
Hello, my name is Dmitry Karlovsky and I, as a sculptor, cut off everything superfluous to leave only the pulp, which in the most concise and practical form solves a wide range of problems. Here are just a few of the things I've designed:
- MarkedText - a slender, lightweight markup language (the MarkDown killer).
- Tree - a structured data representation format (the killer of JSON and XML).
This time we'll design a user-friendly client-server API designed to remove the bloodshot eyes of front-enders and steel calluses from the fingers of back-enders...
| HARP | OData | JSON:API | GraphQL | |
|---|---|---|---|---|
| Architecture | ✅ REST | ✅ REST | ✅ REST | ❌ RPC |
| Common uri query string compatible | ⭕ Back | ✅ Full | ✅ Full | ❌ |
| Single line query | ✅ | ✅ | ✅ | ❌ |
| Pseudo-static compatible | ⭕ Back | ⭕ Partial | ✅ Full | ❌ |
| Same model of request and response | ✅ | ✅ | ❌ | ❌ |
| File name compatible | ✅ | ❌ | ❌ | ❌ |
| Web Tools Friendly | ✅ | ❌ | ✅ | ❌ |
| Data filtering | ✅ | ✅ | ⭕ Unspec | ⭕ Unspec |
| Limited fetch logic | ✅ | ❌ | ⭕ Unspec | ✅ |
| Data sorting | ✅ | ✅ | ✅ | ⭕ Unspec |
| Data slicing | ✅ | ✅ | ✅ | ⭕ Unspec |
| Data aggregation | ✅ | ✅ | ⭕ Unspec | ⭕ Unspec |
| Partial fetch | ✅ | ✅ | ⭕ Per Type | ✅ |
| Deep fetch | ✅ | ✅ | ✅ | ✅ |
| Metadata query | ✅ | ✅ | ✅ | ✅ |
| Idempotent requests | ✅ Full | ⭕ Partial | ⭕ Partial | ❌ Undef |
| Normalized response | ✅ | ❌ | ✅ 2 Buckets | ❌ |
| Static typing frienly | ✅ | ✅ | ❌ | ✅ |
Application Programming Interface
Architecturally, there are three main approaches: RPC, REST and synchronization protocols. Let's take a closer look.
Remote Procedure Call
Here we first choose which procedure to call. Then we pass its name and arguments to the server. The server executes it and returns the result.
Known examples of RPC protocols:
A common feature of such protocols is a huge number of procedures with unique signatures, each of which needs documentation and support in the code (example). As a consequence, such protocols are very difficult to support and using them requires a lot of documentation.
Another feature is the inability to cache proxy requests because they have no information about what can be cached and how.
REpresentational State Transfer
The idea here is to allocate objects to interact with (resources), standardize their identifiers (URI) and procedures to interact with them (methods). The number of resource types is thus several times less than the number of procedures in the case of RPC, which is much easier to use by humans.
Known examples of REST protocols:
Since the number of REST methods is very limited and each has clear semantics, it becomes quite easy to write applications that can work with any (even previously unknown) resources (example), understanding how to read, update, cache, etc.
Synchronization protocols
There are no methods at all at the protocol level, and the network nodes simply exchange deltas of locally made changes. These types of protocols are characteristic of decentralized systems that support off-line operations. I don't know of any known representatives of this type of protocol. But I'm currently developing one of them, which will soon turn the world upside down. But for now we'll settle on something more traditional - REST...
Architecture
Before we get into the details of the protocol, let's define the architectural constraints that we will be focusing on...
Pseudo-Static
It is important to note that REST is not about URIs like file paths at all:
/users/jin/chats/123/messages/456/likes.json
/organizations/hyoo/chats/123/messages/456/likes.json
hese two links actually refer to the same resource. That is, the first problem with them is choosing the canonical link from a variety of options.
Another problem is that we need to know information about the whole path, which we may not have. For example, we have a post ID, but we can't get its likes because we don't know the chat and organization IDs.
The next problem is size bloat due to redundant information, which leads to either transferring a few lines in random places, or cutting it off altogether.
