We often can provide assets with a URI or a so-called “Data URL” on the web. As they are so straightforward to use, they get pretty often copied (from a tutorial, snippet, or whatnot) without us being able to tell what they do, when to prefer them, or whether you should still be using them altogether. It's one of the lesser-known performance tweaks I will shed some light on in this blog post.
This post was reviewed by Leon Brocard & David Lorenz. Thank you! ❤️
What are Data URLs Anyway
First things first, what are we talking about here? Let's make a simple example of a background image:
<div></div>
div {
height: 100px;
width: 100px;
background-image: url('https://placehold.co/600x400');
}
That snippet is quite simple. We add a div and configure it to hold a background image. You might know that there is a second approach to this, however. This approach makes use of a so-called “data URL”:
div {
height: 100px;
width: 100px;
background-image: url('data:image/svg+xml;charset=utf-8;base64,PHN2ZyB4bWxucz0iaHR0cDovL(...)TEwLjRaIi8+PC9zdmc+');
}
Now, that is different. The two snippets output the same result. However, in the latter, we provide the image data directly in the CSS instead of requesting it from a server. Here, we provide the encoded image binary data directly in a given convention. There is no need to catch it from the server, as we provide the file in CSS.
A new URL scheme, “data”, is defined. It allows inclusion of small data items as “immediate” data, as if it had been included externally.
Base64 Encoding
How does this work? The image data is encoded with an algorithm called “Base64”. It sounds a bit complicated, but it's, in fact, not. The main goal of such encodings is to display binary data in Unicode. That's why such are called “binary to text encodings.” A digit in Base64 can represent a maximum of 6 bits. Why is that? Let's make an example. We want to display 101101 as text. But hold on a second. Did you recognize something? We already did it! Writing out 101101 made a bit-sequence apparent to you as a reader. _We encoded binary to text._Now, let's imagine instead of “0” and “1”, we decide for “A” and “B”: BABBAB. Guess what? We have just Base 2 encoded data! Yay. Do you see the issue here? We must utilize eight bytes of data to encode six bits of data, as A and B in ASCII take up one byte. We “inflate” or bloat this data by ~1067% (100 % / 6 bit * 64 bit).
| Binary Sequence | Base2 Encoded |
|---|---|
| 0 | A |
| 1 | B |
| 101101 | BABBAB |
To tackle this problem, there is a little trick: we add more characters to encode a bigger binary sequence at once. Let's make another example here: Base4 encoding.
| Binary Sequence | Base4 Encoded |
|---|---|
| 00 | A |
| 01 | B |
| 10 | C |
| 11 | D |
| 101101 | CDB |
How would our sequence of 101101 look with that algorithm? It encodes to CDB. This results in a far smaller bloat of only 400%! We continue in that manner until we have 64 distinct characters representing a specific sequence each. That's what Base64 encoding is.
| Binary Sequence | Base64 Encoded |
|---|---|
| 000000 | A |
| 000001 | B |
| ... | ... |
| 011001 | Z |
| 011010 | a |
| ... | ... |
| 101101 | t |
| ... | ... |
| 111111 | / |
In the given table, we see that our example sequence of 101101 is encoded by only using the character t. That means we only add two more bits to display 6 bits of data! That is merely an inflation of roughly 133%. Awesome! Well, but why stop there? Why did we expressly agree on “6 bits” and not use, e.g., Base128 encoding? ASCII has enough characters, right? However, 32 of them are control characters that computers may interpret. That would lead to severe bugs. Why this is exactly is out of the scope of this blog post (I mean, the Base64 algorithm already kinda is). Just so much: There is a Base91 and Base85 encoding; however, as illustrated in our examples above, “power of two” is more readily encoded when it comes to byte data, and that's why we mostly settled on that.
To summarize this a little, let's say we want to encode 10 bytes of data, which is 80 bits. That means we need 14 characters (80/6≈14) to represent that. The binary sequence 000000 is represented as ASCII A in Base64. Read this: “The binary data of my image has six consecutive zeros somewhere. The algorithm of Base64 encoding will transform this into 'A.'” In ASCII, A is eight bits long. Represented in binary, it looks like this: 01000001. Thus, we made this sequence two bits larger.
Preamble
As always, when it comes to performance, it's complex. There are a lot of layers to the question of whether to use a data URL or not. It heavily depends on how your external resources are hosted. Are they hosted on the edge? What's the latency? The same goes for the hardware of the users. How long does it take for them to decode the given data? May this take even longer than requesting the already decoded resource? You must always collect RUM data and compare approaches to know best. However, generally speaking, we could say that there is a sweet spot where the Base64 encoding overhead exceeds the overhead of an HTTP request, and thus, it's advisable not to use Data URLs.
