreme do design de tabela única
A maior reclamação que recebo dos membros da comunidade é a dificuldade de aprender o design de tabela única no DynamoDB.
Uma única tabela do DynamoDB sobrecarregada parece realmente estranha em comparação com as tabelas limpas e normalizadas do seu banco de dados relacional. É difícil desaprender todas as lições que você aprendeu ao longo de anos de modelagem de dados relacionais.
Para aqueles que estão evitando o design de tabela única devido à curva de aprendizado, minha resposta é a seguinte:
Seja resistente.
O desenvolvimento de software é uma jornada contínua de aprendizado, e você não pode usar a dificuldade de aprender coisas novas como uma desculpa para usar mal uma coisa nova.
Mais adiante neste artigo, descreverei algumas vezes quando não há problema em não usar o design de tabela única. No entanto, você deve entender absolutamente os princípios por trás do design de tabela única antes de tomar essa decisão. A ignorância não é uma razão para evitar as melhores práticas.
A inflexibilidade de novos padrões de acesso
Uma segunda reclamação sobre o DynamoDB é a dificuldade de acomodar novos padrões de acesso em um design de tabela única. Esta reclamação tem muito mais validade.
Ao modelar um design de tabela única no DynamoDB, você começa primeiro com seus padrões de acesso. Pense bem (e anote!) Como você acessará seus dados e modele cuidadosamente sua tabela para satisfazer esses padrões de acesso. Ao fazer isso, você organizará seus itens em coleções para que cada padrão de acesso possa ser tratado com o menor número possível de solicitações - idealmente, uma única solicitação.
Depois de modelar sua tabela, você a coloca em ação e escreve o código para implementá-la. E, feito corretamente, isso funcionará muito bem! Seu aplicativo poderá escalar infinitamente, sem degradação no desempenho.
No entanto, o design da sua tabela é estritamente adaptado para a finalidade exata para a qual foi projetado. Se seus padrões de acesso mudarem porque você está adicionando novos objetos ou acessando vários objetos de maneiras diferentes, pode ser necessário executar um processo ETL (Extract, Transform, Load) para varrer todos os itens da sua tabela e atualizar com novos atributos. Esse processo não é impossível, mas adiciona atrito ao seu processo de desenvolvimento.
A dificuldade da análise
O DynamoDB foi projetado para casos de uso OLTP - acesso a dados com alta rapidez e alta velocidade, onde você está operando em alguns registros por vez. Mas os usuários também precisam de padrões de acesso OLAP - consultas grandes e analíticas em todo o conjunto de dados para encontrar itens populares, número de pedidos por dia ou outras informações.
O DynamoDB não é bom em consultas OLAP. Isso é intencional. O DynamoDB se concentra em ter um desempenho super alto nas consultas OLTP e deseja que você use outros bancos de dados criados especificamente para OLAP. Para fazer isso, você precisará enviar seus dados do DynamoDB em outro sistema.
Se você tiver um design de tabela única, colocá-lo no formato adequado para um sistema de análise pode ser complicado. Você desnormalizou seus dados e os transformou em um pretzel projetado para lidar com seus casos de uso exatos. Agora você precisa desenrolar essa tabela e normalizá-la novamente para que seja útil para análises.
Minha citação favorita sobre isso vem da excelente explicação de Forrest Brazeal sobre o design de tabela única:
Uma tabela única e otimizada do DynamoDB parece mais com código de máquina do que com uma simples planilha
As planilhas são fáceis para análise, enquanto um design de tabela única exige algum trabalho para desenrolar. O trabalho de infraestrutura de dados precisará ser aprimorado em seu processo de desenvolvimento para garantir que você possa reconstituir sua tabela de maneira amigável para análise.
Quando não usar o design de tabela única
Até agora, conhecemos os prós e os contras do design de tabela única no DynamoDB. Agora é hora de chegar à parte mais controversa - quando, se houver, você não deve usar o design de tabela única no DynamoDB?
Em um nível básico, a resposta é "sempre que os benefícios não superam os custos". Mas essa resposta genérica não nos ajuda muito. A resposta mais concreta é "sempre que eu precisar de flexibilidade de consulta e / ou análises mais fáceis ao invés do desempenho rápido e impressionante". E acho que há duas ocasiões em que isso é mais provável:
- em novas aplicações onde a agilidade do desenvolvedor é mais importante que o desempenho da aplicação;
- em aplicativos usando o GraphQL.
Exploraremos cada um deles abaixo. Mas primeiro quero enfatizar que essas são exceções, não orientações gerais. Ao modelar com o DynamoDB, você deve seguir as práticas recomendadas. Isso inclui desnormalização, design de tabela única e outros princípios adequados de modelagem NoSQL. E mesmo se você optar por um design de várias tabelas, você deve entender o design de uma única tabela para saber por que não é adequado para o seu aplicativo específico.
Novos aplicativos que priorizam a flexibilidade
Nos últimos anos, muitas startups e empresas estão optando por construir uma computação serverless como o AWS Lambda para seus aplicativos. Existem vários benefícios para o modelo serverless, desde a facilidade de implantação, a escala indolor de infraestrutura e o modelo de preços de pagamento por uso.
Muitos desses aplicativos usam o DynamoDB como banco de dados devido à forma como ele se encaixa perfeitamente no modelo serverless. Desde o provisionamento, o preço, as permissões e o modelo de conexão, o DynamoDB é perfeito para aplicativos serverless, enquanto os bancos de dados relacionais tradicionais são mais problemáticos.
No entanto, é importante lembrar que, embora o DynamoDB funcione bem com serverless, ele não foi criado para serverless.
O DynamoDB foi desenvolvido para aplicativos de larga escala e alta velocidade que estavam superando os recursos dos bancos de dados relacionais. E os bancos de dados relacionais podem escalar muito longe! Se você estiver na situação em que está escalando um banco de dados relacional, provavelmente terá uma boa noção dos padrões de acesso necessários. Mas se você estiver criando um aplicativo greenfield em uma startup, é improvável que você exija os recursos de alto escala do DynamoDB no início, e talvez você não saiba como seu aplicativo evoluirá com o tempo.
Nessa situação, você pode decidir que as características de desempenho de um design de tabela única não valem a perda de flexibilidade e análises mais difíceis. Você pode optar por uma abordagem Faux-SQL em que use o DynamoDB, mas de maneira relacional, normalizando seus dados em várias tabelas.
Isso significa que você pode precisar fazer várias chamadas seriais para o DynamoDB para satisfazer seus padrões de acesso. Seu aplicativo pode ter a seguinte aparência:

Observe como existem duas solicitações separadas para o DynamoDB. Primeiro, há uma solicitação para buscar o usuário, depois há uma solicitação de acompanhamento para buscar os pedidos para o usuário em questão. Como várias solicitações devem ser feitas e essas solicitações devem ser feitas em série, haverá um tempo de resposta mais lento para os clientes do seu aplicativo de back-end.
Para alguns casos de uso, isso pode ser aceitável. Nem todos os aplicativos precisam ter tempos de resposta inferiores a 30 ms. Se seu aplicativo for bom com tempos de resposta de 100 ms, a flexibilidade aumentada e a análise mais fácil para casos de uso em estágio inicial podem valer o desempenho mais lento.
GraphQL e design de tabela única
O segundo lugar em que você pode evitar o design de tabela única com o DynamoDB está em aplicativos GraphQL.
Antes de você falar "Bem, na verdade...", quero esclarecer que sim, sei que o GraphQL é um mecanismo de execução, e não uma linguagem de consulta para um banco de dados específico. E sim, eu sei que o GraphQL é independente de banco de dados.
Meu argumento não é que você não possa usar um design de tabela única com o GraphQL. Estou dizendo que, devido à maneira como a execução do GraphQL funciona, você está perdendo a maioria dos benefícios de um design de tabela única e, ao mesmo tempo, herdando todos os custos.
Para entender o porquê, vamos dar uma olhada em como o GraphQL funciona e um dos principais problemas que ele pretende solucionar.
Nos últimos anos, muitos aplicativos optaram por uma API baseada em REST no back-end e um aplicativo de página única no front-end. Pode ter a seguinte aparência:

Em uma API baseada em REST, você tem recursos diferentes que geralmente são mapeados para uma entidade em seu aplicativo, como Usuários ou Pedidos. Você pode executar operações semelhantes a CRUD nesses recursos usando diferentes verbos HTTP para indicar a operação que deseja executar.
Uma fonte comum de frustração para os desenvolvedores de front-end ao usar APIs baseadas em REST é que eles podem precisar fazer várias solicitações para diferentes endpoints para buscar todos os dados de uma determinada página:
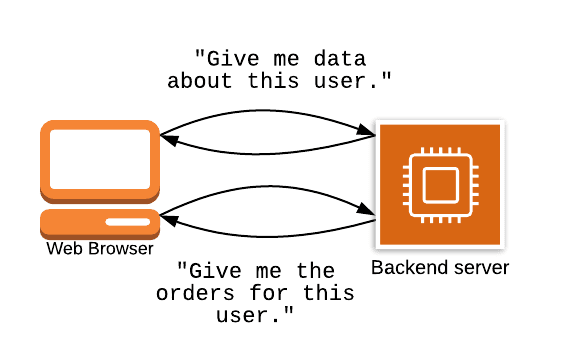
No exemplo acima, o cliente precisa fazer duas solicitações - uma para obter o usuário e outra para obter os pedidos mais recentes para um usuário.
Com o GraphQL, você pode buscar todos os dados necessários para uma página em uma única solicitação. Por exemplo, você pode ter uma consulta GraphQL com a seguinte aparência:
query { User( id:112233 ){
firstName
lastName
addresses
orders {
orderDate
amount
status
}
}
}
No bloco acima, estamos fazendo uma consulta para buscar o usuário com o ID 112233, buscando alguns atributos sobre o usuário (incluindo nome, sobrenome e endereços), bem como todos os pedidos desse usuário.
Agora, nosso fluxo é o seguinte:

O navegador da web faz uma única solicitação ao nosso servidor back-end. O conteúdo dessa solicitação será a nossa consulta GraphQL, como mostrado abaixo do servidor. A implementação do GraphQL irá analisar a consulta e lidar com ela.
Parece uma vitória - nosso cliente está fazendo apenas uma solicitação ao back-end! Viva!
De certa forma, isso reflete nossa discussão anterior sobre por que você deseja usar o design de tabela única com o DynamoDB. Queremos fazer apenas uma solicitação ao DynamoDB para buscar itens heterogêneos, assim como o front-end deseja fazer uma única solicitação ao back-end para buscar recursos heterogêneos. Isso soa como uma combinação feita no céu!
O problema está em como o GraphQL lida com esses recursos no back-end. Cada campo em cada tipo no seu esquema GraphQL é tratado por um resolver. Este resolver entende como preencher os dados para o campo.
Para tipos diferentes em sua consulta, como User e Order em nosso exemplo, você normalmente teria um resolver que faria uma solicitação de banco de dados para resolver o valor. O resolver receberia alguns argumentos para indicar quais instâncias desse tipo deveriam ser buscadas e, em seguida, o resolver buscará e retornará os dados.
O problema é que os resolvers são essencialmente independentes um do outro. No exemplo acima, o resolver raiz executaria primeiro para encontrar o usuário com o ID 112233. Isso envolveria uma consulta ao banco de dados. Então, quando esses dados estiverem disponíveis, eles serão passados para o resolver de pedidos, a fim de buscar os pedidos relevantes para este usuário. Isso faria solicitações subsequentes ao banco de dados para resolver essas entidades.
Agora nosso fluxo fica assim:

Nesse fluxo, nosso back-end está fazendo várias solicitações seriais ao DynamoDB para cumprir nosso padrão de acesso. É exatamente isso que estamos tentando evitar com o design de tabela única!
Nada disso diz que você não pode usar o DynamoDB com o GraphQL - você absolutamente pode. Eu acho que é um desperdício gastar tempo em um design de tabela única ao usar o GraphQL com o DynamoDB. Como as entidades do GraphQL são resolvidas separadamente, acho que é bom modelar cada entidade em uma tabela separada. Isso permitirá mais flexibilidade e facilitará o processo de análise no futuro.
Conclusão
Neste post, revisamos o conceito de design de tabela única no DynamoDB. Primeiro, passamos por um histórico de como o NoSQL e o DynamoDB evoluíram e por que o design de tabela única é necessário.
Segundo, analisamos algumas desvantagens do design de tabela única no DynamoDB. Especificamente, vimos como o design de tabela única pode dificultar a evolução de seus padrões de acesso e complicar o trabalho de análise.
Por fim, analisamos duas situações em que os benefícios do design de mesa única no DynamoDB podem não compensar os custos. A primeira situação está em aplicativos novos e de rápida evolução usando computação serverless, onde a agilidade do desenvolvedor é fundamental. A segunda situação é ao usar o GraphQL devido à maneira como o fluxo de execução do GraphQL funciona.
Ainda sou um forte defensor do design de tabela única no DynamoDB na maioria dos casos de uso. E mesmo que você não ache adequado para sua situação, ainda acho que você deve aprender e entender o design de tabela única antes de optar por não participar. Os princípios básicos de design NoSQL o ajudarão, mesmo que você não siga as práticas recomendadas para design em larga escala.
Se você tiver perguntas ou comentários sobre este artigo, sinta-se à vontade para deixar um comentário abaixo ou me envie um email diretamente.
Créditos
- The What, Why, and When of Single-Table Design with DynamoDB, escrito originalmente por Alex DeBrie.





Top comments (0)