Finally, when transferring the chat, for example, to another organization, the links to all the messages will suddenly change, and the user coming to the old links will often see a mockingly beautiful page 404. Unless, of course, the developer seriously bothered with redirects.
In summary: URI should contain only the minimum necessary information to identify the resource itself, but not its position in a hierarchy.
Create Read Update Delete
It is equally important to note that REST is not only and not so much about CRUD, despite the fact that CRUD is well expressed through basic HTTP methods:
-
Create-POST -
Read-GET -
Update-PUT/PATCH -
Delete-DELETE
CRUD, however, has a number of significant drawbacks...
Creating a resource is not idempotent. If our request to call a cab gets lost half way through, trying to repeat it may lead to multiple cabs coming at once. In addition, before the resource is created, it does not have an identifier that is necessary for the UI to work adequately, forcing the client to insert crutches with assigning temporary identifiers, and then replacing them with permanent ones after the resource is created. In view of all this, it is preferable to form a globally unique identifier still on the client side, and to create the resource on the server on the fly, when the client sends its updates for the yet uncreated resource.
Deleting a resource violates referential integrity. And while we can update or delete all the links within our system, external systems will continue to refer to nowhere. Therefore, it is preferable not to remove resources completely, but only mark them as hidden.
Thus only two HTTP methods will suffice for our protocol:
-
GETfor reading. -
PATCHfor updating.
It is important to note that the resource can be quite large, so both partial read (fetch plan) and partial update (PATCH but not PUT) mechanisms are important.
Real Time
The request/response approach of HTTP is ill-suited for modern applications that need to respond in real time to changes without overwhelming the server with "did anything change?" type requests. For those applications you need a two-way WebSocket connection. You can use it to make HTTP requests without repeating the same logic twice:
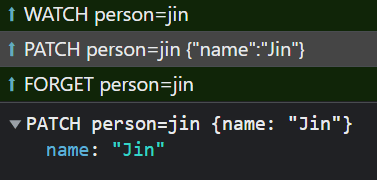
In addition to the standard GET and PATCH, there are a couple of other methods you should support when connecting via WebSocket:
-
WATCH- this is the same asGET, but additionally subscribes the client to resource updates. -
FORGET- simply unsubscribes from updates.
Keys
When choosing how to identify an entity, two main approaches can be distinguished:
- Natural key, which is formed from the properties of the entity. But it is not effective, does not guarantee uniqueness and can dynamically change, which creates many problems.
- Суррогатный ключ, генерирующийся автоматически. It is efficient, immutable and guaranteed to be unique.
The key property here is immutability. Identifier must not change with time, otherwise it is difficult to call it an identifier. That's why we can use any unchanged key. And often a natural unchanging key simply can't be invented. Therefore, as a rule, it should be a surrogate one.
Model
As a rule, an application domain is a graph, where the nodes are several dozens of entity types and the edges are several hundred types of relations between them.
Some of these entities and relations are explicitly represented in the database, which is typical for graph DBMS edges. Some of them are implicit, which is characteristic of relations in relational databases. And some of them may be virtual, computable on the fly.
By the way, I have a couple of interesting articles on graph DBMSs:
- Isn't it time for relational databases to go to the dustbin of history?
- Sawing a product catalog without touching relational algebra
A good practice is to abstract the API from the details of storage and internal data representation. This allows you to change the internals without changing the external contract, and not complicate it with low-level details.
So, let's describe the most simple but flexible model:
-
Entityis a document storing various data. - Type` - entity type, which defines what kind of properties it has and what type they are.
-
ID- an entity surrogate identifier, unique within its type. -
URI- an entity identifier unique within the framework of the whole API, which is a reference to the underlying URI API. - Entities can contain URIs of other entities as property values, which allows them to form a graph.
Fetch Plan
Often when implementing the REST API, the resource is returned in its entirety. A good anti example is search via GitHub API, which output can easily weigh one and a half megabytes instead of required for menu display couple of kilobytes. This is a common problem, called overfetch.