The Premise
Let's repeat this: if the overhead of a request to an external resource exceeds the size of the Base64 extra bloat, you should use a data-url. We are not talking about the payload here. It's just what the request in isolation costs us. Do we have a bigger total size with Base64 encoding or an HTTP request? Let's make an example here. We start with a white pixel. We decode this as PNG in, well, the resolution 1x1. We will add other background colors throughout this blog post. The following table already yields the most important values: uncompressed file size as PNG, the (bloated) size when Base64 is encoded, the total request size (headers and payload), and finally, the total size of the data-URL.
| Resolution | Background Color | Size | Base64 Encoded Size | Request Size (total) | Data URL Size |
|---|---|---|---|---|---|
| 1x1 | White | 90 | 120 | 864 | 143 |
In this first example, we would need to transfer 721 (864 – 143) more bytes if we did not utilize a data URL.
Measure the Request
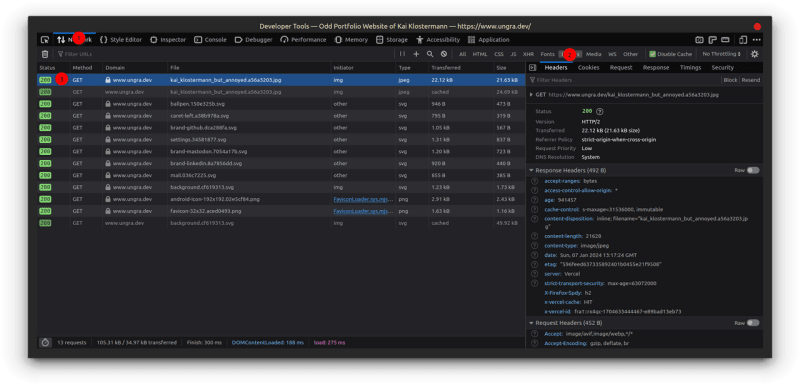
Before we head deeper into data points and their analysis, I want to clarify how we measure the total size of a request. How do we get the value in the “Request Size (total)” column? The most straightforward way is to head to the network tab in the Web Developer Tools. The first thing you do is create a snapshot of all the page's network requests. Then, find the one for the particular media in question.
{
"Status": "200OK",
"Version": "HTTP/2",
"Transferred": "22.12 kB (21.63 kB size)",
"Referrer Policy": "strict-origin-when-cross-origin",
"Request Priority": "Low",
"DNS Resolution": "System"
}
Now, you might think it's pretty easy, right? Subtract the payload (21.63 kB) from the transferred data (21.63 kB) and done. However, you also have to take the request header into account! That adds a little something.

Long story short: in the screenshot above, we see both headers, request and response. This data is the “overhead” we need to take into consideration. Everything else is payload – not bloated by Base64 encoding.
To the Lab!
Now, equipped with that knowledge and skills, we can create some data points. I did this with a Node.js script. It creates many images and writes their file sizes and Base64 encoded sizes in a CSV file:
import sharp from "sharp";
import fs from "fs";
// Create a new direcotry for that run
const nowMs = Date.now();
const outputDirectory = `./out/${nowMs}`;
fs.mkdirSync(outputDirectory);
// Create a CSV file in that directory
const csvWriter = fs.createWriteStream(`${outputDirectory}/_data.csv`, {
flags: 'a'
});
// Write the table column labels
csvWriter.write('color,resolution,fileSize,base64size \n');
// Create 700 images for each color in the given list
["white", "red", "blue", "green", "lavender"].forEach(async (color) => {
for (let index = 1; index <= 700; index++) {
const image = await createImage(color, index, index, outputDirectory);
// Write the data into CSV file
csvWriter.write(`${color},${index},${image.sizeByteLength},${image.sizeBase64} \n`);
}
});
async function createImage(color, width, height, outputDirectory) {
const imageBuffer = await sharp({
create: {
width,
height,
channels: 3,
background: color
}
}).png().toBuffer();
const fileName = `${width}x${height}.png`;
fs.writeFileSync(`${outputDirectory}/${fileName}`, imageBuffer);
return {
outputDirectory,
fileName,
// This is where we unwrap the relevant sizes and return them
sizeByteLength: imageBuffer.byteLength,
sizeBase64: imageBuffer.toString('base64url').length
}
}
Okay, this might seem a bit excessive (and it might be), but it generates 700 images with different resolutions (from 1x1 to 700x700) for five different background colors. It then writes the file size and the Base64 encoded size into a file that can be imported into a spreadsheet.