If some responses return the resource in an abbreviated form, in some cases this will lead to the need to query the full resource representation for the sake of the one missing field. In the GitHub search example, the user data is returned in abbreviated form. This means that if you want to show a list of member organizations next to the user, you'll have to make N more queries for all user data. This is no less a typical problem, called underfetch.
You can also notice here that if the same user occurs in several places, the same user data is duplicated many times. There was a curious case in my practice with task manager, where each task was located in several folders, those in several other folders, and so on to the root. And when the application on startup was querying the folder tree, it would get a response of tens of kilobytes of data instead of tens of megabytes. This not only overloaded the server and network, but Internet Explorer crashed when trying to parse such a big JSON.
This last problem is a consequence of denormalizing data which is not inherently tree. What made this situation especially piquant was that the server received data from the database in a normal form, but denormalized it for delivery to the client. And the client received the data in a denormalized form, and did the reverse normalization to get rid of the duplicates.
This is partly why GitHub eventually switched to the more fashionable GraphGL, which solves the first two problems, but not the last. We, on the other hand, will solve them all. Which means we need the following:
- Partial Fetch - specifying in the request which fields are to be fetched.
- Recursive Fetch - if a field contains a link to another resource, you should specify in your query which of its properties you want to fetch.
- Filtered Fetch - specifying limitations both for direct fetch and for recursively loaded collections.
- Normalized Output - returning in the response a small slice of the graph in a normal form without duplication.
Query
So, getting to the point, it's time to develop a query language for the graph within the REST architecture...
Applications
First of all we have to decide where and how queries will be used:
- The URI is written in the application code as a literal.
- Special DSL generates URI with dynamic data substitution.
- The developer can open URI in a browser to see what the server returns.
- In the client's network log, the developer can find the request of interest to see the details.
- In the server's network log, too, requests are often output on a single line with minimal details.
- The output can be saved as a file. It is a good idea to have the request itself as its name.
- The same format can be used for page addresses for users.
- The URI can be sent in chat, comments, social network, etc.
- The URI can be output in XML including a node identifier.
Special Symbols
Since a query may contain custom data, you have to escape all special characters in it. The URL format already has a number of standard wildcards supported by any tool:
: @ / $ + ; , ? & = #
They are escaped when using encodURIComponent, but not when using encodeURI, which means that with these characters we definitely will not get an unexpected escape. However, there are still problems with some of them:
-
: / ?- not allowed in file names. -
:- not allowed at the beginning of the URL path. -
/- a number of tools shows only the last segment of the path after it, which is sometimes not informative. -
? #- a number of tools screens multiple occurrences of these characters in the URL. -
#- all that after this symbol, the browser to the server does not pass. -
&- requires a clumsy escape in XML:&.
Thus, the number of allowed special characters is reduced to:
@ $ + ; , =
Since we need to make deep samples, we need some form of brackets. However, these symbols do not fit the role of brackets at all. Let's analyze what kinds of parentheses there are:
-
()- are not escaped in user data by standard tools (encodeURIComponent), so they do not fit at all. -
<>- are escaped when displayed in Chrome Dev Tools, which dramatically reduces visibility. Not acceptable in file names. Requires clumsy XML escaping. -
{}- are escaped when used before?in Chrome, but if you place the query after?, all is fine. -
[]- is not escaped either in browsers address bar or in their query logs. That's great!
So let's add square brackets to the allowed set of wildcards:
@ $ + ; , = [ ]
Special mention should be made of the characters that are not escaped in the user data:
~ ! * ( ) _ - ' .
It is acceptable to use them, but only in places where there can be no user data syntactically. It is also better not to use such symbols right next to them, so that they do not visually merge.
Syntax
Because a query can be quite complex, but is a single line, it is extremely important to keep the syntax as compact as possible. But not at the expense of clarity, of course.
To fully identify an entity we need to specify its type and identifier. Nothing is more natural than connecting them with =:
As you can see, this is not the full URI, but its abbreviated form. If the base API URI is https://example.org/, then the full entity URI is this:
https://example.org/person=jin
Now, if we get for example article=123 in the output of this link, then this URI will also be correctly detected:
https://example.org/article=123
Relative URIs are good not only because they are short, but also because we can work with the same graph through different API Enpoints, which is very useful, for example, when moving the API.
What if we don't need just one user, but all of them? We just remove the ID and get the whole collection:
Yes, in general, the name is not the type, but the name of a collection or field. Let's use ; to select several collections at once:
It is important to note that this query will only return lists of entity identifiers, not entity data. So let's use parentheses to specify which fields we want to see in the response:
The brackets can be used recursively to make deep selections:
Here we have selected the names and ages of a particular user and all his friends.
The predicate after the name is generally not an ID, but an arbitrary filter. It is simply interpreted as an ID filter for entities. For example, let's not load all users, but only girls:
Here it is important to note that filtering by any field usually involves loading that field. So for each girl, not only her name and phone number, but also her gender will be output. This may seem redundant in this example. But only until we find out that under female can also hide trap, and it would be nice to recognize this by the output. So it is better for the client not to hypothesize about the actual values of the fields, but just get them from the server.
The predicate can be either positive or negative. So let's leave it to unmarried girls using !=:
Not only a specific value but also a range can be specified as a value using @. Ranges can be of the following kinds:
- Closed with a lower boundary:
lo@ - Closed with an upper boundary:
@hi - Closed with both boundaries:
lo@hi - Closed with matching boundaries:
val@valor justval
Yes, any single value is actually a range. Let us clarify that we are only interested in adult girls:
And the range may be not one, but several, separated by ,. So let us add that engaged girls do not interest us either:
person[name;phone;sex=female;status!=married,engaged;age=18@]
We can sort the output immediately by the loaded fields, using the prefix + to sort in ascending order and - to sort in descending order. As an example, let's display young girls, with the maximum number of talents, at the beginning:
person[name;phone;sex=female;status!=married,engaged;-skills;+age=18@]
The priority of field sorting is determined by their location in the query. First come, first served.
As with filters, sorting also results in automatic loading of relevant fields, which keeps URIs short.
Each entity has generalized fields, starting with , through which you can, for example, get aggregated information instead of detailed information. If instead of a numeric field with the number of talents, we only have a field with links to the entities describing the talents, but we do not want to load them all, we can simply get their number using the function _len:
person[name;phone;sex=female;status!=married,engaged;-_len[skill];+age=18@]
The aggregation function passes not just the name of the field, but a subquery whose output size will be returned for each girl. For example, let's specify that we are only interested in child-rearing talents:
person[name;phone;sex=female;status!=married,engaged;-_len[skill[kind=kids]];+age=18@]
Other aggregation functions: _sum, _min, _max. And this list will be expanded. Each function itself determines how many and what parameters to pass to it.
If we want to get not the whole list, but, for example, only the first 20, we can use another generalized field - _num, which contains the number of the entity in a particular list (the number itself is not returned):
person[_num=0@20;name;phone;sex=female;status!=married,engaged;-_len[skill[kind=kids]];+age=18@]
This is the whole query language. As you can see, a very short query allows us to specify quite precisely what we want. If you recognize yourself in the last URI - urgently email me telegrams. And with those who are left we go on.