The Data
Let us analyze the data a bit, starting with the raw results. Just so that we know what we are basically looking at.
| color | resolution | fileSize | base64size | requestSize | Data-url size |
|---|---|---|---|---|---|
| blue | 1 | 90 | 120 | 864 | 143 |
| blue | 2 | 93 | 124 | 867 | 147 |
| ... | ... | ... | ... | ... | ... |
| blue | 699 | 8592 | 11456 | 9366 | 11479 |
| blue | 700 | 8606 | 11475 | 9380 | 11498 |
| green | 1 | 90 | 120 | 864 | 143 |
| green | 2 | 93 | 124 | 867 | 147 |
| ... | ... | ... | ... | ... | ... |
| lavender | 700 | 9218 | 12291 | 9992 | 12314 |
| red | 1 | 90 | 120 | 864 | 143 |
| ... | ... | ... | ... | ... | ... |
| red | 700 | 8606 | 11475 | 9380 | 11498 |
| white | 1 | 90 | 120 | 864 | 143 |
| ... | ... | ... | ... | ... | ... |
| white | 700 | 2992 | 3990 | 3766 | 4013 |
We have data points for 700 PNG images for five colors: blue, green, red, lavender, and white. The essential part is within the columns “fileSize” and “base64size”. These are the (uncompressed) file size and the size when we Base64 encode the same file. These data points are followed by columns referring to the total sizes. Column “requestSize” stands for the size of the payload plus the headers (request and response). In reality, they will differ a bit from request to request. Here, I assumed a static value of 774 bytes, more or less the median in Firefox. That's good enough for the analysis. The same goes for the data URL size. We want to add 23 bytes, as the encoded string is prefixed by data:image/png;base64,.
Findings
Interestingly, more than one data point may cross the line of 100% bloat. It's the line where the sizes would be exactly equal. That means that there may be cases where it would have been finally better not to use a data-URL, to be the other way around again right afterward.
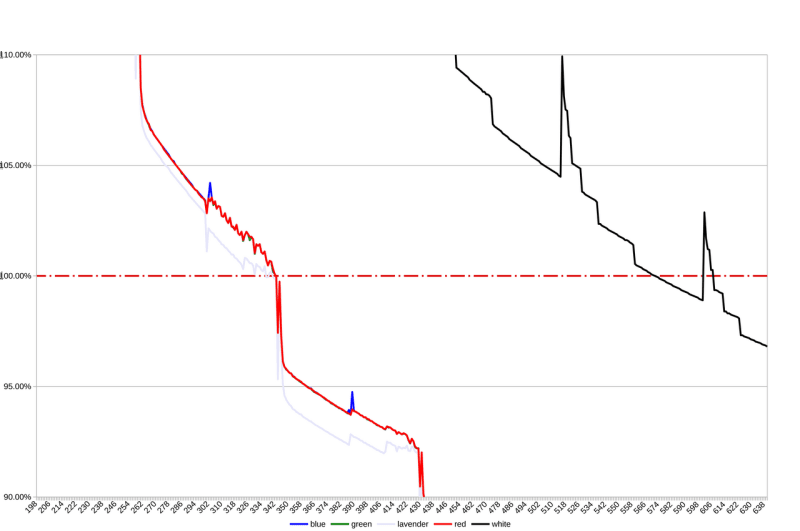
Let's understand the basic chart first. What does this mean? Simply put, for lavender, red, green, and blue, it would be preferable to use data-url up to a resolution of about 340x340. For white, you must start asking questions from a resolution of 570x570. Let's dig deeper into it. You can recognize a few things. First of all, the more complex (in our case, 'lavender') an image is, the more it gets bloated, thus reaching the point of “request preference” faster. That makes sense, as the PNG encoding needs to yield more uncompressable value. The next thing to notice is how the three base colors (Red, Green, and Blue) behave more or less identically. This makes sense because their binary data looks more or less the same. Of course, the most remarkable is the white data series. Not only is it the least complex image, thus the one that's longest in the “use data-url sector,” but it's also crossing the 100% bloat line twice! Well, the most critical data points are the ones where we cross the line of 100% bloat, right? Let's have a look at this then:
| resolution | blue | green | lavender | red | white |
|---|---|---|---|---|---|
| 337 | 0.9993 | ||||
| 339 | 1.0013 | ||||
| 341 | 0.9997 | ||||
| 343 | 0.9997 | 0.9997 | 0.9997 | ||
| 573 | 0.9997 | ||||
| 602 | 1.0287 | ||||
| 608 | 0.9936 |

Woah! Even the lavender-series does the “crossing the line twice move”! Outstanding. Okay, what do these data points mean?