Back Compatibility
The symbol ; for the separation of parameters is chosen for reasons of readability and universality. However, it is not hard to notice that if the parser also supports &, it can be used for the usual QueryString. This allows, smoothly migrate from QueryString to HARP:
But that's not all; by adding / with the same semantics, we can parse pathname as well:
And by adding ? and #, we can combine all this:
TypeScript API
String representation of queries is convenient when you work with them manually. But when you need to form them programmatically by substituting dynamic values, working with strings is not so cool. That's why I've implemented a couple of functions:
- $hyoo_harp_from_string - parses HARP Query into JSON
- $hyoo_harp_to_string - Builds HARP Query from JSON
They are used as follows:
const harp = $hyoo_harp_from_string( 'person[+age=18@;+name;article[title];_num=20@29]' )
// {
// person: {
// age: {
// '+': true,
// '=': [[ '18', '' ]],
// },
// name: {
// '+': true,
// },
// article: {
// title: {},
// },
// _num: {
// '=': [[ '20', '29' ]],
// },
// },
// }
const ADULT = [ 18, '' ]
const page = 2
const nums = [ page * 10, ( page + 1 ) * 10 - 1 ]
const uri = $hyoo_harp_to_string({
person: {
age: {
'+': true,
'=': [ ADULT ],
},
name: {
'+': true,
},
article: {
title: {},
},
_num: {
'=': [ nums ],
},
},
})
// person[+age=18@;+name;article[title];_num=20@29]
These functions are poorly typed. In the sense that they don't know anything about graph structure. But we can declare a schema using, for example, $hyoo_harp_scheme based on $mol_data:
const Str = $mol_data_optional( $hyoo_harp_scheme( {}, String ) )
const Int = $mol_data_optional( $hyoo_harp_scheme( {}, Number ) )
const Article = $hyoo_harp_scheme({
title: Str,
content: Int,
})
const Person = $hyoo_harp_scheme({
name: Str,
age: Int,
article: $mol_data_optional( Article ),
})
Now we can collect URIs and thecape checker will make sure we don't get the names wrong anywhere, and will even prompt us as we type:
// person[name;age;article[title]]
const query = Person.build({
person: {
name: {},
age: {},
article: {
title: {},
},
},
})
And vice versa, we can easily decompress the URI received from the client to get a strictly typed JSON:
const query = Person.parse( 'person[+age=18@;+name;article[title];_num=20@29]' )
const article_fetch1 = Object.keys( query.person.article ) // ❌ article may be absent
const article_fetch2 = Object.keys( query.person.article ?? {} ) // ✅
const follower_fetch = Object.keys( query.follower ?? {} ) // ❌ Person don't have follower
Finally, even if we already have some sort of JSON representation of the query, we can static-dynamically fail it:
const person1 = Person({}) // ✅
const person2 = Person({ name: {} }) // ✅
const person3 = Person({ title: {} }) // ❌ compile-time error: Person don't have title
const person4 = Person({ _num: [[ Math.PI ]] }) // ❌ run-time error: isn't integer
const person5: typeof Person.Value = person2 // ✅ same type
It remains to learn how to generate a TS schema from its declarative description, so that we do not have to re-describe it for each language separately.
Response
Since the model of the application area is a graph, and in the response we need to return its subgraph, we need the ability to represent the graph as a tree without duplication. For this we divide the graph representation into 4 levels:
-
Type- Defines the types of the entities stored in them. This is important for languages with static typing, so that appropriate data structures are used to handle the response. -
ID- Identifies the entity within the type. -
Field- Entity field name. -
Value- The value of the field, the type of which is defined by the schema and field name.
The values can be URIs of other entities. URIs are URIs, not IDs, because in general there may be different types of entities mixed up in one list.
Also, besides the response data itself, it makes sense to return the query (_query) as it was understood by the server, so that the client developer can understand if he is doing everything right, and who to fix the problem when something is wrong.
Finally, when getting any field of any entity, an exceptional situation can happen. It wouldn't be practical to return an error for the whole entity, much less the whole request. Therefore, it would not be practical to use HTTP codes to express errors in the response. And you should be prepared that at any level, instead of the data itself, an error description (_error) may come.
Format
Different clients may be comfortable working with different data presentation formats, so using Content Negotiation let him choose one of the following:
-
JSON:
Accept: application/json(the most popular) -
Tree:
Accept: application/x-harp.tree(most obvious) -
XML:
Accept: application/xml(default)
Let's analyze them in detail using the following query as an example:
person[name;age;article[title;author[name;_len[follower[vip=true]]]]];me
JSON
Let's start with the most popular format now, for better understanding:
{
"_query": {
"person[name;age;article[title;author[name;_len[follower[vip=true]]]]]": {
"reply": [
"person=jin",
],
},
"me": {
"reply": [
"person=jin",
],
},
},
"person": {
"jin": {
"name": "Jin",
"age": { "_error": "Access Denied" },
"article": [
"article=123",
"article=456",
],
"_len": {
"follower[vip=true]": 100500,
},
}
},
"article": {
"123": {
"title": "HARP",
"author": [
"person=jin",
],
},
"456": { "_error": "Corrupted Database" },
},
}
JSON, however, has many disadvantages, such as:
- Multiline text is pulled into a single line.