- For blue, red, and green, using a data URL for resolutions up to 343x343 would be preferable
- Lavender has different sections:
- 337 and 338: A request is preferable
- 339 and 340: A data URL is preferable (again)
- 341 and bigger: A request is preferable
- As already said, white also has different sections that stretch over a greater delta:
- 573 to 601: A request is preferable
- 602 to 607: A data URL is preferable (again)
- 608 and bigger: A request is preferable
⚠️ Just a heads up again: this is merely a lab. It is there to showcase how to measure and compare your data. It is not 100% accurate for the field, as we assumed static sizes that may differ from request to request. This is especially relevant for the lavender series, where the conclusion might change from one probe to the next. Also, it would help if you did not draw general conclusions from here. Depending on the complexity and file format, the results are entirely different. See how lavender is already far more different from white. That means that the edge cases are not to be generalized.
To the Field!
Now, let's examine a real example. There is a great website hosted at https://www.ungra.dev/. We load one optimized image there. It's as good as it gets for a JPG. The image has 21.63 kB, which adds up to 22.57 kB with the header overhead.

I refrain from posting the Base64 encoded version here. It's huge. It has a solid of 28,840 characters. Thus, the Data URL is 28,2 kB large. All in all, using a Data URL would transfer 5,751 bytes more.
Now, that image is only 239 × 340 pixels large. You can see that the evaluation depends more on the complexity of the image than its sheer resolution.
File Formats
You may wonder about file formats. I tried to see how far I could go with the image in question from the previous chapter and converted it to AVIF. I compressed it – with reasonable losses - to 3,9 kB! That sounds promising to come to an even more apparent conclusion this time, right? However, the same picture also only has 5,2 kB Base64 encoded. That means that, in general terms, the question of whether to use a Data URL is not significantly impacted by the file format. It just scales the numbers.
Excurse: What's with non-binary data?
Something that is probably interesting here is what happens with non-binary data. Let's take SVGs, for example. How are they Base64 encoded, and what does that mean for our decision to put them into data URLs or not? You can, of course, Base64 encode them just as any other data. However, it generally doesn't make sense, as the original file is already available in Unicode. Remember, Base64 is a “binary to text encoding” algorithm! If you encode SVGs, you don't win anything but bloat the file.
⚠️ There are some edge cases where this might come in handy! In general terms, however, refrain from doing this.
However, you can still use Data URIs for SVGs and the like! It's just that you do not add charset=utf-8;base64 to it. It's merely data:image/svg+xml;utf8,<SVG>.... Remember that such a URL does not need to be Base64 encoded. We need this extra step to render binary data.
Draw a Conclusion
Now that you know how to get the relevant numbers, it's relatively easy to conclude. Again, you must compare the request overhead with the increased file size of the Base64 encoded media. Is the request header size, response header size, and payload bigger than the Base64 data URL string? If yes, use the latter. If not, make a request.
Other Considerations
In reality, you have to take a few more considerations into account. However, as they are very individual for particular scenarios or concern other “layers,” I will only briefly mention them here.
Media Processing
First, if your media is not hosted on the edge, the latency increase may not be worth it. Also, the other way around: if your web app runs on really (!) poor hardware, it might not be worth using a data-url.
Compare Zipped Data
Your data should be compressed. If you haven't done so yet, do it now (there is a big chance you do this already, as it's pretty much the default for most hosters/servers/...). This also means that we need to compare the compressed data here. (What we didn't do throughout this post to keep things simple.) The same goes for optimizing your resources first. For images, compress them as much as possible and use modern file formats like AVIF or WebP. SVGs should also be minimized with tools like OMGSVG.
HTTP/2 and Server Push
With HTTP/2, a concept called server push makes data URLs nearly obsolete! A server can provide the resources we have encoded inline in one go. Read more about that here: https://web.dev/performance-http2/#server-push.
Unfortunately, server push is mainly abandoned and deprecated nowadays. Even to an extent where I can say ignore it. If you want to read more about the why, head to this article: https://developer.chrome.com/blog/removing-push/.
Conclusion
Data URIs are primarily used with binary data encoded with an algorithm called Base64. It is made to display binary data in a text-based way. This is excellent for Data URIs, for they are text-based! However, Base64 makes the data larger. That means you must check whether it's better to have overhead with the request or to bloat your file.
Further Reading
- https://www.smashingmagazine.com/2017/04/guide-http2-server-push/
- https://www.davidbcalhoun.com/2011/when-to-base64-encode-images-and-when-not-to/
- https://developer.mozilla.org/en-US/docs/web/http/basics_of_http/data_urls
- https://web.dev/performance-http2/
- https://www.rfc-editor.org/rfc/rfc2397#section-2
- https://developer.mozilla.org/en-US/docs/Glossary/Base64
- https://css-tricks.com/probably-dont-base64-svg/
- https://css-tricks.com/lodge/svg/09-svg-data-uris/
- https://developer.chrome.com/blog/removing-push/





Top comments (0)