- Lots of visual noise.
- Either weighs a lot, or is stretched to a single line.
So I would recommend using the following format whenever possible...
Tree
_query
\person[name;age;article[title;author[name;_len[follower[vip=true]]]]]
reply \person=jin
\me
reply \person=jin
person
\jin
name \Jin
age _error \Access Denied
article
\article=123
\article=456
_len
\follower[vip=true]
100500
article
\123
title \HARP
author \person=jin
\456
_error \Corrupted Database
As you can see, the output is more compact and less noisy in this form. However, it is still preferable to use the following format by default, because of one of its unique features...
XML
<?xml-stylesheet type="text/xsl" href="_harp.xsl"?>
<harp>
<_query id="person[name;age;article[title;author[name;_len[follower[vip=true]]]]]">
<reply>person=jin</reply>
</_query>
<_query id="me">
<reply>person=jin</reply>
</_query>
<person id="person=jin">
<name>Jin</name>
<age _error="Access Denied" />
<article>article=123</article>
<article>article=456</article>
<_len id="person=jin/follower[vip=true]">100500</_len>
</person>
<article id="article=123">
<title>HARP</title>
<author>person=jin</author>
</article>
<article id="article=456" _error="Corrupted Database" />
</harp>
Pay attention to the inclusion of the XSL template at the beginning. It is needed so that when you open the URI in the browser you will not see a blank XML or JSON dump, but a nice HTML page with icons, buttons and working hyperlinks. This makes the URI completely self-sufficient: you don't need to look somewhere for the actual documentation - it is available exactly where the data itself is, which you can easily navigate back and forth (HATEOAS on maxims).
Here I made a small example, but you can do much, much better! At the very least, what I'd like to see:
- Fast switching between presentation options (UI, Tree, JSON, XML).
- All URIs are hyperlinks.
- Full-text search of the output.
- Tree view with collapsing and expanding.
- Tabular presentation of entities of the same type.
- Buttons for quick modification of a query (e.g. adding a field to a query with a single click).
- Entity and field descriptions taken from the schema.
Create & Update
Updating resources is easy: we send what we get from and where we get it. It makes sense to send only the fields you want to change, not all of them. All entity updates we send are applied to a single transaction, so the request either passes or fails. The URI, on the other hand, specifies what the request should return.
For example, let's send some donations to the author of this opus, and get actual data on both users at once:
PATCH /person=jin,john[ballance;transfer]
transfer
\12345
from \john
to \jin
amount 9000
And if successful, there will be such an answer:
person
\jin
ballance 100500
transfer
\transfer=34567
\transfer=12345
\john
ballance -100500
transfer
\transfer=23456
\transfer=12345
Or let's create a message with a ballot in one transaction:
PATCH /
message
\12345
chat \123
body \Do you like HARP?
attachment \poll=67890
poll
\67890
option
\Yes
\No
\There is no third way
And the response will be blank because we have not asked for anything here.
Comparison
Well, let's now compare our humane protocol with the closest alternatives...
Architecture
| HARP | OData | GraphQL | |
|---|---|---|---|
| Architecture | ✅REST | ✅REST | ❌RPC |
REST architecture is preferable. It is not for nothing that HTTP was once developed for it.
Common Query String
| HARP | OData | GraphQL | |
|---|---|---|---|
| Common uri query string compatibile | ⭕Back | ✅Full | ❌ |
HARP is backwards compatible with the traditional HTTP request representation. OData, on the other hand, is fully compatible, but at what cost.
You just compare the OData request:
GET /pullRequest?$filter=state%20eq%20closed%20or%20state%20eq%20merged&$orderby=repository%20asc%2CupdateTime%20desc&$select=state%2Crepository%2Fname%2Crepository%2Fprivate%2Crepository%2Fowner%2Fname%2CupdateTime
%2Cauthor%2Fname&$skip=20&$top=10&$format=json
And the equivalent HARP query:
GET /pullRequest[state=closed,merged;+repository[name;private;owner[name]];-updateTime;author[name];_num=20@30]
GraphQL, on the other hand, is not compatible at all, unless, of course, you consider the whole query in one get-parameter to be compatible.
Single Line
| HARP | OData | GraphQL | |
|---|---|---|---|
| Single line query | ✅ | ✅ | ❌ |
GraphQL, of course, can also be packaged in one line, but then it is extremely difficult to read:
GET /graphq?query=%7B%20request%20%7B%20pullRequests(%20state%3A%20%5B%20closed%2C%20merged%20%5D%2C%20order%3A%20%7B%20repository%3A%20asc%2C%20updateTime%3A%20desc%20%7D%2C%20offset%3A%2020%2C%20limit%3A%2010%20)%20%7B%20id%20state%20updateTime%20repository%20%7B%20name%20private%20owner%20%7B%20id%20name%20%7D%20%7D%20updateTime%20author%20%7B%20id%20name%20%7D%20%7D%20%7D%20%7D
Yet it is focused on a two-dimensional representation and nothing else:
POST /graphql
{
request {
pullRequests(
state: [ closed, merged ],
order: { repository: asc, updateTime: desc },
offset: 20,
limit: 10,
) {
id
state
updateTime
repository {
name
private
owner {
id
name
}
}
updateTime
author {
id
name
}
}
}
}
Pseudo Static
| HARP | OData | GraphQL | |
|---|---|---|---|
| Pseudo-static compatibile | ⭕Back | ⭕Partial | ❌ |
HARP is backward compatible. In OData, paths are used to identify resources:
/service/Categories(ID=1)/Products(ID=1)
GraphQL has nothing to do with it.
Request vs Response
| HARP | OData | GraphQL | |
|---|---|---|---|
| Same model of request and response | ✅ | ✅ | ❌ |
With REST protocols it is enough to understand the domain model and you already have all the features. In the case of RPC, in addition to the response model, you also need to know a bunch of procedure signatures, and constantly ask for new ones from the backenders. And in case of GraphQL you also need to know and maintain a separate query model.
File Names
| HARP | OData | GraphQL | |
|---|---|---|---|
| File name compatible | ✅ | ❌ | ❌ |
Not that everyone needs the ability to insert queries into filenames, but in some cases, it makes life a lot easier and comes at no cost.
cp ./report[day=2022-02-22].json ./archive/year=2022
Web Tools
| HARP | OData | GraphQL | |
|---|---|---|---|
| Web Tools Friendly | ✅ | ❌ | ❌ |
Being able to not break your eyes over the shielding in different places using URI saves not a lot of time and nerves, but does it often.
Collection Manipulations
| HARP | OData | GraphQL | |
|---|---|---|---|
| Data filtering | ✅ | ✅ | ❌ |
| Data sorting | ✅ | ✅ | ❌ |
| Data slicing | ✅ | ✅ | ❌ |
| Data aggregation | ✅ | ✅ | ❌ |
It's not that GraphQL doesn't express it. Somehow it is used. It is important to understand that these features are not specified at the protocol level and each developer implements them in his own way. This complicates the creation of generalized software solutions that can work with collections. However, this issue can be solved by higher level protocols over GraphQL.
Limitations
| HARP | OData | GraphQL | |
|---|---|---|---|
| Limited filtering logic | ✅ | ❌ | ✅ |
When flexibility is lacking, we cannot properly express our needs. When there is too much flexibility, it is difficult for the server to analyze the complexity of the request. Therefore, there is an important balance: queries should be simple enough for programmatic analysis, but expressive enough to cover 99% of needs. OData, on the other hand, implemented an entire programming language with its own unique syntax:
contains(User/Name, '(aTeam)') and (User/Articles add User/Comments) ge 10
Sure, it's cool, but go figure it out: can I give this query to DBMS, or it will put it on its back, and then fix it for me at 2 a.m.?
Metadata
| HARP | OData | GraphQL | |
|---|---|---|---|
| Metadata query | ✅ | ✅ | ✅ |
It's cool when we can programmatically explore a real working API instead of manually poking around in outdated documentation. This allows us to write generalized code to work with any API that implements the protocol. For each entity, we can ask the API a lot of interesting things:
- Linked entities.
- Data schema.
- Rights to actions.
- Documentation.
In HARP we have almost no work on this yet. Except that in that example I sketched out what it might look like. The other protocols only provide some of the listed meta information. So far, this issue is most elaborated in OData.
Idempotency
| HARP | OData | GraphQL | |
|---|---|---|---|
| Idempotent requests | ✅ | ⭕ | ❌ |
HARP takes the idea of idempotency to an absolute. OData takes a more traditional approach with CRUD. And GraphQL is not about idempotency at all. The industry has taken a wrong turn somewhere. Again.
Normal Form
| HARP | OData | GraphQL | |
|---|---|---|---|
| Normalized response | ✅ | ❌ | ❌ |
Denormalized output can exponentially multiply your data. It's easier to see it once than to hear it 100 times. So let's take an uncomplicated GraphQL query for friends of friends:
{
person('jin') {
id
name
friends {
id
name
friends {
id
name
}
}
}
}
And that's what we get:
{
"person": {
"id": "jin",
"name": "Jin",
"friends": [
{
"id": "alice",
"name": "Alice",
"friends": [
{
"id": "bob",
"name": "Bob",
},
{
"id": "jin",
"name": "Jin",
},
],
},
{
"id": "bob",
"name": "Bob",
"friends": [
{
"id": "alice",
"name": "Alice",
},
{
"id": "jin",
"name": "Jin",
},
],
},
],
}
}
And that's just on three drinking buddies. What will happen to a school class of 20 people, I will not show you, so as not to overload the main communication channels.
In spite of its name, GraphQL data model is not actually a graph, but a dynamic tree. With all the implications that comes with it.
A big corporation publicized their crooked product, and everyone ate it up. And, smacking their lips, they started sawing crutches, telling the others how to cook it properly:
- The server got the data from the database in a normal form.
- Denormalized them for GQL output.
- Put a deduplicator, getting their own non-GQL format.
- Sent it to the client.
- On the client we drew the redundancy checker to get a GQL answer.
- Then we processed the GQL response.
- And the client reacts to this denormalization like a bone in the throat - he normalizes everything back.
The industry took a wrong turn somewhere. Again.
And this is what we get with HARP:
_query
\person=jin[name;friend[name;friend[name]]]
reply \person=jin
person
\jin
name \Jin
friend
\person=alice
\person=bob
\alice
name \Alice
friend
\person=bob
\person=jin
\bob
name \Bob
friend
\person=alice
\person=jin
Yes, when they send you the response dumps, you will no longer have to ask, "What was the request? It's right there in the response.
Post Scriptum
As you can see, this isn't really a specification, or even a complete solution. It's not my goal to convince you to follow my decisions and immediately increment the version of your API.
In my business I used a lot of APIs, and every time I used them I got discouraged by the childhood diseases, the rakes laid out here and there, and just thoughtlessly copying each other's crooked solutions. So it was important for me to share with you my pain and ideas, which I'm sure will be useful for you to design your own APIs. And if it will be something similar to HARP - I'll be only happy.
If you are interested in HARP ideas and you see its usefulness for you and for others, then I invite you to join discussion of it and bring it up to industry standard. I can't do it alone, but together we can make the world a little better. Although, frankly speaking, I bet more on the third type of architecture - conflict-free synchronization of locally made changes. But that's a whole other story, which you'll definitely hear about soon. In the meantime.
- Discuss this and other languages with me in the lang_idioms chatroom.
- Discuss TS API in mam_mol.
- I post my thoughts on various computer science topics at Core Dump.
- Almost all my articles are available at $hyoo_habhub.
- Private recordings of almost all of my performances are merged into this playlist.
- I write the rest of the crap about development on Twitter.
- Thank me for my research and motivate me for new achievements at Boosty.
Thank you for your attention. Keep your heart hot and your ass cold!





Top comments (0)